

深度学习模型不断演进,推动了人工智能技术和应用边界的发展。看我文章的朋友应该还记得10月份的时候写过一篇《液态神经网络》推文,它为AI技术的发展开辟了新的道路。

近日,Liquid AI 推出的 STAR (Sparse Transformer with Adaptive Reception Fields) 模型架构,个人觉得它具有独特的稀疏注意力机制和超越传统 Transformer 的效率,利于自动化生成和优化人工智能模型架构。
技术创新点
传统的 Transformer 模型采用全注意力机制,其计算复杂度为 O(N^2)。其中 N 为序列长度,这种机制在处理长序列时会导致计算资源的巨大消耗。
STAR 模型通过引入稀疏性,将计算复杂度降低到接近线性水平,即 O(N*klog(N)),其中 k 为稀疏度参数。
显著提高了模型的可扩展性和实用性,使得在有限资源下处理更长序列成为可能。
STAR 模型中的稀疏注意力不是静态的,而是根据输入数据动态调整。
模型能够根据任务需求自适应地关注不同部分的信息,从而提高了灵活性和准确性。
这种动态调整的能力使得 STAR 模型能够更好地适应各种复杂场景,提升了模型的泛化能力。
STAR 保留了 Transformer 的多头自注意力机制,这使得模型能够从不同的子空间中提取信息,增强了对复杂模式的识别能力。
多头自注意力机制通过多个投影头来捕捉不同的特征表示,从而提高了模型的表现力。
与 Transformer 使用相对位置编码不同,STAR 采用了绝对位置编码。
绝对位置编码有助于模型更好地理解序列中元素的位置关系,尤其是在处理长距离依赖时更为有效。
这种编码方式使得模型能够更准确地捕捉序列中的上下文信息,提高了模型的性能。
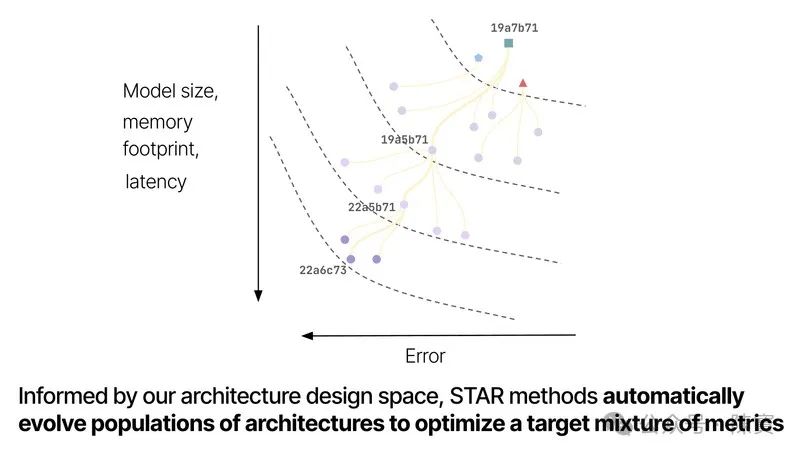
性能优势
由于 STAR 模型减少了计算量,因此可以在相同的硬件条件下处理更大的数据集或更复杂的模型结构。
对于资源受限的环境尤为重要,因为它意味着可以在不增加硬件投资的情况下提升模型的性能。
计算效率的提升也意味着模型可以更快地完成训练,这对于需要频繁迭代的场景非常有利。因为它可以缩短开发周期,加快产品上市速度。
通过自适应调整注意力范围,STAR 模型能够在保持较高准确率的同时减少过拟合的风险。
泛化能力的提升使得模型在面对未见过的数据时也能表现出色,增强了模型的实用性。
绝对位置编码的使用使得 STAR 在处理长距离依赖关系时更加有效,对于许多 NLP 任务来说是一个重要的优势,因为长距离依赖关系往往是理解和生成自然语言的关键因素。
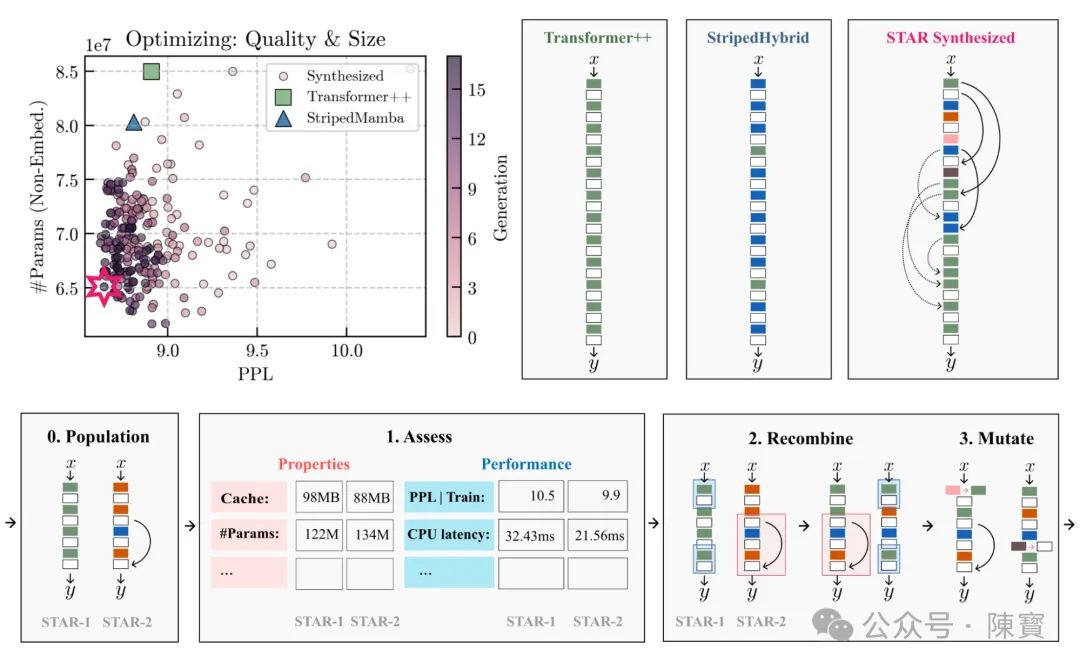
潜在影响
STAR 模型的成功展示了稀疏注意力机制的巨大潜力,这将激励研究人员探索更多创新性的方法来优化深度学习模型。
创新驱动的文化将推动整个领域的进步,带来更多突破性的技术和应用场景。
STAR 结合了 NLP 和 CV(计算机视觉)的技术,促进了不同领域之间的知识共享和技术迁移。
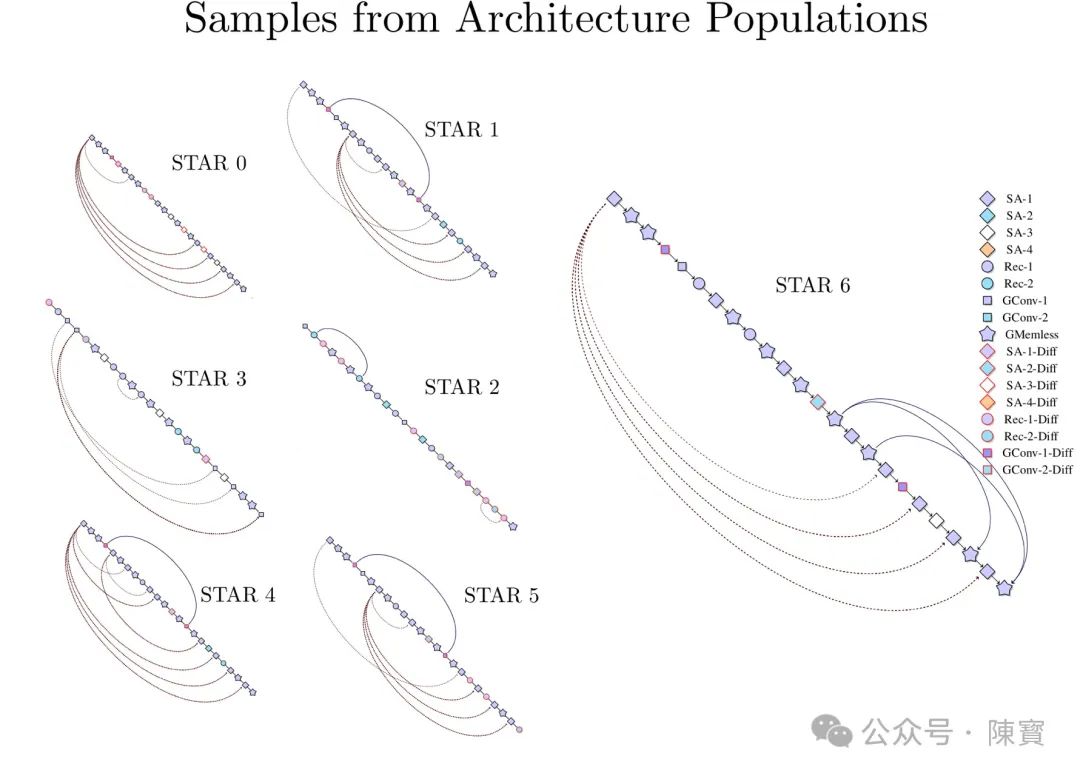
我认为,跨学科融合有助于解决更多复杂的实际问题,推动科学技术的整体发展。
⋯ ⋯
由于 STAR 提高了计算效率,企业能够在不增加硬件投资的情况下训练更大的模型或处理更多的数据。
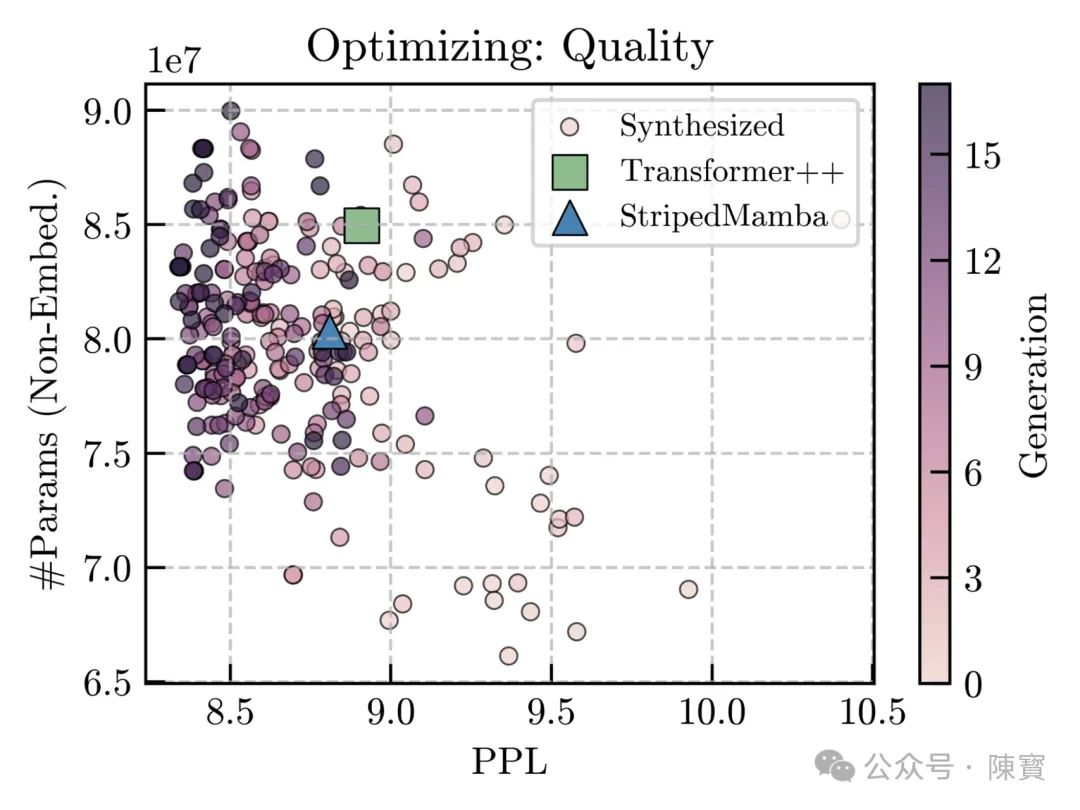

Liquid AI 的 STAR 模型架构以其独特的稀疏注意力机制和出色的性能表现,为深度学习领域带来了新的活力。它不仅提升了模型的效率和准确性,还拓宽了应用场景的范围。
(文:陳寳)