


DeepEP是为混合专家(MoE)和专家并行(EP)量身定制的通信库,其提供高吞吐量且低延迟的全对全GPU内核,这些内核也被称为MoE调度与合并。
对于对延迟敏感的推理解码任务,DeepEP包含了一组采用RDMA技术的低延迟内核,以最大程度地减少延迟。该库还引入了一种基于钩子的通信与计算重叠方法,这种方法不会占用任何流式多处理器(SM)资源。
DeepSeek指出,DeepEP的实现可能与DeepSeek-V3论文中略有不同。
GitHub地址:
https://github.com/deepseek-ai/DeepEP
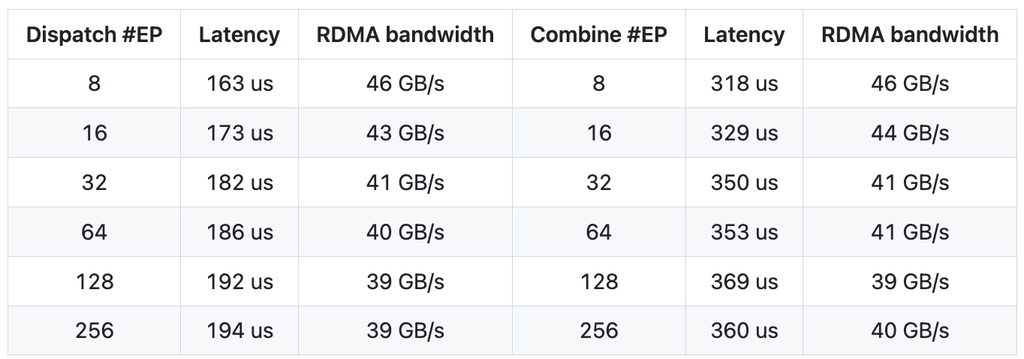
具体性能方面:
在H800(NVLink的最大带宽约为160 GB/s)上测试常规内核,每台设备都连接到一块CX7 InfiniBand 400 Gb/s的RDMA网卡(最大带宽约为50 GB/s),并且遵循DeepSeek-V3/R1预训练设置(每批次4096个Tokens,7168个隐藏层单元,前4个组,前8个专家(模型),使用FP8格式进行调度,使用BF16格式进行合并)。

在H800上测试低延迟内核,每台H800都连接到一块CX7 InfiniBand 400 Gb/s的RDMA网卡(最大带宽约为50 GB/s),遵循DeepSeek-V3/R1的典型生产环境设置(每批次128个Tokens,7168个隐藏层单元,前8个专家(模型),采用FP8格式进行调度,采用BF16格式进行合并)。
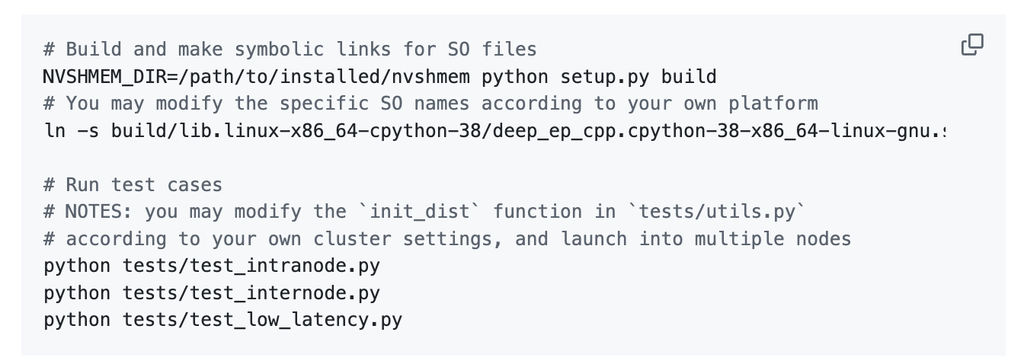
快速启动要求:




接口和示例:

“DeepSeek在MoE模型方面所实现的优化程度颇高,而MoE模型因其规模和复杂性而向来极具挑战性。DeepEP能够借助像NVLink和RDMA这类尖端硬件,如此精准地处理相关任务,并且还支持FP8格式,这着实令人惊叹。”
“对NVLink和RDMA的支持,为大规模的MoE模型带来了变革性的影响。看来DeepSeek又一次突破了AI基础设施的极限。”
(文:智东西)