



走向世界的中国开源模型
整整一个月了!
中国AI模型,在全球引发持续热议。除了备受瞩目的DeepSeek外,更多中国AI开源模型正在走向国际舞台。
比如,早于DeepSeek-R1模型4天发布的MiniMax-01模型,因为开源+新架构,1月份在海外技术圈引发持续震动。不仅获得了海外科技媒体、AI专家和从业者的高度评价,更被誉为能与OpenAI“一较高下”的顶尖模型。

不仅如此,MiniMax的视频模型“海螺AI”,也早在去年Q4就已在海外市场大放异彩。

详见我们之前的文章:你不会还没用过海螺AI吧?
这家低调却实力非凡的AI公司,究竟有何来头?最近,我在大量读了他们的技术论文和创始人访谈后,终于找到了MiniMax爆火海外的原因。

全新架构,顶尖模型
在年初,MiniMax一口气发布了多个AI模型,将自己的技术家底大方展示。而且,跟DeepSeek一样,也是直接开源。
1)开源MiniMax-01模型
1月15日,MiniMax发布了全新架构的MiniMax-01系列模型,并首次开源。01系列模型包含两个模型——基础语言大模型MiniMax-Text-01和视觉多模态大模型MiniMax-VL-01。

01模型采用了全新架构,首次实现了大规模的线性注意力机制,而非传统的Transformer架构。在多项基准测试上,追平了海外公认最先进的两个模型,GPT-4o-1120以及Claude-3.5-Sonnet-1022。

受益于全新架构,模型在长文处理领域有着非常高的效率,能够高效处理全球最长400万token的上下文,是GPT-4o的32倍,Claude-3.5-Sonnet的20倍。
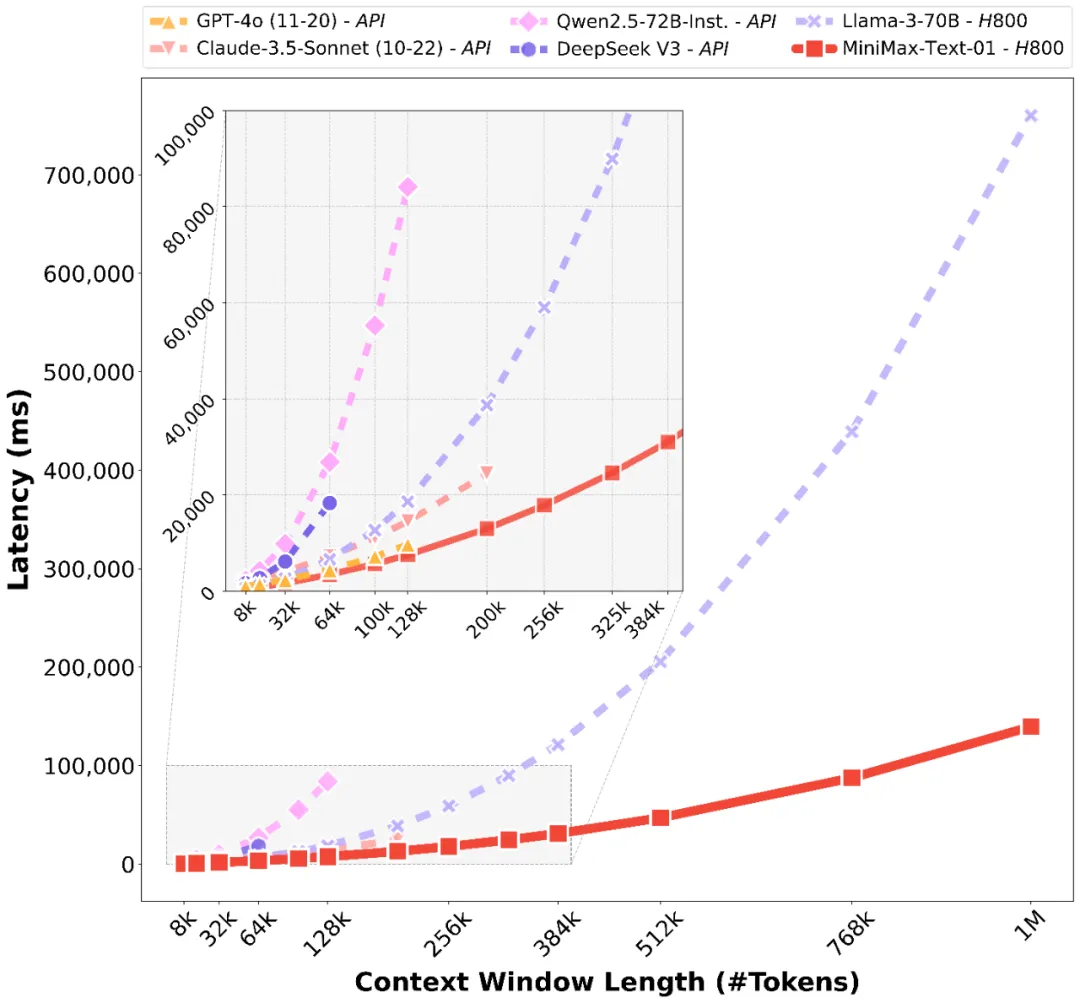
值得一提的是,这周DeepSeek和Kimi都不约而同地发新论文,聚焦长文注意力机制。而MiniMax早在1个月前就已将这个新架构落地到了01模型中。
技术文档:
https://www.minimaxi.com/news/minimax-01-系列
对于该模型,MiniMax介绍是一个“开启Agent时代的新架构模型”。这里有两层意思,一是架构,二是能力。

架构,采用了新的线性注意力机制,可以高效、快速地处理非常长的context(上下文)。
能力,可以处理复杂任务,它可以是o1这样单次输出多步,也可以通过一个单Agent拆成多步,还可以像Anthropic定义的workflow那样——更复杂的多Agent间的协同。
MiniMax-01模型,目前已全量上线海螺AI,所有人可以免费体验。
体验地址:https://hailuoai.com
2)发布S2V-01视频模型
1月10日,MiniMax发布S2V-01模型,只需要一张图片,即可参考主体生视频,不需要额外的LoRA,也没有额外的训练成本。
体验链接:hailuoai.com/video/create
2024年12月,MiniMax推出的图生视频模型I2V-01-Live,海外访问量已超2700万,突破历史新高并登顶12月全球AI视频产品榜首。

3)发布T2A-01语音模型
1月17日,MiniMax发布T2A-01-HD、T2A-01-Turbo两款语音模型,支持17种语言及上百种预置音色。T2A即Txt to Aduio,文本生成音频。

该模型已上线海螺语音平台,所有人可以免费体验。
体验地址:https://hailuoai.com/audio

创始人的“暴论”与洞见
在MiniMax-01模型发布当晚,该公司创始人闫俊杰先生接受晚点采访。
晚点对话MiniMax闫俊杰:创业没有天选之子
当时看起来“暴论”频出,比如:
-
“千万不要用上一代移动互联网产品方法论来思考新产品。”
-
“中国大部分公司,不管创业公司还是大厂,都还在用做推荐系统的方法来做大模型产品。”
-
“不是用户越多,模型能力就提升越快,模型的进步不需要用户。”
-
“如果重新选,第一天就应该开源。因为开源能加速技术进化。”
-
……
但经历这一个月的事情后,今天再回过头来看,很多观点都相当有前瞻性:
1)技术驱动比商业更重要
对于AI公司,有且只有一个终点,那就是实现AGI(通用人工智能),如果不是为了这个终点而奋斗,那就别来搞AI了,或者不要自称AI公司。
而实现AGI,技术品牌是一个比商业、市场更重要的驱动力。在建设技术品牌过程中,开源是一个很重要的事情。它会加速技术进化,做得好的地方有人鼓励,不好的地方有人批评,会有生态,帮你一起做。
闫俊杰透露,从MiniMax-01模型开始,他们会持续做技术品牌,通用模型今后都会直接开源。而且,开源不会自己藏一个更好的东西,因为这没有意义,所有模型在一年后都会落后。
“如果可以重新选,应该第一天就开源。”闫俊杰还强调。
2)模型性能与用户没有直接关系
“不是用户越多,模型能力就提升越快。”
闫俊杰认为,更好的模型可以导向更好的应用,但更好的应用和更多的用户并不会导向更好的模型。
在日常使用中,模型比大部分用户都更聪明,大部分用户的query(查询)其实没有模型自己模拟得好。用户与模型性能,并不是呈正比关系。而模型一旦更智能后,用户反而会如潮水般涌来。
比如DeepSeek,只用了7天,全球用户数破亿。犹记得我刚开始下载DeepSeek时,只有几千个用户。

那,不做用户该做什么呢?
闫俊杰认为:“应该非常清晰地定义模型能力分级,然后搞清楚每一代提升,需要什么样的算法、数据和推理过程,通过技术手段来逼近定义好的指标。”
当前,MiniMax最重要的目标不是增长,也不是收入,而是“加速技术迭代”。
3)不要老提六小虎或四小龙
媒体总喜欢把几个AI创业公司搞在一起,称什么六小虎(MiniMax、月之暗面、智谱、阶跃星辰、零一万物、百川智能)、四小龙(智谱、MiniMax、月之暗面、百川智能)。
我个人一直不太赞成这种叫法,所以我们文章里也很少提这种叫法。就跟新能源汽车一样,去人为分什么新势力、旧势力,只要定语够长,人人都是第一。
没有必要,大家都是一个行业,都在一个赛道,就应该放在一起。
闫俊杰也是这样认为,“不应该把创业公司分成一个单独类别。创业公司之间比其实意义不大,应该是整个行业一起。”
Doubao、Qwen、Hunyuan、GLM、Kimi、MiniMax、ERNIE、星火、Step、baichuan、Yi、DeepSeek,国内的这10来家大模型,就应该放在一起比。
4)Google今年会很强
闫俊杰认为,Google今年会更强,因为它同时掌握TPU(Google自研的AI 芯片) 、训练框架(TensorFlow)和算法,可以一起优化。
不得不说,闫俊杰这一点判断非常准。自去年12月以来,无论是Google发布的视频模型Veo2还是通用模型Gemini 2.0家族,都是一经发布就直接进入第一梯队,持续后尘发力。
哎,可惜的是,“我们(国产模型)不能自己定制GPU,只能在一个标准硬件上去做,这就会更复杂。”
5)对齐税
大模型领域,一直有一个“对齐税”的说法,就是如果你一定要把模型去对齐一个别的模型,比如GPT,那就会有一些能力受限。
闫俊杰坦诚,“做一个o1很容易,蒸馏几千条o1数据就可以了。我们做过这样的实验,最近也有不少这样的学术论文,这是一个业内共识。”
“但我们不太需要说自己有个o1,然后发个新闻稿。我们现在的业务,也不依赖于o1这类模型。”
6)建议AI公司做模型能力分级
闫俊杰建议,“我们应该非常清晰地定义模型能力分级,然后搞清楚每一代提升,需要什么样的算法、数据和推理过程,通过技术手段来逼近定义好的指标。”
最终在一个领域做得好的公司,不一定是第一个做这个方向的公司,而是最能充分发挥这个方向潜力的公司。不在于早一个月、晚一个月。
7)不要总跟着OpenAI跑
国产大模型跟美国模型有一个区别,就是缺少内部定义的benchmark(基准),缺少一些自己的底层思考和设计,更多是在对齐OpenAI。
闫俊杰认为,这方面,国内的DeepSeek和智谱做得不错。“DeepSeek很纯粹。智谱,他们是最早有AI路线图的,这点我很佩服。”

OpenAI(左)以及智谱(右)对AI能力等级的理解
8)做AI≠把移动互联网复制一遍
去年,很多人认为,做AI就是把移动互联网复制一遍,应用-投流-用户-垄断。不是这样的,移动互联网的逻辑不适合拿来做AI。
因为,产品用户越多,模型性能不会自然变好。只有更好的模型,才能出来新的东西,新的东西才会出新的商业模式。
现在,越想到闫俊杰的这句话,我越觉得后背发凉。DeepSeek带来的万物接入盛况,不就是这样子的吗?
9)2025年会是Agent大年
2025年会是Agent高速发展的一年,不管是单Agent的系统需要持续的记忆,还是多Agent系统中Agent之间大量的相互通信,都需要越来越长的上下文。
于是,MiniMax推出了支持更长上下文的01系列模型。
关于Agent应用方面,闫俊杰认为,除了最先落地的Coding(编程)外,信息获取也是一个有意思的场景。
10)技术研发目标最重要
对于MiniMax的2025年,如果说一定要设定一个目标是什么的话,闫俊杰认为是技术研发目标。
2025年,MiniMax最重要的目标是技术迭代。

写在最后
进入2025年,你会发现什么?
你会发现,仿佛一夜之间,整个行业的风向变了——技术成为焦点,研发备受重视,开源成为主流。
DeepSeek的火爆让中国的开源模型被全世界看见,从DeepSeek到阿里的Qwen,再到MiniMax,中国AI力量正逐步走向世界舞台。
在这场变革中,MiniMax始终坚持“以开源促创新”。正如其创始人闫俊杰所言:“开源不仅倒逼我们提升算法创新效率,更能增强全球技术品牌的影响力。”
面对浪潮,MiniMax的这份坚守,甚至显得有些“特立独行”。
2023年,在大家都在追随Dense(稠密)模型时,MiniMax已将80%以上的算力和资源投入MoE(混合专家)模型的研发。后来,我们都知道,MoE模型成为了业内共识。
如今,在大家都纷纷跟随o1推理模型的当下,MiniMax却另辟蹊径,大胆将技术对准困扰整个行业的“Transformer难题”,首次实现了大规模线性注意力机制,并将其开源。
不焦虑,不盲从,MiniMax始终保持着自己专注与清晰的判断。
这种特质,在他们家的AI视频应用「海螺AI」身上,可见一斑。

以技术驱动,稳扎稳打,不绣花活。MiniMax的风格,颇有“结硬寨,打呆仗”的智慧。
他们选择了一条不走捷径、艰难但可以走得更高更远的路,愿功不唐捐。
(文:沃垠AI)