
腾讯AI Lab 投稿
量子位 | 公众号 QbitAI
只要微调模型生成的前8-32个词,就能让大模型推理能力达到和传统监督训练一样的水平?
腾讯AI Lab与香港中文大学(深圳)合作开展了一项新研究,提出了这样一种名为无监督前缀微调(UPFT)的方法。
UPFT大大降低了训练模型的数据生产成本,能够将训练时间缩短约75%,并将采样成本降低约99%。

团队研究发现,关键的正确推理信号,全都藏在模型的“前几步”里,将这种现象称为“推理前序自一致性”。
基于这一发现,团队尝试仅微调模型生成的前8-32个词,结果其推理能力果真可达到与传统监督训练相当的水平。
UPFT不仅降低了大模型的训练耗时和采样成本,在减少训练序列长度和内存消耗方面也展示了显著优势,训练序列长度缩减了82.6-94.7%。
突破大模型训练算力瓶颈
数据生产是训练大模型(LLM)过程中的一大难题,尤其是算力成本的快速攀升给研究和应用带来了巨大挑战。
传统方法在让模型学会推理时,通常采用生成大量候选解,然后从中筛选出正确的推理路径进行训练的方式。
这种策略看似直接,但实际操作中却面临诸多困难。
以数学解题为例,上述方法通常需要为每道题目生成16个候选解,再从中筛选出正确的完整推理链。
这种方式对算力的需求极大——每次训练迭代,模型需要进行数十次采样,GPU算力消耗呈现快速增长的趋势。
单次数据生产可能消耗数百万token的算力资源,而当题目难度增加时,所需的采样量和算力开销还会进一步提升。
这种高成本的训练方式,不仅效率较低,也成为技术落地的一大障碍。
在小规模实验中,这种方法尚可勉强支撑,但若面对百万级题库,算力成本的压力将变得难以承受。
研究团队发现,与其让模型进行大量盲目采样,不如将重点放在识别真正重要的正确推理信号上。
这种更有针对性的策略不仅能够提升效率,还能显著降低算力开销。接下来,我们将进一步探讨他们的核心发现和解决方案。
找到AI解题的关键信号
在AI解决数学问题的过程中,人们或许会认为它具备某种“随机应变”的能力,但事实果真如此吗?
通过一系列严谨的实验,研究者们揭示了一个令人惊讶的现象:
AI在解题时,真正决定正确答案的推理信号,可能早已隐藏在其推理路径的“前几步”之中。
这一现象被研究者称为“推理前序自一致性”。
具体而言,无论AI在后续的推理过程中如何“发散思维”,其推理路径的开端几乎呈现出高度一致的模式。
这一发现不仅揭示了AI解题的底层逻辑,也为优化训练策略提供了全新的视角。
以一个典型实验为例,研究者让模型针对某道数学题生成了8个不同的解题方案(标记为A1至A8)。
尽管这些方案的最终答案可能千差万别,但令人意外的是,前32个词的内容几乎完全相同。
这一现象表明,AI推理过程中的关键信号似乎集中在推理的起点部分,而后续的“发散”更多是表象。

△让模型针对同一问题,随机生成8次解答
为了进一步探明这一现象的本质,研究团队分别使用通用型模型(Llama-3.1-8B-Instruct)和数学专精模型(Qwen2.5-Math-7B-Instruct)进行了实验。
研究者让这两款模型针对一系列数学题目生成了多达1000条解题方案,并对这些推理路径进行了详细分析。
实验结果表明,有大量的独立推理路径共享相同的推理前序。
并且随着前缀长度的增加,每种推理前序所对应的平均推理路径数量逐渐减少,AI生成的解题方案开始呈现出“分化”的趋势。
这一发现为“推理前序自一致性”提供了强有力的证据,也进一步证实了关键推理信号集中在推理起点的假设。

△前序长度和推理路径数量的关系
既然不同的推理路径可能共享相同的推理前序,那么一个关键问题随之而来——
究竟需要多长的前序长度,才能有效区分正确与错误的推理路径?
为了回答这一问题,研究团队设计了专门的实验,分别从正确和错误的推理路径中提取样本,并针对这些路径的前序部分进行了大规模采样分析。
实验结果下图所示,研究者发现了一个重要的临界点:
只有当前序长度超过某个临界长度时,正确路径与错误路径之间的差异才开始显现,并能够被有效区分。
这一发现表明,前序长度在推理路径的分化中起着至关重要的作用,而这个临界长度则为后续优化模型推理策略提供了一个重要的参考标准。
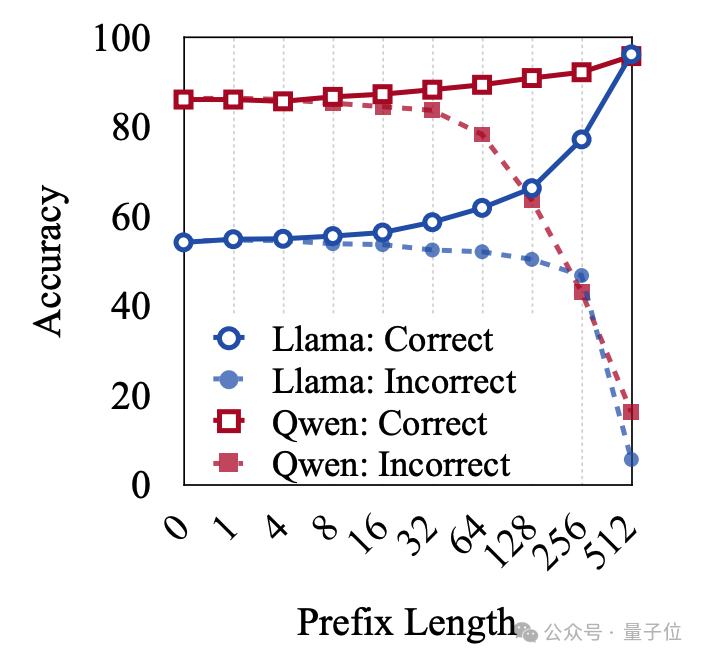
△正确和错误在开头部分很难区分
从贝叶斯视角看问题:覆盖范围与准确性的平衡
为了更深入地理解这一问题,研究团队引入了一种基于贝叶斯框架的科学视角,来重新审视训练过程。
简单来说,贝叶斯框架是一种概率推理的方法,它帮助我们理解模型在面对一个问题时,如何通过不同的推理路径得出正确答案的可能性。
在这一框架下,模型的表现可以被分解为两个关键因素:推理路径的“覆盖范围”和“准确性”。
覆盖范围指的是模型在面对一个问题时,能够探索到多少种不同的解题思路。
用贝叶斯的语言来说,这相当于模型在生成推理路径时的“先验分布”——即模型能够覆盖的解题思路越广泛,它找到正确答案的可能性就越高。
准确性指的是在某一条具体的推理路径上,模型最终得出正确答案的可能性。
在贝叶斯框架中,这可以看作是“条件概率”——即给定某条推理路径,模型得出正确答案的概率越高,这条路径的质量就越好。
传统的“拒绝微调”策略虽然在保证准确性方面表现不错——因为它只选择了那些最终答案正确的推理路径——但却忽略了覆盖范围的重要性。
换句话说,这种方法过于“挑剔”,只关注了“正确答案”,而没有充分利用那些可能包含宝贵解题思路但最终答案错误的推理路径。
这种“只选一个正确答案”的做法,实际上限制了模型的学习潜力。

△平衡数据准确性和数据覆盖程度
基于上述分析,研究者们提出了一种新方法,试图找到一个平衡点,既能保证答案准确,又能探索更多解题思路。
他们发现,解题路径的前半部分(称为“前缀”)往往包含了多种可能的解题思路,而后半部分则更决定最终答案是否正确。
因此,他们提出只训练模型生成前缀部分,既能覆盖更多解题思路,又能减少计算成本。
具体来说,他们让模型生成解题路径的前半部分,并用这些前缀来训练模型,从而在效率和效果之间找到更好的平衡。
研究人员将这种方法命名为无监督前缀微调(Unsupervised Prefix Finetuning, UPFT)。
对于每道题目,他们只生成一条推理路径,而不是像传统方法那样生成多达16条。
同时,他们对生成的内容进行了优化:对于10%的题目,生成完整的解题路径;而对于剩下的90%,只生成解题路径的前半部分(即前几个关键步骤)。
这种方式既节省了计算资源,又能让模型接触到多样化的解题思路。
1/10采样成本取得更优性能
为了验证UPFT方法的有效性,研究团队测试了以下两种场景:
-
对于没有标准答案的数据进行无监督采样:每个问题仅采样一个解决方案,不进行过滤。
-
对于有标准答案的数据进行有监督采样:传统方法每题采样16个解决方案,通过正确答案筛选正确解决方案。
在实验设置上,研究团队使用了通用模型(Llama-3.1-8B-Instruct)和数学专用模型(Qwen2.5-Math-7B-Instruct),以及目前十分火热的R1类型的长思维链模型(DeepSeek-R1-Distill-Qwen-7B)。
测试选择了多个具有挑战性的推理基准测试,包括GSM8K(数学推理)、Math500(复杂数学题)、AIME2024(数学竞赛题)和GPQA(综合科学推理)。
结果,UPFT在性能和成本上都展现了显著优势,提升性能的同时减少了训练token数量。
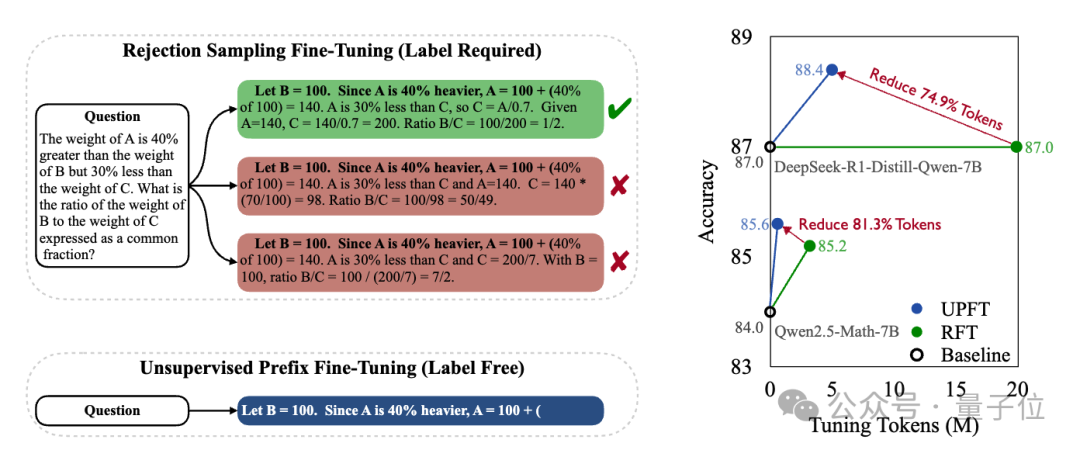
UPFT提高无监督上限
结果表明,与传统的监督微调(SFT)相比,UPFT在多个方面表现出色:
-
在使用U-Hard数据集时,Qwen2.5-Math-7B-Instruct的UPFT准确率达到了54.5%,而SFT仅为51.3%。
-
对于DeepSeek-R1-Distill-Qwen-7B,UPFT达到了61.6%的准确率,而SFT为56.4%。
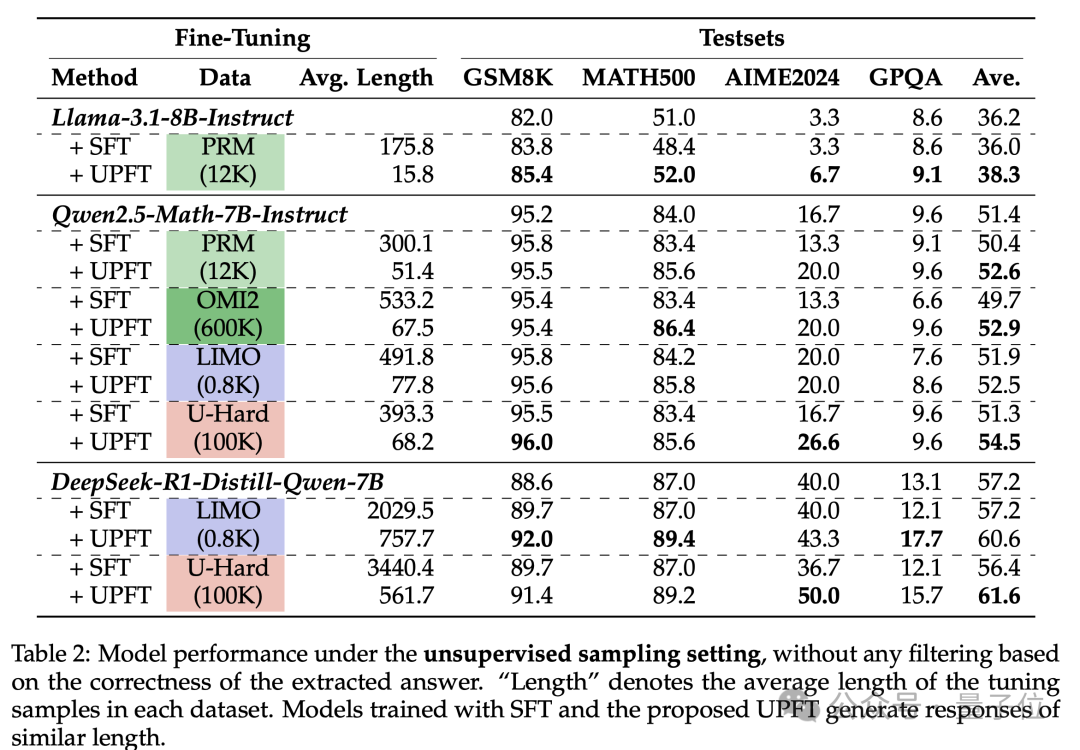
△UPFT和传统SFT方法的无监督对比实验结果
在更具挑战性的任务(例如AIME2024和GPQA)中,UPFT的表现更为突出。
在AIME2024上,Qwen2.5-Math-7B-Instruct的UPFT准确率为26.6%,相比之下,SFT为16.7%。对于DeepSeek-R1,UPFT达到了50.0%,而SFT为36.7%。
在GPQA科学推理任务中,UPFT同样表现优异,超越了SFT。
在效率方面,UPFT展示出了极大的优势。UPFT显著减少了训练序列长度,缩减了82.6-94.7%。
在U-Hard上的平均token数为68.2,而SFT需要393.3个token,内存消耗大幅降低。在DeepSeek-R1-Distill模型上仅用561个标记就优于SFT的3440个标记,显示了其极高的效率。
UPFT超越有监督SFT性能
为了进一步探究UPFT的效率极限,研究团队对比了需要进行大量采样的传统方法,即需要标签验证来过滤掉正确解决方案,来突出UPFT的效率优势。
结果显示,在Qwen2.5-Math-7B-Instruct上,UPFT和疯狂刷题的RFT准确率打平(52.6%),但UPFT只用1.2%的采样token(0.6M vs 51.7M)。
同时UPFT在DeepSeek-R1-Distill-Qwen-7B上飙到58.7%,比RFT高1.5个点,采样token的花费却只需要RFT的1%,训练token花费仅为RFT的25%。
在基座模型Llama-3.1-8B-Instruct上,UPFT得分38.3%,跟V-STaR并肩。但是在增加了标签过滤后的UPFT性能超过RFT,得分38.8%,展示出UPFT与现有方法的兼容性。
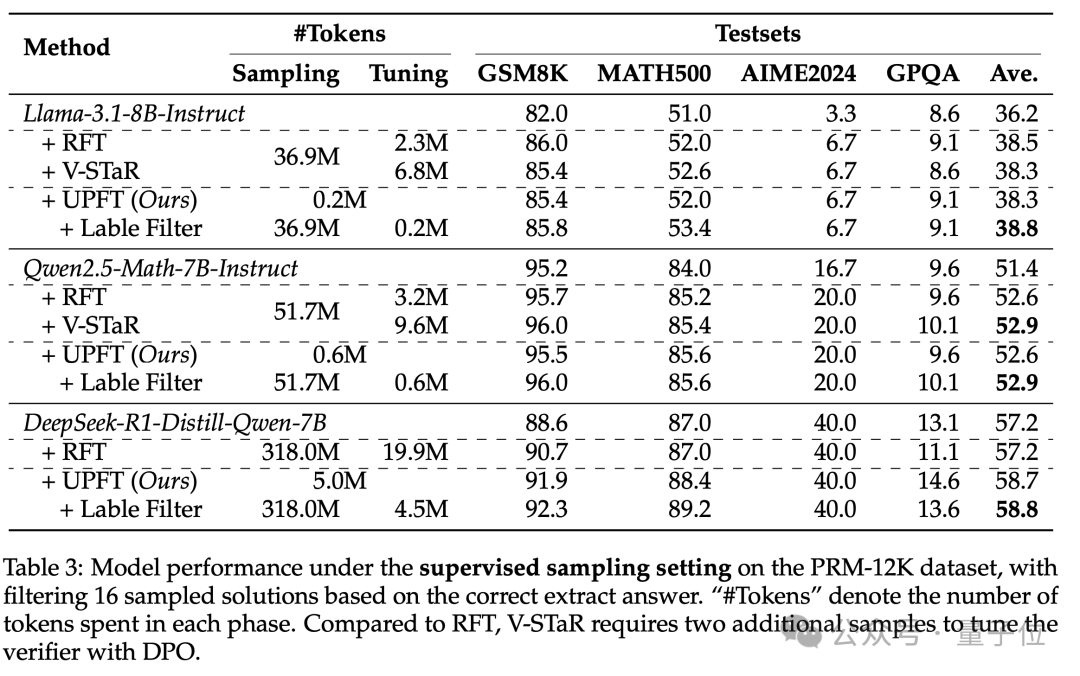
△UPFT在有监督场景下仍然打败了传统SFT以及V-STaR方法
UPFT对前缀长度比较鲁棒
为了揭秘前缀长度对模型性能影响,研究团队展开了进一步的实验。
研究者们通过实验发现,不同模型在解题路径前半部分的长度(即“前缀”长度)对准确性的影响比较鲁棒。
以 Llama-3.1-8B-Instruct 模型为例,当解题路径的前半部分包含8个token时,模型的准确率逐渐提升至52.0%然后逐渐下降, 对于Qwen2.5-Math-7B-Instruct 模型的表现则有所不同, 其性能在前32个token处均缓慢提高。
这表明,不同模型对解题路径前半部分的依赖程度存在差异,研究者们据此可以针对不同模型设计更合适的训练策略。
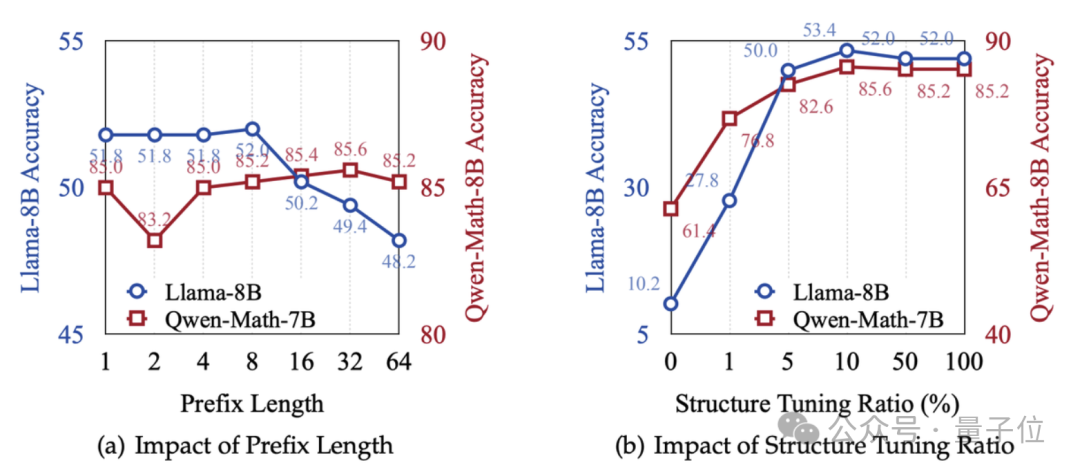
△训练的推理前缀长度和对应模型性能
总之,这项研究为大语言模型的高效、低成本训练开辟了新路径。
未来,研究团队计划继续探索UPFT的潜力,进一步优化模型训练效率,并探索与现有方法的兼容性。
作者简介
本文的通讯作者为涂兆鹏,腾讯专家研究员,研究方向为深度学习和大模型,在国际顶级期刊和会议上发表学术论文一百余篇,引用超过9000次。担任SCI期刊NeuroComputing副主编,多次担任ACL、EMNLP、ICLR等国际顶级会议领域主席。
第一作者为香港中文大学(深圳)博士生冀轲,腾讯AI Lab高级研究员徐嘉豪,梁添,刘秋志。
论文地址:
https://arxiv.org/abs/2503.02875
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)