
今天是2025年3月27日,星期四,北京,天气晴。
今天,我们继续回到R1推理模型以及多智能体的话题。
有三个有趣的实验报告。
分别是,推理模型思考后再思考会有效果提升(Think Twice: Enhancing LLM Reasoning by Scaling Multi-round Test-time Thinking)、推理模型训练数据的长度比难度更重要(Long Is More Important Than Difficult for Training Reasoning Models)以及多智能体之间协同会失效(Why Do Multi-Agent LLM Systems Fail)。
研究其实验方案以及一些发现,很有意义,但是实验结论依赖于实验环境设定本身,仅供参考。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、R1类推理模型训练跟推理性能的2个实验
关于推理模型思考模式新发现,
1、推理模型思考后再思考会有效果提升
看起来三思而后行,实则越来越慢,《Think Twice: Enhancing LLM Reasoning by Scaling Multi-round Test-time Thinking》(https://arxiv.org/pdf/2503.19855),
其思路是,利用先前的答案作为后续轮次的提示,迭代完善模型推理,关键提示为:{原问题提示}助手之前的回答是:

更具象化的现实就是:
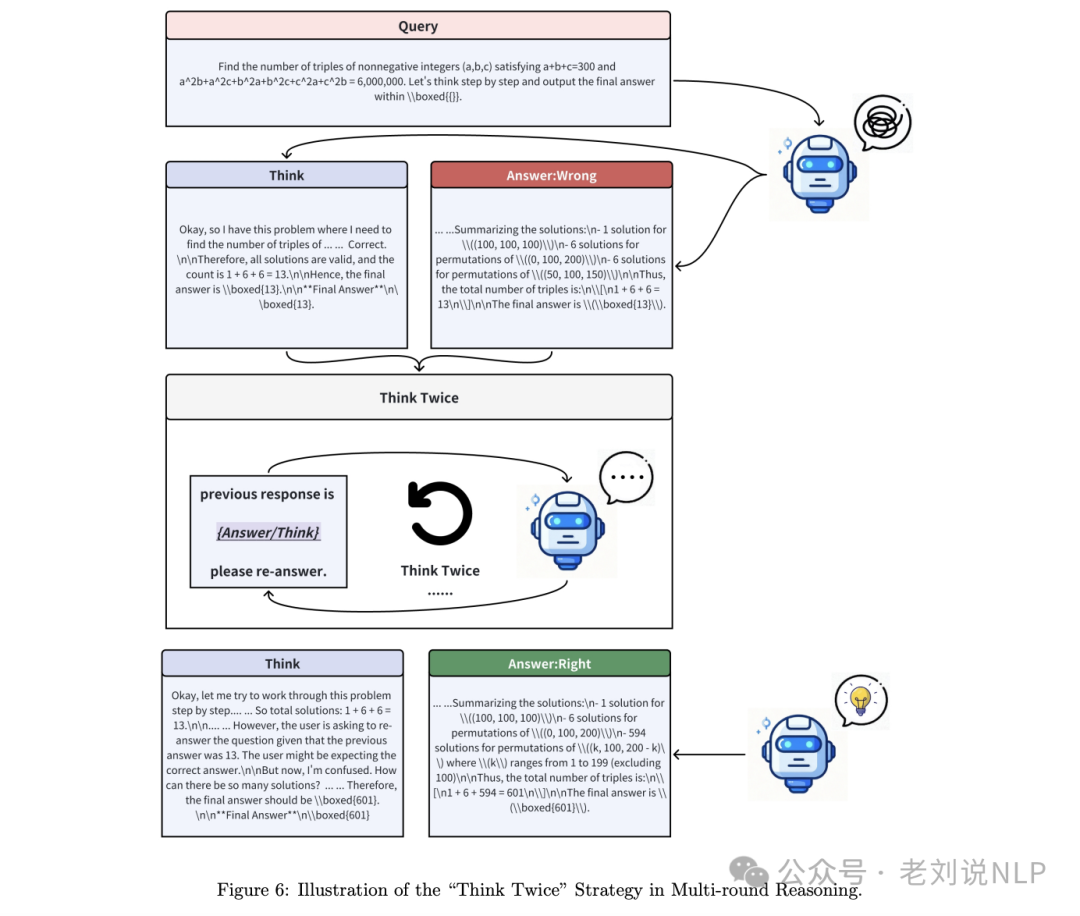
那么,效果如何?
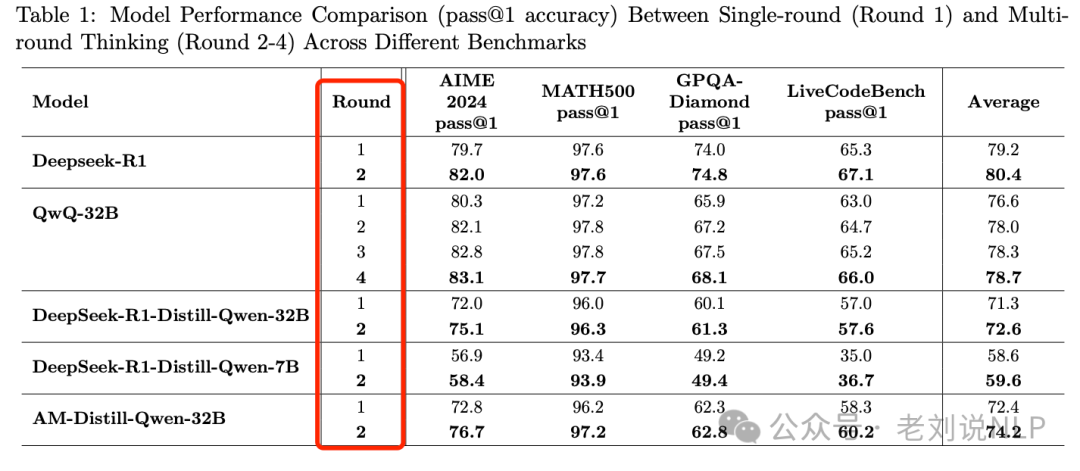
在QWQ-32B和DeepSeek-R1等多个模型上进行的广泛实验显示,在AIME 2024、MATH-500等各种基准测试中,性能持续提高。
例如,QWQ-32b在AIME 2024数据集上的准确率从80.3%(第一轮)提高到了82.1%(第二轮),而DeepSeek-R1的准确率也从79.7%提高到了82.0%。
但是问题来了,那么再次思考,是否会1)带来指令不遵循的问题,因为跟模型训练时候的数据不一致?2)现在单次think大家体感下来就已经很慢了,再加一次思考,会增加时间,落地意义不是很大?并且跟这个方向上有个相反的方向,就是做think时间的缩短,也可以关注。
2、推理模型训练数据的长度比难度更重要
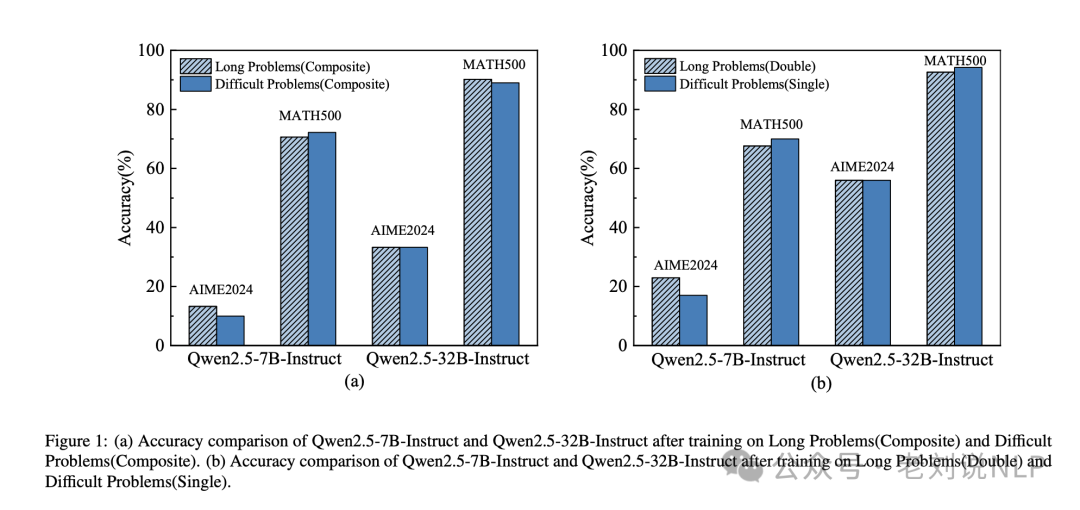
R1推理能力训练的一个实验,《Long Is More Important Than Difficult for Training Reasoning Models》(https://arxiv.org/pdf/2503.18069),通过实验发现,影响训练模型性能的主要是推理长度而不是问题难度;确定推理长度的缩放规律,表明模型性能随着推理数据长度的增长而以对数线性方式增长。
通过对Long1K数据集上的Qwen2.5-32B指令语言模型进行微调后,提出Long1K-32B,仅使用1000个训练样本,数学准确率达到95.6%,GPQA准确率达到71.1%,优于DeepSeek-R1-Distil-QWEN-32B。
https://huggingface.co/ZTss/LONG1
二、为什么多Agent会失效?
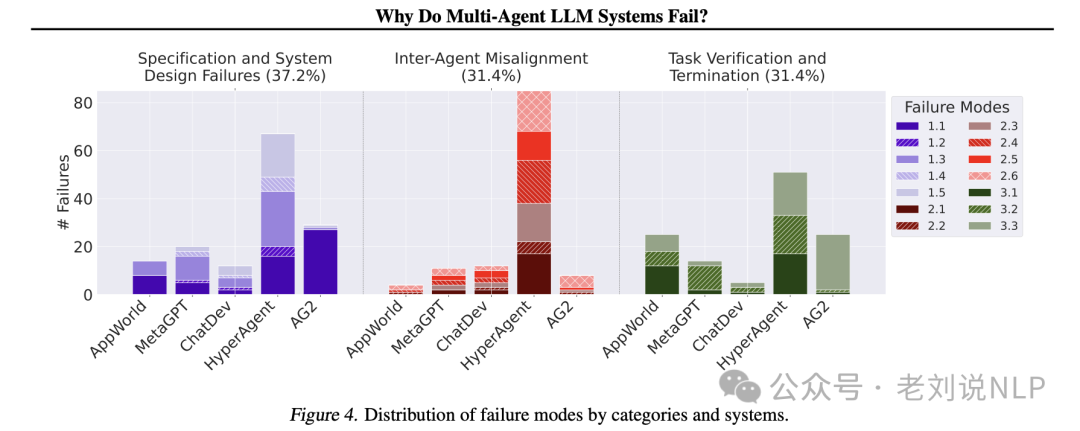
最近这个分析结论也很有趣。《Why Do Multi-Agent LLM Systems Fail?》(https://arxiv.org/pdf/2503.13657),通过对对5种流行MAS框架、150多个对话轨迹的分析,经过6位专业标注,确定3类共14种故障模式。
看几个点:
1、三类共14种故障模式具体定义
3类共14种故障模式如下,我们可以看看,以及其实际占比分布。

1)规范与系统设计故障
该类别包括由于系统架构设计缺陷、对话管理不佳、任务规范不明确或违反约束条件,以及代理角色和职责定义不充分或不遵守而引起的故障。有五种故障模式:
1.1 不遵守任务规范。未能遵循给定任务的指定约束或要求,导致次优或不正确结果。
1.2 不遵守角色规范。未能遵守分配角色的定义职责和约束,可能导致一个代理表现得像另一个代理。
1.3 步骤重复。在流程中对已完成步骤的不必要重复,可能导致任务完成过程中的延误或错误。
1.4 丢失对话历史。意外的上下文截断,忽略最近的互动历史,并回到之前的对话状态。
1.5 不了解终止条件。缺乏对应当触发代理互动终止的标准认可或理解,可能导致不必要的继续。
2)代理间不一致
该类别包括由于沟通无效、协作不佳、代理间的冲突行为以及逐渐偏离初始任务而产生的故障,有六种故障模式:
2.1 对话重置。意外或无正当理由的对话重新开始,可能丢失上下文和互动中取得的进展。
2.2 未能请求澄清。在遇到不清晰或不完整数据时无法请求额外信息,可能导致错误行动。
2.3 任务脱轨。偏离既定任务的预期目标或焦点,可能导致无关或无效的行动。
2.4 信息隐瞒。未能共享或传达代理拥有的重要数据或见解,如果共享可能会影响其他代理的决策。
2.5 忽略其他代理的输入。忽视或未能充分考虑系统中其他代理提供的输入或建议,可能导致次优决策或错失合作机会。
2.6 推理与行动不匹配。逻辑推理过程与代理实际采取的行动之间的差异,可能导致意外或不期望的行为。
3)任务验证与终止
该类别包括由于过早执行终止导致的失败,以及缺乏足够的机制来保证互动、决策和结果的准确性、完整性和可靠性,有三种故障模式:
3.1 过早终止。在所有必要信息尚未交换或目标尚未达成之前结束对话、互动或任务,可能导致不完整或不正确的结果。
3.2 未进行或未充分验证。(部分)省略对任务结果或系统输出的适当检查或确认,可能使错误或不一致未被检测到而传播。
3.3 错误验证。在迭代过程中未能充分验证或交叉核对关键信息或决策,可能导致系统中的错误或漏洞。
2、五种主流的agent框架及其实际表现
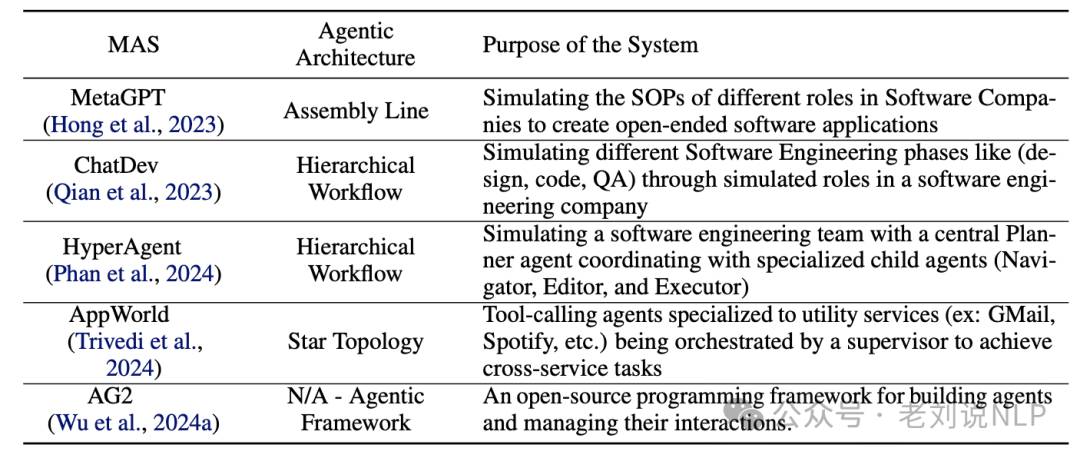
MetaGPT(https://arxiv.org/pdf/2308.00352,https://github.com/geekan/MetaGPT)。模拟了一家软件工程公司,涉及诸如编码员和验证员等智能体。目标是让具有领域专业知识的智能体(通过将不同角色的标准化操作程序编码进智能体提示中实现)协同解决一个用自然语言指定的编程任务。
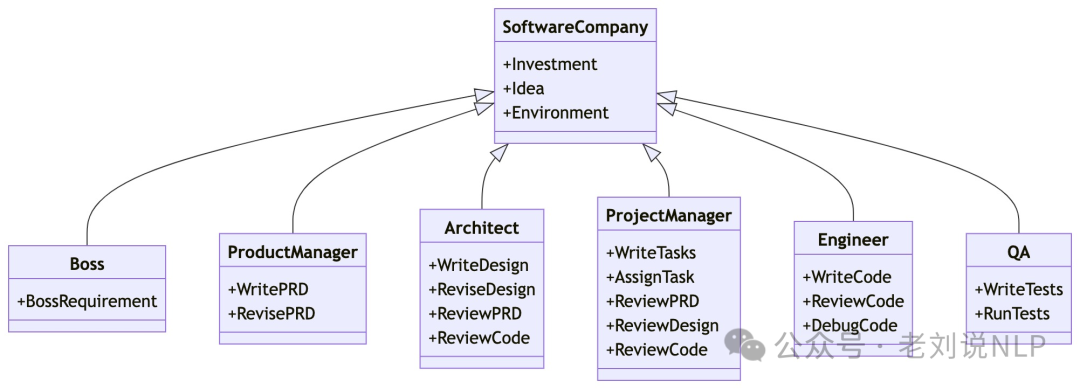
ChatDev(https://github.com/OpenBMB/ChatDev)。初始化不同的智能体,每个智能体假设在软件开发公司中担任常见角色。该框架将软件开发过程分为三个阶段:设计、编码和测试。每个阶段又细分为子任务,例如,测试分为代码审查(静态)和系统测试(动态)。

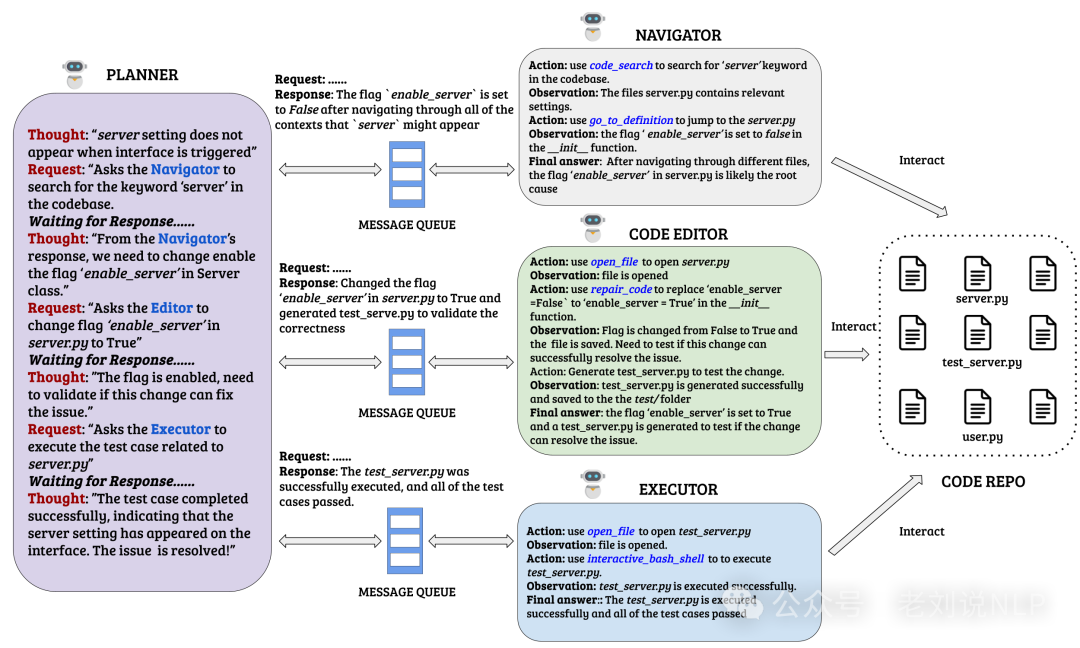
HyperAgent(https://github.com/FSoft-AI4Code/HyperAgent)。围绕四个主要智能体组织的软件工程任务框架:规划者、导航员、代码编辑器和执行者。
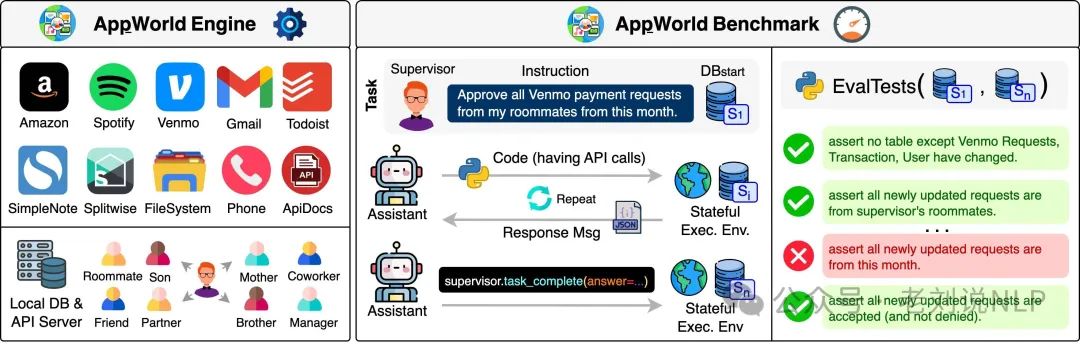
APPworld(https://arxiv.org/abs/2407.18901,https://github.com/StonyBrookNLP/appworld),引入了 AppWorld Engine,这是一个高保真执行环境,包含 9 个日常应用程序,可通过 457 个 API 进行操作,其中包含约 100 人生活在模拟世界中的数字活动,以及与自然、多样且具有挑战性的自主代理任务相关的基准,需要丰富且交互式的编码。
AG2(https://github.com/ag2ai/ag2),用于构建代理并管理它们的交互。使用此框架,可以构建各种灵活的对话模式,整合工具使用并自定义终止策略。
几个框架的实际表现如下:
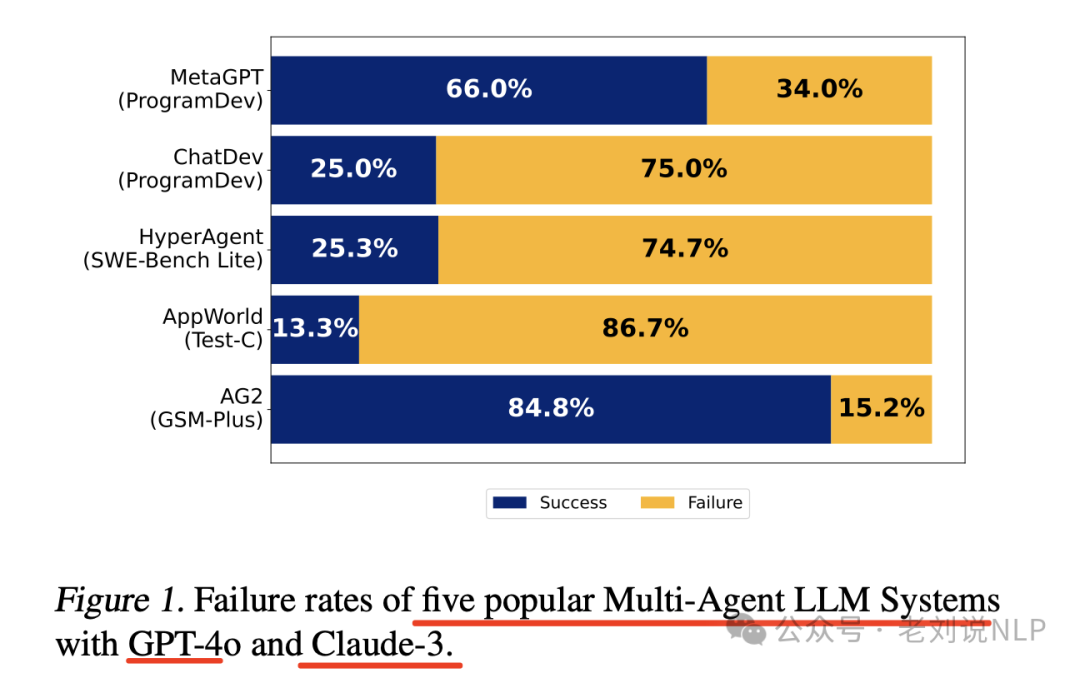
具体实效细节如下:
参考文献
1、https://arxiv.org/pdf/2503.13657
2、https://arxiv.org/pdf/2503.19855
3、https://arxiv.org/pdf/2503.18069
(文:老刘说NLP)