
今天是2025年3月10日,星期一,北京,天气晴。
今天我们继续看推理大模型如何控制思考长度的话题,回顾下已有的工作,并看有哪些方案,并看看具体实现细节。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、推理大模型思考时间控制问题回顾
关于这块,我们已经讲过三个了,现在回顾下。
1、从Deepseek-R1思考过程说起
我们在文章《再聊误区–Deepseek-R1思考过程在使用中的几个问题及对策》(https://mp.weixin.qq.com/s/r8yoXRMWnoh_rUbHjzjEsQ)中做过论述,
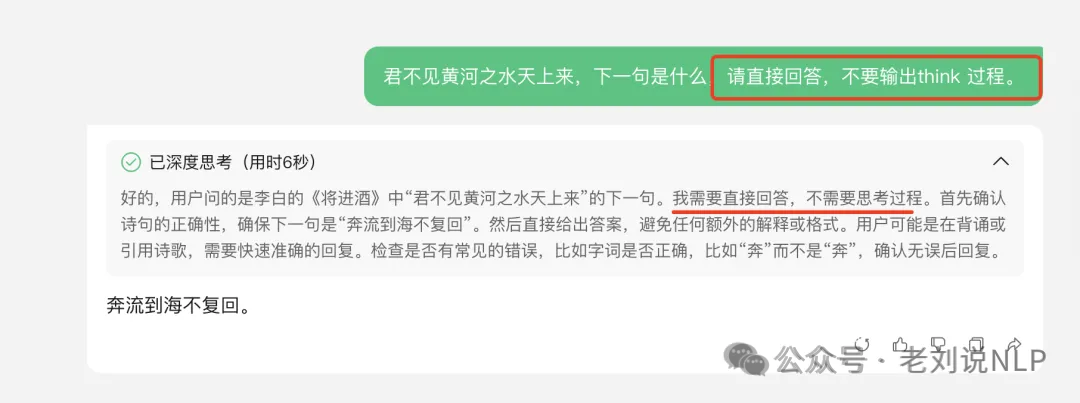
针对Deepseek-R1思考问题,减少思考过程有两条路可以走。
第一条路,修改prompt template,添加<think>/n/n</think>,这样减少think的概率,与前面强制进行think相对,这是骗过R1,让它误以为已经think过了,从而降低再出现think的概率。但这个是得碰运气。当然,这里的修改prompt template,不是直接在prompt后面加<think>/n/n</think>,而是在启动的时候,写入到chat template里。
第二条路,是干预token解码采样,把think相关的token去掉不去采样就好了。例如基于SGLang修改,修改模型服务方式,跳过tokenizer阶段,加上这个参数 –skip-tokenizer-init,然后手动进行 tokenizer 的 encode decode。但这种方式,其实破坏了之前模型预测的概率分布,理论上说会想想效果。但具体损失多少,需要具体实验,例如,社区成员实验发现,32b蒸馏模型上很稳定,到这个测试集合还是偏向于非推理任务。
2、Claude3.7的混合模型推理机制解析
接着,我们在《近期RAG误区再认识及Claude3.7的混合模型推理机制解析》(https://mp.weixin.qq.com/s/dufuxz5_tLwMx0Zx1E9wIA)中已经提过了Claude3.7的混合模型推理机制。
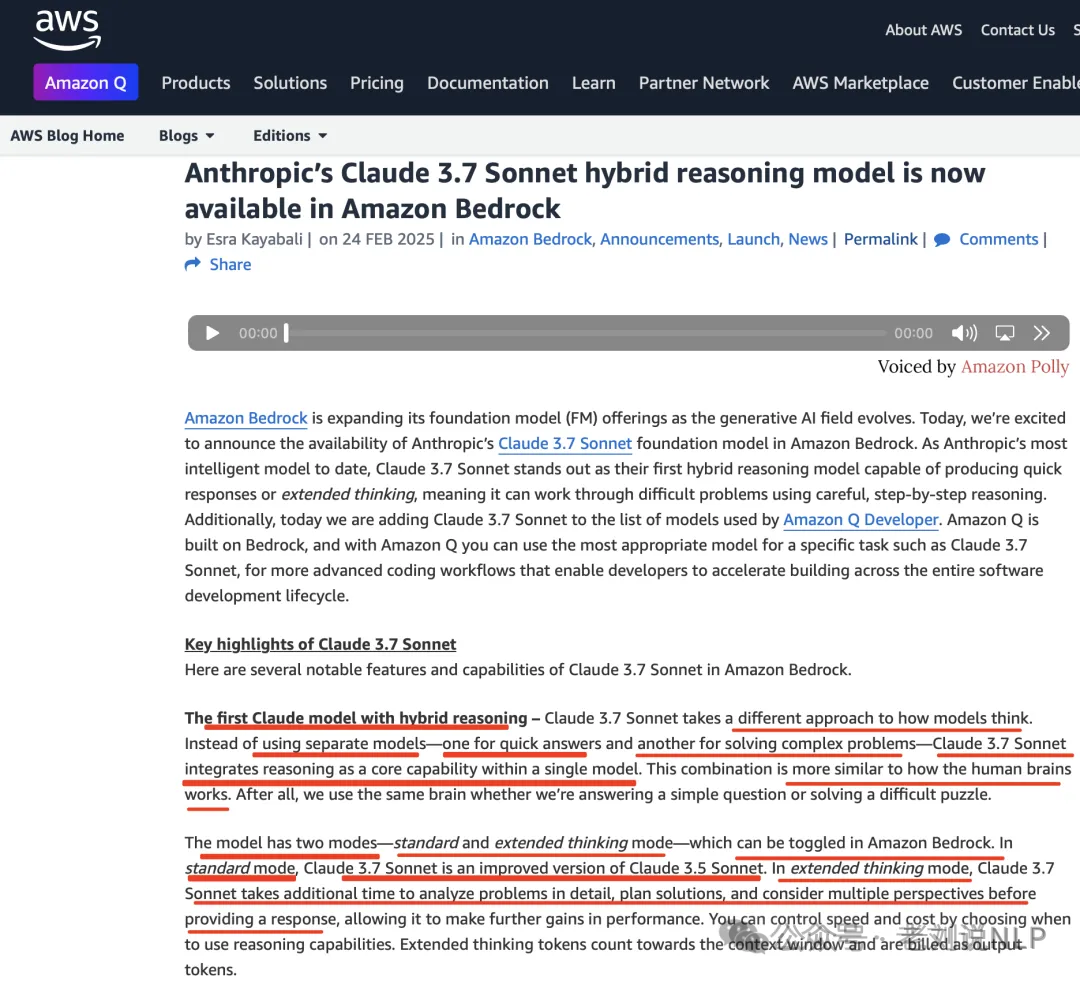
Claude3.7Sonnet采用了不同的模型思维方式。Claude3.7Sonnet不使用单独的模型(一个用于快速回答,另一个用于解决复杂问题),而是将推理作为核心功能集成到一个模型中。
有两种模式-标准模式和扩展思维模式-可在AmazonBedrock中切换。在标准模式下,Claude3.7Sonnet是Claude3.5Sonnet的改进版本。在扩展思维模式下,Claude3.7Sonnet需要更多时间详细分析问题、规划解决方案并考虑多个角度,然后再提供响应,从而进一步提高性能。您可以通过选择何时使用推理功能来控制速度和成本。扩展思维标记计入上下文窗口并作为输出标记计费。
所以,我们顺道来分析下这个机制,两个,一个是控制是否thinking,一个是thinking多久。
思路可以猜想下,可能使用了特殊的token,在提示词最后加上这个 token,模型就会开始推理模式回答,没有这个token,按旧有方式回答。然后工程上进行 API 包装。限制长度的部分应该也只是工程上的处理,程序会观察输出内容是否超过budget,超过了就强行插入终止思考。
那么,问题来了,这个其实还是依赖于大模型自身的能力,大家要想的是,假设这是微调或者强化出来的结果,这个是如何微调的,但claude这种,似乎验证了可以通过微调来实现这种效果,路线可行?
既然有开关,那么在训练数据侧就应该会有一个token,标记出是否要thinking。如果有限制token,那么是否构造训练数据时,也会将这类限制写入到input 当中,大家感兴趣的,可以去做做实验。
如果使用特殊token做开关的话,这样训练时可以分开训练,模型可以同时拥有两种甚至多种能力。互相之间不会干扰。当然,如果将”<think>\n\n</think>“作为特殊token,或许也可以,但是这会产生一定的干扰。
模型有几类事情,第一个是过于简单不必思考的,思考过程可以为空,R1 是这么做的;
第二个是事情复杂,需要思考才能解决的,这类用 RL 激活<think>的思考复杂度;
第三个是claude 目前做的,就是事情可能也是比较复杂,但是用户要求不思考,那么我依旧需要高质量的回答问题。
那么如何实现?
二、从S1通过预算控制调整思考到长度约束强化
我们先看第一个工作S1,《s1: Simple test-time scaling》(https://arxiv.org/pdf/2501.19393,https://github.com/simplescaling/s1),提到多种预算控制方案。

一种是条件长度控制方案,依赖于在提示中告诉模型它应该生成多长时间。例如可以执行多种粒度的控制,如token-条件控制,在提示中指定思考token的上限;步骤条件控制,指定思考步骤的上限,其中每个步骤大约为100个tokens;类-条件控制编写两个通用提示,告诉模型思考一小段时间或很长一段时间。
但这这种思路会导致突然的中断,通常会打断推理过程中的中间步骤,对模型准确性和用户可解释性产生负面影响。
所以呢,更好的方式,其实是进行强化微调,也就是L1,《L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning》,https://arxiv.org/pdf/2503.04697,https://cmu-l3.github.io/l1/,引入了长度控制策略优化(Length Controlled Policy Optimization (LCPO)),一种强化学习方法,优化准确性并遵守用户指定的长度约束,这种模型需要满足最终输出的正确性并生成符合提示中指定的长度约束的推理序列的目标。
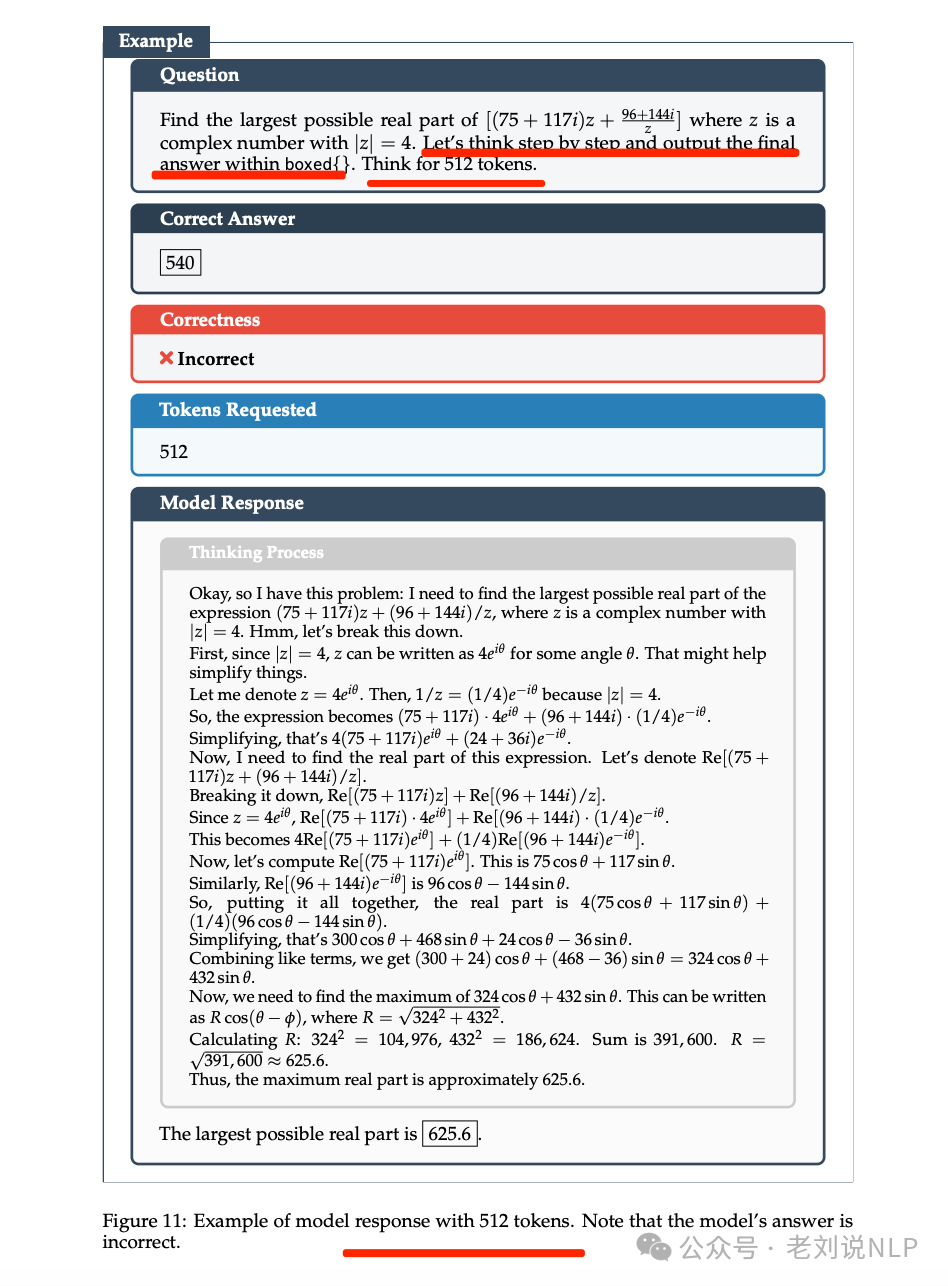
但是,挺惊讶他们的方法会有效。他们通过提示词中加入「Think for xxx tokens」以及「Think for maximum xxx tokens」,来提示模型回答时注意长度,然后通过RL来加强这个长度能力。而目前我们知道LLM一个很大的缺陷就是不大会数数。
所以这个数字可能就是起到一个大概的指导性,相当于长、中、短,可能把这个数字换成xs, s, m, l, xl效果会比绝对数值要更好一些?。另外,以后 RL 中增加对推理长度的控制,可能会成为必要的一个环节。在 RL 阶段,首先是让模型可以正确的回答问题,然后再用长度控制压缩思考步骤,并且副产物应该是避免了无结果的循环思考。
其具象化表示如下:
在具体实现上,长度控制策略优化,核心包括训练数据以及奖励函数的设置两个方面。
在训练数据上,每个实例只包含输入提示和最终答案(即没有中间推理轨迹),DeepScaleR-Preview-Dataset数据集,包含40K个来自AIME、AMC、Omni-Math和STILL的问题-答案对,为了实现长度控制,每个提示通过附加一个目标长度指令来增强,形式化如下:
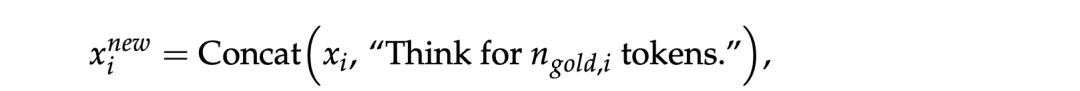
其中,ngold,i从Z(nmin,nmax) 中均匀采样得到,最终得到训练数据:
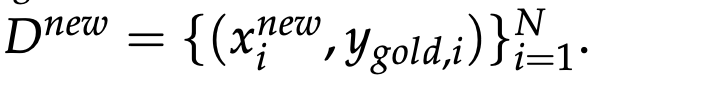
在模型训练上,采用DeepSeek-R1-Distill-Qwen-1.5B。
在训练方法上,在奖励函数,使用强化学习目标更新模型,奖励函数结合正确性奖励和长度惩罚,其中包括两种长度约束模式,很自然的,强化学习采用GRPO方法,包括两个版本。
1、LCPO-Exact模式
在这种模式下,生成的推理必须严格等于目标长度,具体通过选择固定的目标长度并将其附加到每个测试提示上来控制输出长度。
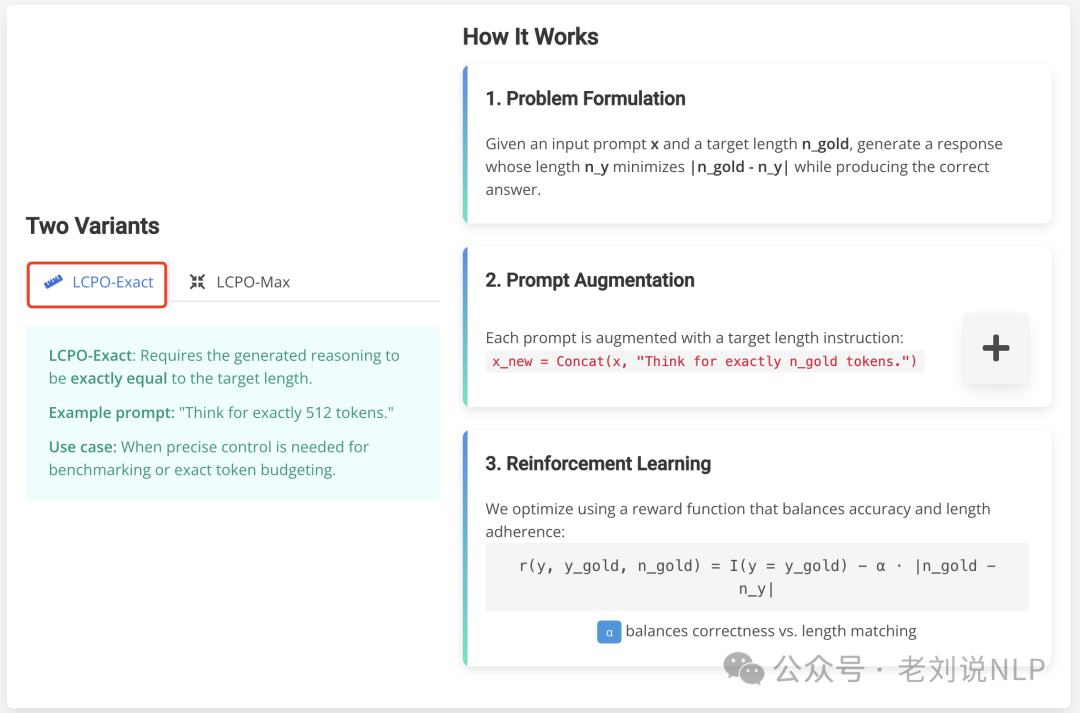
如下所示:
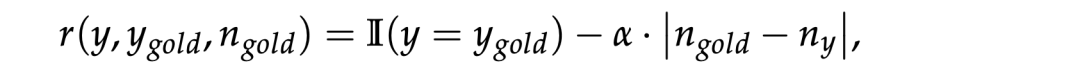
I(⋅)是指示函数,ny是生成的输出长度,α是一个标量,用于调节生成正确答案与满足目标长度之间的权衡。当正确性至关重要时,较低的α值会优先考虑正确性;而较高的值则强制严格遵守长度限制。
最终得到L1-Exact 模型。
在推理时,通过选择一个固定的目标长度ngold(或一组长度),并将其统一附加到每个测试提示后面来控制输出长度。
2、LCPO-Max模式
LCPO-MaX长度约束用于灵活生成不同长度的输出。当用户优先考虑保持在计算预算内而不是坚持精确的生成长度时,这种方法很有价值。
为了训练 L1-Max,使用相同的强化学习框架对 L1-Exact 模型进行微调,但采用了一个修改后的奖励函数:
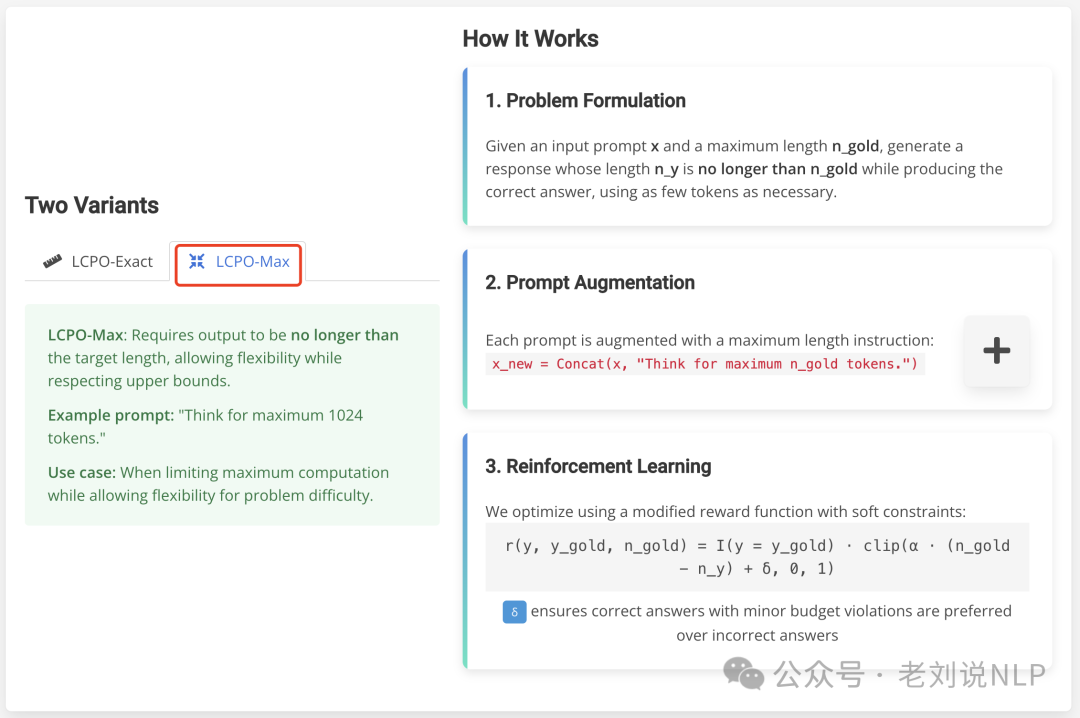
如下:
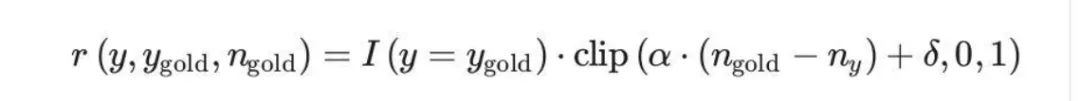
其中,
α控制对长度违规的惩罚,应用了一个软约束,即逐渐惩罚超过目标长度的输出。
总结
本文主要回顾了推理大模型思考时间控制问题回顾,并看了几个工作,都值得一看,无论是使用prompt硬处理,还是使用强化微调,其实都依赖于大模型对数字是敏感的,这其实是不太可控的。并且,大模型推理性能是跟推理是看有关系的,控制之后,是否会带来损失,还需要具体业务问题具体分析。
参考文献
1、https://arxiv.org/pdf/2503.04697
2、https://mp.weixin.qq.com/s/r8yoXRMWnoh_rUbHjzjEsQ
3、https://mp.weixin.qq.com/s/dufuxz5_tLwMx0Zx1E9wIA
(文:老刘说NLP)