


0x00 前言
写在最前面,新年准备开写CUDA基础入门系列文章,面向CUDA入门,from Easy -> very Hard。其实这个想法早在24年3月份就有了,但是自己的笔记和材料一直都没有达到一个令人满意的状态,同时也包括自己对于CUDA的理解和应用,也还有待提高。于是,我决定将自己先前整理的CUDA-Learn-Notes笔记,继续扩展,经过将近一年的业余时间的努力,终于达到了我认为可以开写CUDA基础系列笔记的状态。材料准备好了,25年继续更新笔记,保持学习。第一篇开篇,简单写写CUDA-Learn-Notes里有什么(真心感谢我宝的支持,她说,那些时间本来应该是属于她的,我都没经过批准就花掉了~)
本文内容包括:
-
0x01 回顾与缺点
-
0x02 v3.0简介
-
0x03 基础环境推荐
-
0x04 PyTorch python bindings
-
0x05 HGEMM MMA Benchmark
-
0x06 FlashAttention-2 MMA Benchmark
-
0x07 200+ CUDA/Tensor Cores Kernels
-
0x08 100+ 技术博客推荐
-
0x09 总结
0x01 回顾与缺点
24年的这个时间点,我将自己的垃圾CUDA笔记(注释:是我垃圾,不是CUDA垃圾)整理成文章发布在知乎上,并同时开源到了xlite-dev/CUDA-Learn-Notes(
https://github.com/xlite-dev/CUDA-Learn-Notes)
仓库,相关的kernel包括warp reduce, block all reduce, dot-product, softmax, layer-norm, rms-norm, element-wise, sgemv和sgemm等,涵盖的CUDA优化技巧主要包括合并访存、向量化、bank conflicts reduce, warp shuffle, warp sgemv以及sgemm double buffers等等。上一篇文章见:
第一版的CUDA-Learn-Notes,收获了一些赞同和stars,但是显而易见,这版的笔记存在很多的问题,包括但不限于:没有提供数值验证的案例、只支持FP32数值类型不支持FP16/BF16/INT8/FP8等、纯CUDA/C++代码不方便Python/PyTorch用户对比性能和数值结果、没有Tensor Cores应用案例、没有TF32、没有HGEMM/FlashAttention的Tensor Cores实现、没有难度分级(从易到难)等等。
0x02 v3.0简介
为了让CUDA-Learn-Notes成为一份有学习意义的笔记,而不是仅仅是一个cu文件。过去一年的业余时间,我持续对CUDA-Learn-Notes进行了维护和更新。增加和很多内容,涵盖CUDA入门的常见主题,从非常简单到非常困难都有,并且充分考虑了Python/PyTorch的使用习惯,对每个主题的kernel实现都增加了PyTorch binding。所以,现在全名也改为: Modern CUDA Learn Notes with PyTorch for Beginners(https://github.com/xlite-dev/CUDA-Learn-Notes/tree/main?tab=readme-ov-file#cuda-kernel) 。目前也收获了2k stars~

-
200+ CUDA/Tensor Cores Kernels
CUDA-Learn-Notes将kernel按照不同的主题进行实现和整理,总共实现了接近200个CUDA kernels,包含CUDA Cores、Tensor Cores的应用,也包含大部分常见的数据类型,即FP32/TF32/FP16/BF16/FP8/INT8等;这些kernel有的非常简单(比如elementwise),也有的非常具有挑战性(比如手搓性能基本持平官方FA2的MMA版FlashAttention)。每个主题的工作流程如下:自定义CUDA kernel实现 -> PyTorch Python绑定 -> Python测试。当然,像HGEMM这些需要评估峰值性能的,我还提供了C++ bin的测试方式,避免引入额外的python开销。难度等级分为5个等级,分别为: 简单 ⭐️, 中等 ⭐️⭐️, 困难 ⭐️⭐️⭐️, 困难+ ⭐️⭐️⭐️⭐️和 困难++ ⭐⭐⭐️⭐️⭐️
简单 和 中等部分涵盖了如元素级操作、矩阵转置(mat_trans)、warp/block reduce、非极大值抑制(nms)、ReLU、GELU、Swish、ROPE、层归一化(layer-norm)、RMS归一化(rms-norm)、Online Softmax、点积(dot-prod)、词嵌入(Embedding)以及FP32、FP16、BF16和FP8的基本用法。 困难、 困难+ 和 困难++部分深入探讨了高级主题,主要集中在sgemv、sgemm、hgemv、hgemm和flash-attention等op上。这些部分还提供了大量使用纯Tensor Cores MMA PTX实现的kernels。
其中,HGEMM的最优实现达到了cuBLAS 98%~100%的性能;手搓FlashAttention-2 MMA的实现,在MMA Acc F32的情况下,能达到官方FA-2 95%~99%左右的性能。

并且在这个过程中,尝试了很多SRAM和registers优化的方式,最终诞生了一个对FA-2的改进方案,也就是:FFPA,O(1) SRAM复杂度,将headdim扩展到1024,并且保持80%以上的TFLOPS利用率,比SDPA EA快2~3x~。因为,FFPA工程上的思路和FA2以及SDPA EA都有差别,并且对FA有进一步拓展的意义,因此从CUDA-Learn-Notes中拎出来,单独形成一个repo进行维护。鉴于headdim>256使用的场景很少,FFPA目前仅提供一些实验性的kernel和benchmark用于参考(反正性能确实不错就是了)。感兴趣的同学,请跳转GitHub链接:(本文不展开介绍FFPA,后续会单独开文章介绍)
-
100+ 技术博客推荐
除了我自己写的CUDA笔记和示例外,我还整理了100+自己非常喜欢的技术博客,从这些博客中,我学习到了非常多有用的东西。每每看完,深感惭愧,写得真好~因此,也在CUDA-Learn-Notes中整理出来推荐给大家。这些技术博客,我都按照主题进行了分类,大家可以按需食用。比如:

单张截图放不下全部内容,感兴趣的同学可以到CUDA-Learn-Notes中查阅:
0x03 基础环境推荐
-
Python >= 3.10
-
PyTorch >= 2.4.0, CUDA >= 12.4
-
Recommended: PyTorch 2.5.1, CUDA 12.5
-
Docker: http://https://nvcr.io/nvidia/pytorch:24.10-py3
直接用NV的官方镜像吧,省事,推荐:http://https://nvcr.io/nvidia/pytorch:24.10-py324.10-py3,CUDA-Learn-Notes中所有的Kernel均在该环境中测试通过。特别不推荐CUDA 11的环境,FP8以及最新的一些MMA指令,在CUDA 11没法玩。都2025年了,用CUDA 12+吧,兄弟们~
0x04 PyTorchPython bindings
本小节讲讲CUDA-Learn-Notes的workflow。CUDA-Learn-Notes将kernels按照主题进行划分,并且对每个主题的kernel实现,都进行了PyTorch python binding,可以直接使用python脚本进行性能和数值验证。比如以下这个block all reduce的示例:
//packed_type,acc_type,th_type,element_type,n_elements_per_pack,out_typeTORCH_BINDING_REDUCE(f32, f32,torch::kFloat32, float, 1,float)TORCH_BINDING_REDUCE(f32x4, f32,torch::kFloat32, float, 4,float)TORCH_BINDING_REDUCE(f16, f16,torch::kHalf, half, 1,float)TORCH_BINDING_REDUCE(f16, f32,torch::kHalf, half, 1,float)TORCH_BINDING_REDUCE(f16x2, f16,torch::kHalf, half, 2,float)TORCH_BINDING_REDUCE(f16x2, f32,torch::kHalf, half, 2,float)TORCH_BINDING_REDUCE(f16x8_pack, f16,torch::kHalf, half, 8,float)TORCH_BINDING_REDUCE(f16x8_pack, f32,torch::kHalf, half, 8,float)TORCH_BINDING_REDUCE(bf16, bf16,torch::kBFloat16, __nv_bfloat16, 1,float)TORCH_BINDING_REDUCE(bf16, f32,torch::kBFloat16, __nv_bfloat16, 1,float)TORCH_BINDING_REDUCE(bf16x2, bf16,torch::kBFloat16, __nv_bfloat16, 2,float)TORCH_BINDING_REDUCE(bf16x2, f32,torch::kBFloat16, __nv_bfloat16, 2,float)TORCH_BINDING_REDUCE(bf16x8_pack, bf16,torch::kBFloat16, __nv_bfloat16, 8,float)TORCH_BINDING_REDUCE(bf16x8_pack, f32,torch::kBFloat16, __nv_bfloat16, 8,float)TORCH_BINDING_REDUCE(fp8_e4m3, f16,torch::kFloat8_e4m3fn,__nv_fp8_storage_t,1,float)TORCH_BINDING_REDUCE(fp8_e4m3x16_pack,f16,torch::kFloat8_e4m3fn,__nv_fp8_storage_t,16,float)TORCH_BINDING_REDUCE(fp8_e5m2, f16,torch::kFloat8_e5m2, __nv_fp8_storage_t,1,float)TORCH_BINDING_REDUCE(fp8_e5m2x16_pack,f16,torch::kFloat8_e5m2, __nv_fp8_storage_t,16,float)TORCH_BINDING_REDUCE(i8, i32,torch::kInt8, int8_t, 1,int32_t)TORCH_BINDING_REDUCE(i8x16_pack, i32,torch::kInt8, int8_t, 16,int32_t)这个实例中,包含了大部分常见的数据类型。不同于已有的CUDA笔记几乎不谈FP16和Tensor Cores的情况,CUDA-Learn-Notes在FP16和Tensor Cores上花了大量的精力,提供了如HGEMM, FlashAttention-MMA等大量的案例。并且,对于BF16/FP8等数据类型,也提供了应用案例,如本示例中的block all reduce,支持FP32/FP16/BF16/FP8/INT8等数据类型。经过了PyTorch binding后,数值结果和性能的验证非常简单,直接跑python脚本就行,不需要去配置C++编译环境。
# 只测试Ada架构 不指定默认编译所有架构 耗时较长: Volta, Ampere, Ada, Hopper, ...exportTORCH_CUDA_ARCH_LIST=Ada
python3 block_all_reduce.py日志输出如下:(block all reduce示例)
-------------------------------------------------------------------------------- S=4096, K=4096
out_f32f32: -2295.19458008 , time:0.10227132ms
out_f32x4f32: -2295.19702148 , time:0.03361320ms
out_f32f32_th: -2295.19946289 , time:0.02290916ms
--------------------------------------------------------------------------------
out_f16f16: -2293.83764648 , time:0.10097337ms
out_f16f32: -2296.36425781 , time:0.10095334ms
out_f16x2f32: -2297.93896484 , time:0.03533483ms
out_f16x2f16: -2297.96386719 , time:0.03572583ms
out_f16x8packf16: -2299.68701172 , time:0.01311255ms
out_f16x8packf32: -2296.36645508 , time:0.01308966ms
out_f16f16_th: -2296.00000000 , time:0.01445580ms
--------------------------------------------------------------------------------
out_bf16bf16: -2264.30468750 , time:0.10450244ms
out_bf16f32: -2293.59399414 , time:0.10095382ms
out_bf16x2f32: -2299.56005859 , time:0.03533602ms
out_bf16x2bf16: -2284.02343750 , time:0.03620267ms
out_bf16x8packf32: -2290.28173828 , time:0.01310396ms
out_bf16x8packbf16: -2282.46875000 , time:0.01368093ms
out_bf16bf16_th: -2288.00000000 , time:0.01442218ms
--------------------------------------------------------------------------------
out_f8e4m3f16: -2332.72070312 , time:0.10321760ms
out_f8e4m3x16packf16: -2329.65625000 , time:0.01123261ms
out_f8e4m3f16_th: -2330.00000000 , time:0.01445007ms
--------------------------------------------------------------------------------
out_f8e5m2f16: -2035.82812500 , time:0.10325360ms
out_f8e5m2x16packf16: -2034.17187500 , time:0.01119351ms
out_f8e5m2f16_th: -2036.00000000 , time:0.01442766ms
--------------------------------------------------------------------------------
out_i8i32: -2746 , time:0.10370731ms
out_i8x16packi32: -2746 , time:0.01133108ms
out_i8i32_th: -2746 , time:0.36144137ms
--------------------------------------------------------------------------------主打一个上手就能跑,跑完再读读kernel的实现代码,自己改改跑跑,自然就学会怎么写block all reduce了。同样的HGEMM和FlashAttention也是如此。
0x05 HGEMM Benchmark
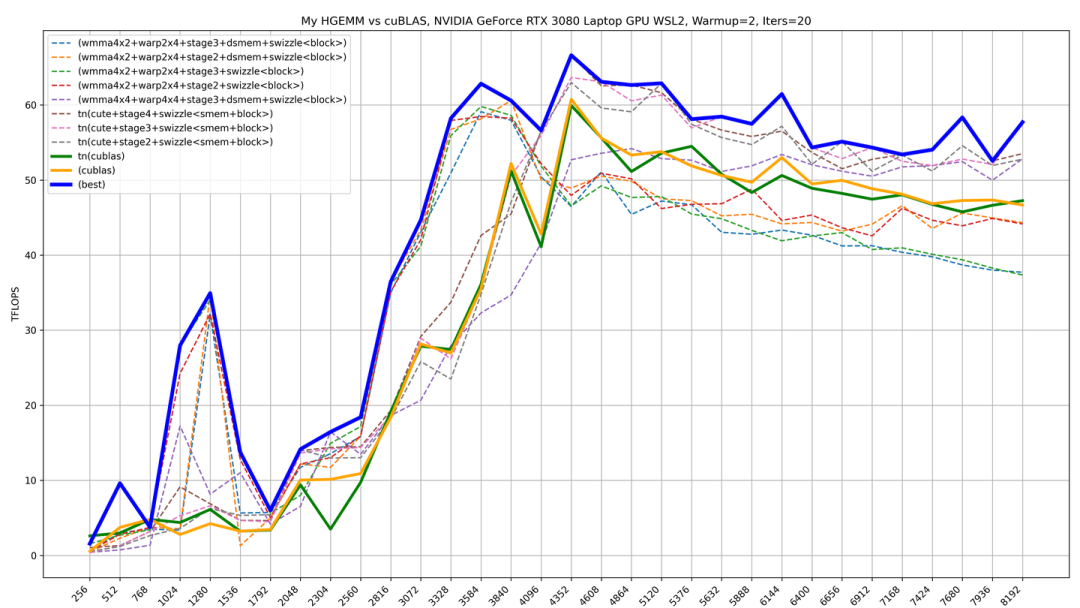
HGEMM是CUDA优化永远绕不开的八股,不动手写一写,总觉得不得劲。CUDA-Learn-Notes中也提供了大量的HGEMM + Tensor Cores MMA的实现。最优实现的性能,能达到cuBLAS 98%~100%的性能。实现的大量的特性,大致如下:

目前CUDA-Learn-Notes中提供的HGEMM Kernels,实现了一些主要的特性包括:Loop over K, Tile Block, Tile MMAs(more threads), Tile Warps(more values), Pack LDST, SMEM Padding, SMEM Swizzle, Block Swizzle, Warp Swizzle, Mulit-Stages, Registers Double Buffers, NN/TN Layout, Collective Store(Warp shuffle & registers reuse)等。实现的HGEMM CUDA Kernel包括:
voidhgemm_naive_f16(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_sliced_k_f16(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_8x8_sliced_k_f16x4(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_8x8_sliced_k_f16x4_pack(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_8x8_sliced_k_f16x4_bcf(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_8x8_sliced_k_f16x4_pack_bcf(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_8x8_sliced_k_f16x8_pack_bcf(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_8x8_sliced_k_f16x8_pack_bcf_dbuf(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_8x8_sliced_k16_f16x8_pack_dbuf(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_8x8_sliced_k16_f16x8_pack_dbuf_async(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_8x8_sliced_k32_f16x8_pack_dbuf(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_8x8_sliced_k32_f16x8_pack_dbuf_async(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_16x8_sliced_k32_f16x8_pack_dbuf(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_t_16x8_sliced_k32_f16x8_pack_dbuf_async(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_cublas_tensor_op_nn(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_cublas_tensor_op_tn(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_wmma_m16n16k16_naive(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_wmma_m16n16k16_mma4x2(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_wmma_m16n16k16_mma4x2_warp2x4(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_wmma_m16n16k16_mma4x2_warp2x4_dbuf_async(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_wmma_m32n8k16_mma2x4_warp2x4_dbuf_async(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_wmma_m16n16k16_mma4x2_warp2x4_stages(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_wmma_m16n16k16_mma4x2_warp2x4_stages_dsmem(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_wmma_m16n16k16_mma4x2_warp4x4_stages_dsmem(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride); voidhgemm_wmma_m16n16k16_mma4x4_warp4x4_stages_dsmem(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_mma_m16n8k16_naive(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_mma_m16n8k16_mma2x4_warp4x4(torch::Tensora,torch::Tensorb,torch::Tensorc);voidhgemm_mma_m16n8k16_mma2x4_warp4x4_stages(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_mma_m16n8k16_mma2x4_warp4x4_stages_dsmem(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_mma_m16n8k16_mma2x4_warp4x4x2_stages_dsmem(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_mma_m16n8k16_mma2x4_warp4x4x2_stages_dsmem_x4(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_mma_m16n8k16_mma2x4_warp4x4x2_stages_dsmem_rr(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_mma_m16n8k16_mma2x4_warp4x4_stages_dsmem_tn(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_mma_stages_block_swizzle_tn_cute(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_mma_m16n8k16_mma2x4_warp4x4x2_stages_dsmem_swizzle(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);voidhgemm_mma_m16n8k16_mma2x4_warp4x4x2_stages_dsmem_tn_swizzle_x4(torch::Tensora,torch::Tensorb,torch::Tensorc,intstages,boolswizzle,intswizzle_stride);我甚至还顺手搓了一下SGEMM TF32,但是性能被cuBLAS吊打,寄。这里贴一个HGEMM的性能数据,更多benchmark请到xlite-dev/CUDA-Learn-Notes(https://github.com/xlite-dev/CUDA-Learn-Notes/tree/main/kernels/hgemm)查看。
0x06 FlashAttention-2 MMA Benchmark
作为Modern CUDA-Learn-Notes,又怎么能少了FlashAttention呢?没错,在CUDA-Learn-Notes中,我还用Tensor Cores MMA PTX手搓了FlashAttention-1(Split-KV)和FlashAttention-2(Split-Q),并且在这个过程中,尝试了很多SRAM节省和registers优化的方式。最优的实现,在MMA Acc F32的情况下,能达到FA-2官方实现95%~98%左右的性能。而且我还实现MMA Acc F16版本,在4090等机器上,能达到1.5x FA-2原生性能,but,可能溢出,导致效果直接寄掉。(PS:FFPA中实现了混合MMA Acc精度,Q@K^T MMA Acc F32 + P@V MMA Acc F16,既能保证精度,也能有1.2x~1.3x的性能收益)
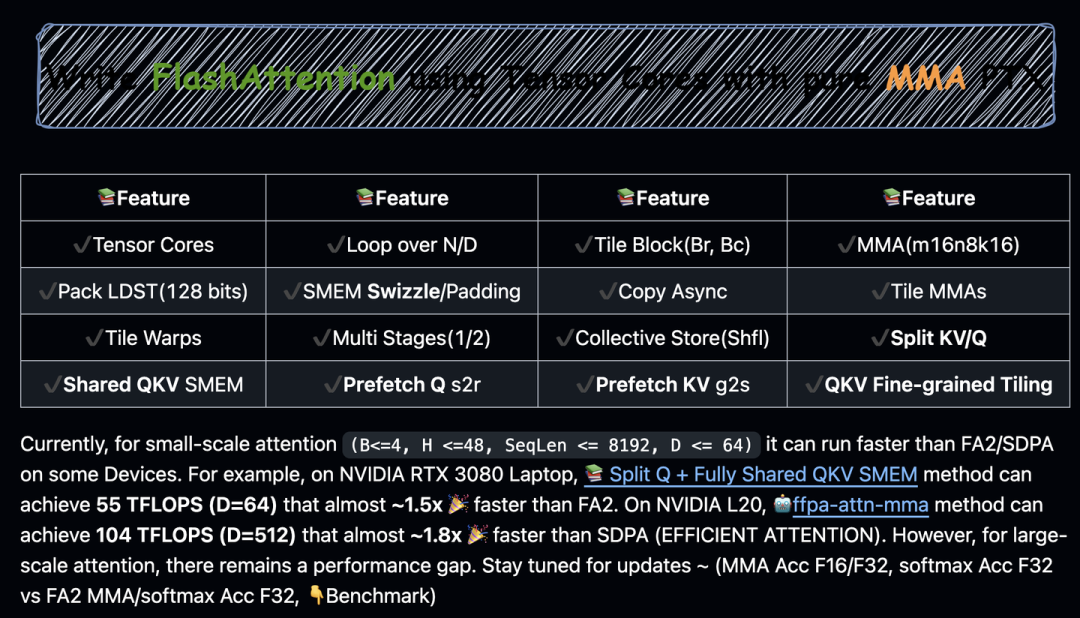
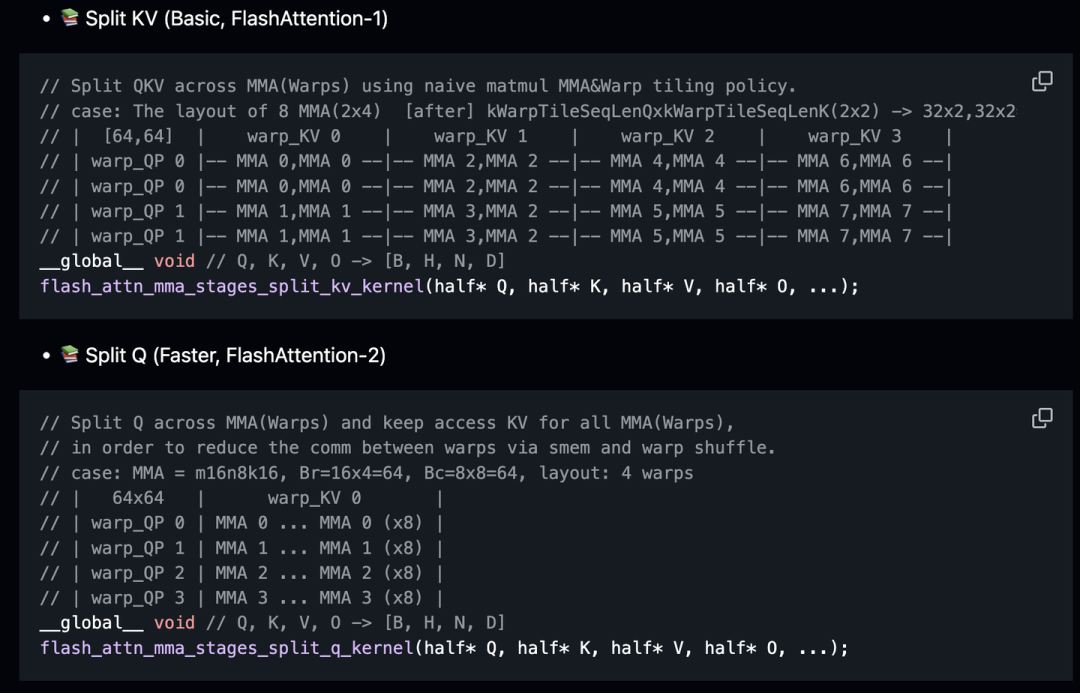
FlashAttention-2 MMA支持的特性包括,Multi-Stages, Tile MMA, Tile Warp, Shared KV SMEM,Fully Shared QKV SMEM,Prefetch Q s2r,Prefetch K/V g2s,QKV Fine-grained Tiling, Collective Store等。

目前,对于小规模注意力机制(B≤4,H≤48,SeqLen≤8192,D≤64),在某些设备上它的运行速度可以超过FA2/SDPA。例如,在NVIDIA RTX 3080笔记本电脑上, Split Q + Fully Shared QKV SMEM方法可以达到55 TFLOPS(当D=64时),这几乎比FA2快约1.5倍(MMA Acc F16) 。在NVIDIA L20上, ffpa-attn-mma方法可以达到104 TFLOPS(当D=512时),这几乎比SDPA(EFFICIENT ATTENTION)快约1.8倍 。
FlashAttention-2 MMA的实现过程中,尝试了很多SRAM节省和registers优化的方式。这里思考的一个核心问题是:为什么FlashAttention的headdim会被SRAM限制住,而通用HGEMM/GEMM的K维度确不会(K可无限大,只要显存放得下)?这个思考和尝试的最终结果就是 FFPA: Yet antother Faster Flash Prefill Attention with O(1)⚡️GPU SRAM complexity for large headdim (https://github.com/xlite-dev/ffpa-attn-mma),FFPA将FA-2的SRAM复杂度直接打成了O(1),将headdim扩展到了1024(还可以更大)。除了FFPA外,还有很多其他的尝试,大致如下:

0x07 200+ CUDA Kernels (Easy -> Hard++)
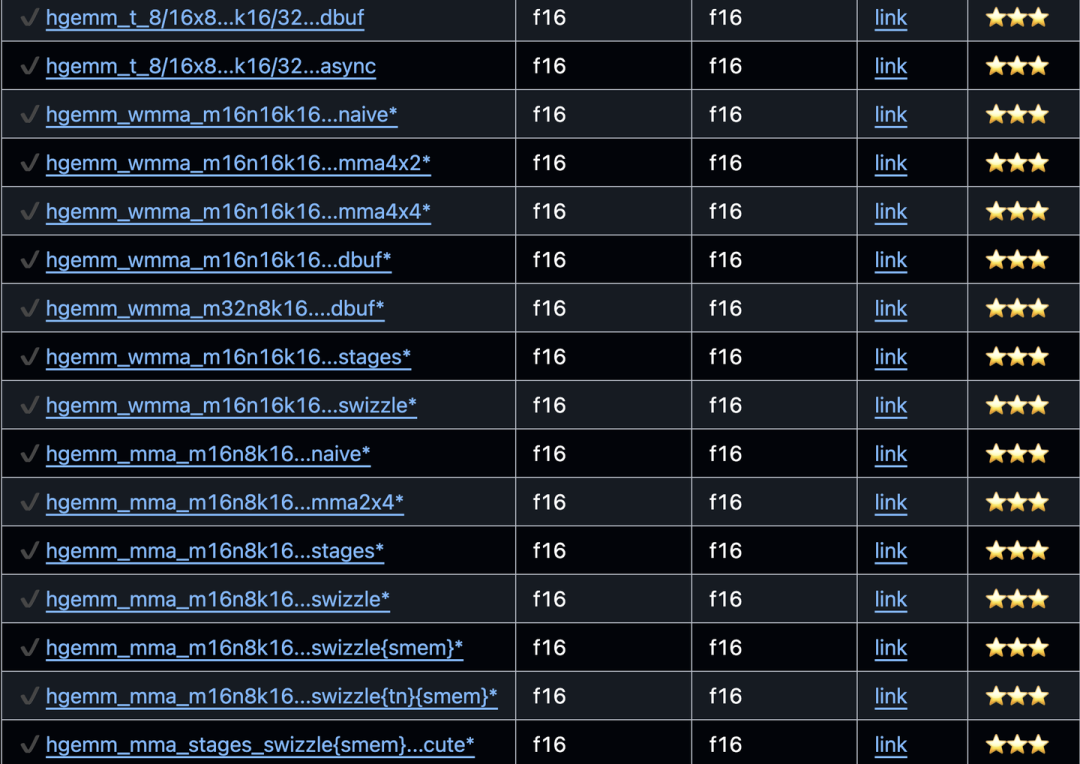
CUDA-Learn-Notes将kernel按照不同的主题进行实现和整理,总共实现了接近200个CUDA kernels,包含CUDA Cores、Tensor Cores的应用,也包含大部分常见的数据类型,即FP32/TF32/FP16/BF16/FP8/INT8等;这些kernel有的非常简单(比如elementwise),也有的非常具有挑战性(比如手搓性能基本持平官方FA2的MMA版FlashAttention)。每个主题的工作流程如下:自定义CUDA kernel实现 -> PyTorch Python绑定 -> 运行测试。难度等级分为5个等级,分别为: 简单 ⭐️ 中等 ⭐️⭐️ 困难 ⭐️⭐️⭐️ 困难+ ⭐️⭐️⭐️⭐️ 困难++ ⭐⭐⭐️⭐️⭐️
简单 和 中等部分涵盖了如元素级操作、矩阵转置(mat_trans)、warp/block reduce、非极大值抑制(nms)、ReLU、GELU、Swish、层归一化(layer-norm)、RMS归一化(rms-norm)、在线Softmax、点积(dot-prod)、嵌入(Embedding)以及FP32、FP16、BF16和FP8的基本用法。 困难、 困难+ 和 困难++部分深入探讨了高级主题,主要集中在sgemv、sgemm、hgemv、hgemm和flash-attention等op上。这些部分还提供了大量使用纯Tensor Cores MMA PTX实现的kernels。
题内话,如果是为了面试, 简单 ⭐️ 中等 ⭐️⭐️ 困难 ⭐️⭐️⭐️ 这三个级别的难度基本够用了, 困难 ⭐️⭐️⭐️中包括了HGEMM八股各种实现以及Tensor Cores MMA的应用。 困难+ ⭐️⭐️⭐️⭐️则是FlashAttention-2 MMA的各种版本, 困难++ ⭐⭐⭐️⭐️⭐️则是FFPA的MMA kernels,毕竟性能确实比SDPA EA好很多,给5个星应该不过分。因为Kernels数量接近200,因此每个难度级别仅截图部分作为展示,完整列表,请跳转CUDA-Learn-Notes(https://github.com/DefTruth/CUDA-Learn-Notes?tab=readme-ov-file)仓库。
-
Easy ⭐️ & Medium ⭐️⭐️



-
Hard ⭐⭐⭐️

-
Hard+ ⭐️⭐️⭐️⭐️ & Hard++ ⭐️⭐️⭐️⭐️⭐️

0x08 100+ 技术博客推荐
除了我自己写的CUDA笔记和示例外,我还整理了100+自己非常喜欢的技术博客,从这些博客中,我学习到了非常多有用的东西。每每看完,深感惭愧,写得真好~因此,也在CUDA-Learn-Notes中整理出来推荐给大家。这些技术博客,我都按照主题进行了分类,大家可以按需食用。比如:


0x09 总结
本文对CUDA-Learn-Notes v3.0升级带来的新特性进行了综合介绍,CUDA-Learn-Notes v3.0包括200+ CUDA/Tensor Cores Kernels,PyTorch python bindings,100+ LLM/CUDA技术博客推荐,HGEMM-MMA和FlashAttention-2 MMA高性能实现以及FFPA对FlashAttention-2的扩展(1K headdim~),相关repo链接见:
CUDA-Learn-Notes
FFPA: 1.8x~3x↑ faster vs SDPA EA
老铁们,欢迎来star 啊~
为了感谢读者的长期支持,今天我们将送出三本由 机械工业出版社 提供的:《AIGC驱动工业智能设备 系统设计与行业实践》。点击下方抽奖助手参与抽奖。没抽到的小伙伴可以使用下方链接购买。
编辑推荐
1.简单易懂:将复杂抽象的原理,以通俗易懂的语言和贴近生活的小案例进行讲解,降低学习门槛。2.实际性:所有应用与案例均源自真实的行业需求,系统设计过程紧贴实际工作场景,具备很强的落地性。3.前瞻性:在AIGC工业应用尚处于发展初期的背景下,本书结合行业特性与技术趋势,提供具有前瞻视角的解决方案。
《AIGC驱动工业智能设备 系统设计与行业实践》抽奖链接

– The End –

长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
(文:GiantPandaCV)