

作者:十九、大头
编辑:李宝珠
转载请联系本公众号获得授权,并标明来源
今天,黄仁勋带来了英伟达芯片的最新消息:AI 芯片架构 Blackwell 的升级版 Blackwell Ultra 将在今年下半年推出,NVIDIA GB300 NVL72 和 NVIDIA HGX™ B300 NVL16 全面增强模型推理能力,英伟达下一代 GPU 架构 Vera Rubin 明年上市。
近年来,从云计算到加密货币,从元宇宙到人工智能,全球科技领域的每一次重大风口,几乎都能看到英伟达 (NVIDIA) 的身影。尤其是在人工智能的新一轮热潮中,英伟达凭借其深厚的技术沉淀,牢牢掌控着数据中心 GPU 市场约 95% 的份额,成为 AI 芯片领域的绝对主导者。
然而,今年年初,DeepSeek 推理模型的横空出世向大众传递了一个明确的信号:过去依赖堆数据、堆算力的「大力出奇迹」模式已逐渐失效,这一度动摇了市场对 AI 算力前景的预期,以英伟达在内的多家科技巨头股价大幅下跌。尽管英伟达的股价随后有所回升,但其在行业中的主导地位已不再像过去那样坚不可摧,为证实公司的实力,英伟达势必要对其 GPU 进行全面升级和更新。
在北京时间 3 月 19 日凌晨 1 点举行的 GTC 2025 大会上,黄仁勋带来了英伟达芯片的最新消息:AI 芯片架构 Blackwell 的升级版 Blackwell Ultra 将在今年下半年推出,NVIDIA GB300 NVL72 和 NVIDIA HGX™ B300 NVL16 全面增强模型推理能力,英伟达下一代 GPU 架构 Vera Rubin 明年上市。
NVIDIA Blackwell Ultra 加速 AI 推理进程
去年的 GTC 大会上,黄仁勋公布了新一代 AI 芯片架构 Blackwell,作为 Hopper 的继任者,Blackwell 架构的 GPU 拥有 2,080 亿个晶体管,专注于加速生成式 AI 任务、大规模训练和推理工作负载,黄仁勋曾在演讲中自豪地宣称,这是迄今为止功能最强大的 AI 芯片系列。

今天的直播中,黄仁勋再次提及 Blackwell,他表示:「Blackwell 的优势是更快、更大、晶体管更多,计算能力更强。」此外,其采用的 NVL 72 架构 + FP4 计算精度的模式,也让 Blackwell 的性能得到进一步提升,这意味着,我们可以用更少的能耗完成相同计算任务。
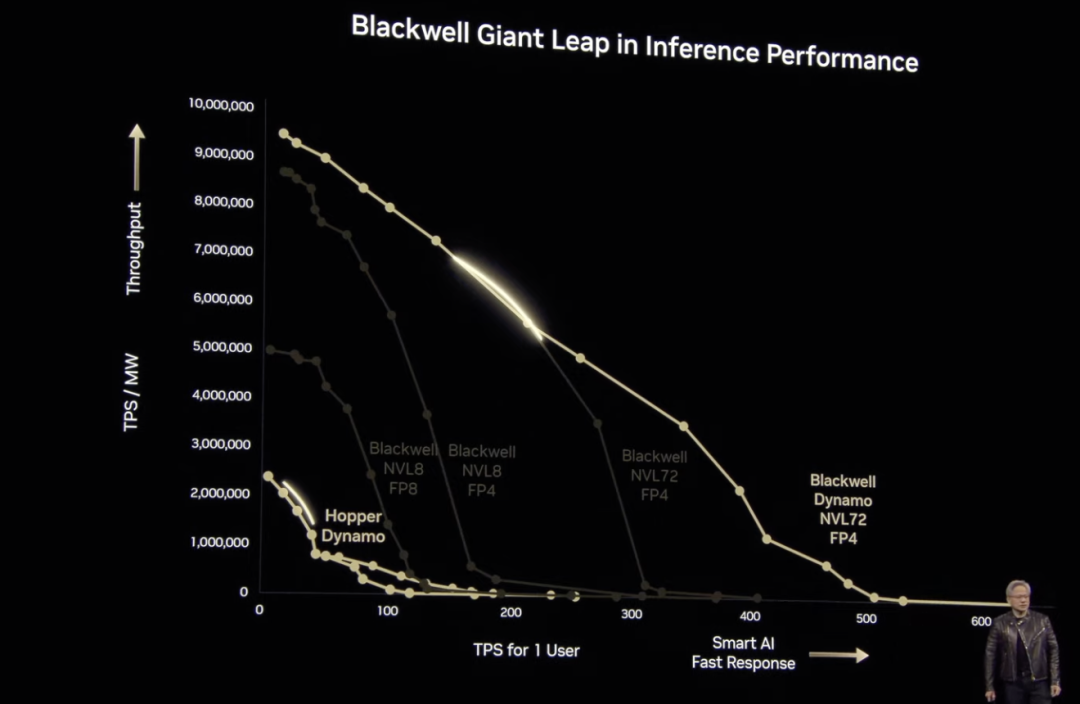
值得一提的是,DeepSeek 出现之后,人工智能市场的关注点逐渐从「训练」转向「推理」,本次大会,黄仁勋特意列举了一个推理模型案例,证实 Blackwell 计算性能的优越性——比 Hopper 高 40 倍。「我之前就说过,如果 Blackwell 开始大规模出货,你甚至没法把 Hopper 送出去」。当然,黄仁勋也提到,Blackwell 正在全力投入生产,今年下半年,NVIDIA Blackwell AI 工厂也会再次升级,并无缝过渡到 Blackwell Ultra。

Blackwell Ultra 将包括 NVIDIA GB300 NVL72 机架级解决方案,以及 NVIDIA HGX B300 NVL16 系统。
首先,NVIDIA GB300 NVL72 采用全液冷机架式设计,将 72 个 NVIDIA Blackwell Ultra GPU 和 36 个基于 Arm 的 NVIDIA Grace™ CPU 整合到一个平台中,该平台针对测试时间扩展推理进行了优化。与上一代 NVIDIA GB200 NVL72 相比,GB300 NVL72 的 AI 性能提升了 1.5 倍,能够探索多种解决方案,并将复杂任务分解为多个步骤,从而生成更高质量的响应。
其次,NVIDIA HGX B300 NVL16 为高效处理 AI 推理等复杂任务提供了突破性发展,与 Hopper 相比,其将大语言模型的推理速度提升 11 倍,计算能力提高了 7 倍,内存容量增加了 4 倍。
总而言之,Blackwell Ultra 增强了训练和测试时间扩展推理,为加速 AI 推理、AI Agent 和 Physical AI 等应用提供了强大支持。
对此,黄仁勋表示:「AI 技术已实现巨大飞跃,推理和 AI Agent 对计算性能的需求大幅提升。为此,我们设计了 Blackwell Ultra——它是一个多功能平台,可以高效执行预训练、后训练、推理任务」。
英伟达下一代 GPU 架构 Vera Rubin
英伟达自 1998 年起就一直以科学家的名字来命名其架构,这次亦不例外,即将推出的英伟达下一代 GPU 架构 Vera Rubin 就以发现暗物质的美国天文学家 Vera Rubin 来命名。

Vera Rubin
Vera Rubin 首次将自研 CPU 与 GPU 架构深度整合,标志着 NVIDIA 在 AI 计算架构上的又一突破,进一步拓展 AI 计算性能边界。
「基本上,除了底盘之外,其他一切都是全新的」,正如黄仁勋所言,作为 NVIDIA 史上首款完全自主设计的 CPU 架构,Vera 基于定制化 Arm 核心打造,它是一个只有 50 瓦的小型 CPU,但内存更大,带宽更高。据 NVIDIA 官方数据显示,相较于 Grace Blackwell,Vera 的计算性能直接提升 2 倍,此外,它还针对 AI 负载进行了深度优化。并通过优化指令集,显著降低通信延迟,使数据处理更加高效流畅,为 AI 训练和推理提供了强劲支撑。
与此同时,全新 Rubin GPU 也带来了 AI 计算的又一次飞跃。与 Vera 共同运行时,Rubin 推理计算可实现每秒 50 千万亿次浮点运算,较现有 Blackwell GPU 提升 2 倍以上。此外,Rubin 还支持高达 288GB 的高速内存,确保 AI 训练和推理能够高效处理庞大数据量。
黄仁勋还透露,Vera Rubin NVL144 将于明年下半年上市,而 2027 年下半年,NVIDIA 预计推出 Vera Rubin Ultra,它采用 NVL576 技术,由 250 万个部件组成,每个机架功率高达 600 千瓦,浮点运算次数将提升 14 倍,达到 15 百亿亿次浮点运算,实现极致的扩展。

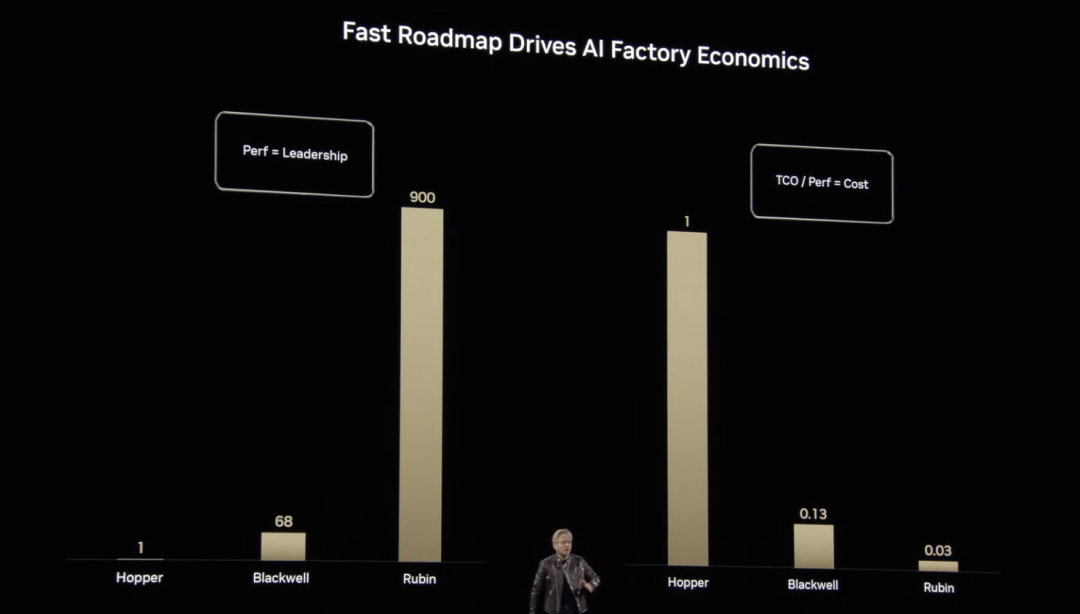
从 Grace Hopper 到 Blackwell,再到如今的 Rubin,黄仁勋向我们展示了 NVIDIA 在计算性能与成本优化方面的跨越式进步。相比基准计算能力,Hopper 纵向扩展的浮点运算次数是基准的 1 倍,Blackwell 提升至 68 倍,而 Rubin 更是跃升至 900 倍,实现了指数级增长。这一突破不仅显著降低了 AI 计算的单位成本,也使更复杂、更大规模的 AI 模型训练和推理变得高效可行。
英伟达将为构建 AI 工厂提供全流程服务
近年来,AI 领域的重心逐渐从训练大型模型转向推理模型的广泛应用,推理已成为推动 AI 经济快速增长的核心动力。这一转变不仅改变了技术格局,也对计算基础设施提出了全新要求——传统的数据中心并非为新的 AI 时代而设计,为了高效推进 AI 推理和部署进程,AI 工厂 (AI Factories) 应运而生。
AI Factories 不仅能存储和处理数据,还能大规模「生产智能」,将原始数据转化为实时洞察。NVIDIA 表示:「对专门打造 AI Factories 的企业进行投资,将在未来的市场中占据领先地位」。
为了支持这一变革,NVIDIA 创建了完整堆栈 AI Factories 的构建模块,并向合作伙伴提供以下关键组件:高性能计算芯片、先进网络技术、基础设施管理与工作负载编排、最大的 AI 推理生态系统、存储与数据平台、设计与优化蓝图、参考架构以及灵活的部署方式。

毫无疑问,在此之中,计算能力是 AI Factories 的核心支柱。从 Hopper 到 Blackwell 架构,NVIDIA 提供了世界上最强大的加速计算。通过基于 Blackwell Ultra 的 GB300 NVL72 机架级解决方案, AI Factories 能够实现高达 50 倍的 AI 推理输出,也为处理复杂任务提供了前所未有的性能支持。
参考资料:
https://mp.weixin.qq.com/s/ih-0LttWwNBYfyKPAhkEXQ



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)