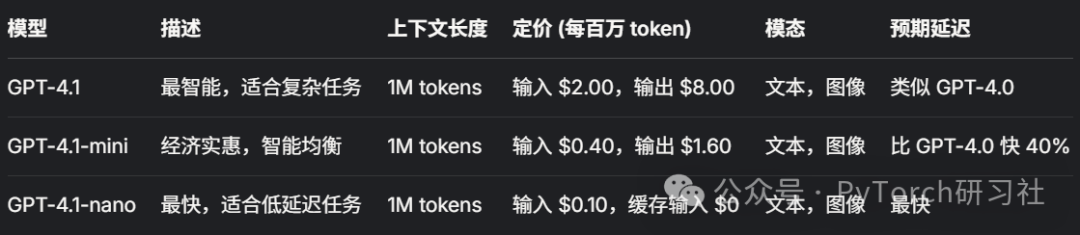
OpenAI 最近发布了 GPT-4.1 系列,包括 GPT-4.1、GPT-4.1-mini 和 GPT-4.1-nano,分别针对高智能、平衡和低延迟任务。GPT-4.1 支持 100 万 token 的上下文窗口,特别适合处理复杂任务。
GPT-4.1 在 Multilingual MMLU 智能测试中得分最高,但延迟也最高;GPT-4.1-nano 则在低延迟任务中表现最佳,适合如分类和自动补全的应用。
老实说,我真的不喜欢 OpenAI 官方发的这个比较图:完全没有坐标刻度,可以说是几乎完全没有参考价值。
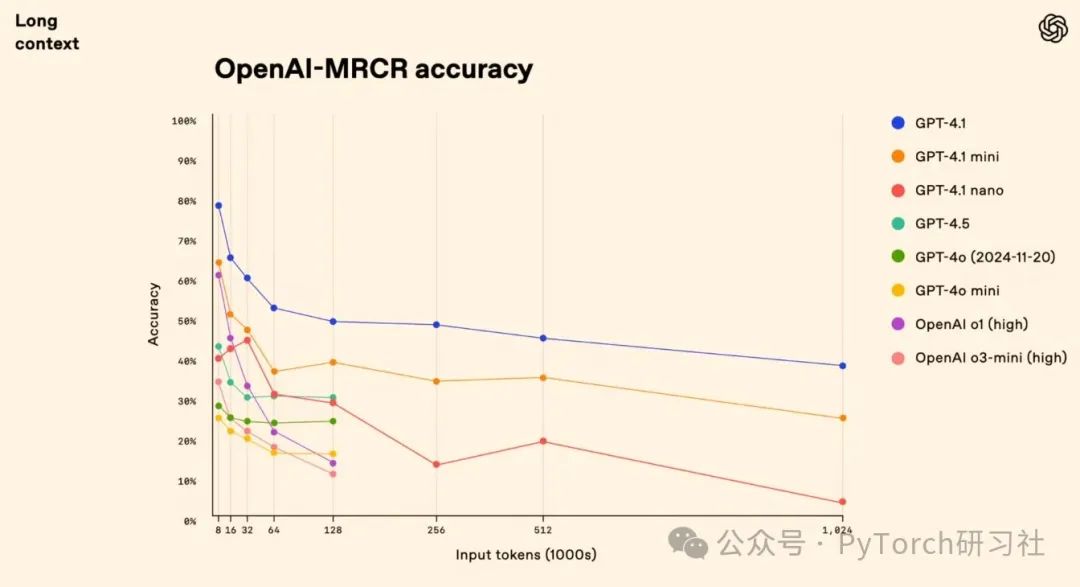
OpenAI-MRCR 基准测试显示,GPT-4.1 在长上下文任务中表现强劲,特别是在处理 100 万 token (约 75 万字)时保持高准确率,显著提升了信息处理能力。
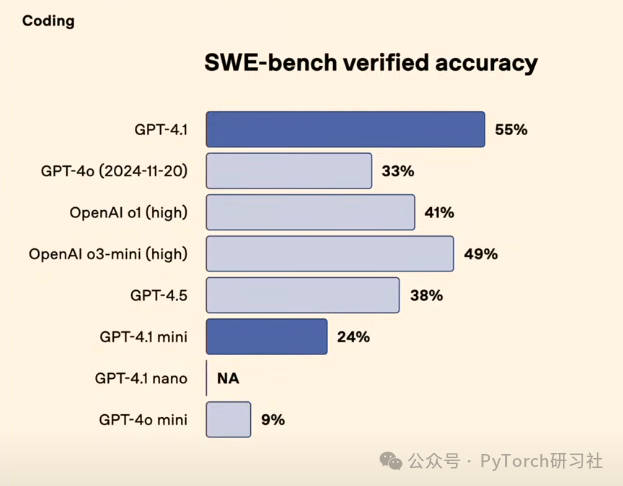
在 SWE-Bench 验证准确率中,GPT-4.1 达到 55%,远超 GPT-4o (33%) 和 OpenAI o1 (高) (41%)。
它还能生成多种编程语言的高质量代码,在 Aider 的多语言测试中达到 52% 准确率。
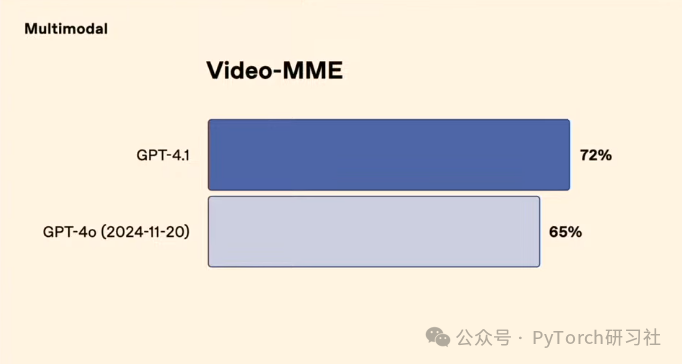
在 Video-MME 测试中,GPT-4.1 得分 72%,优于 GPT-4o (65%),显示其在视频理解方面的领先。
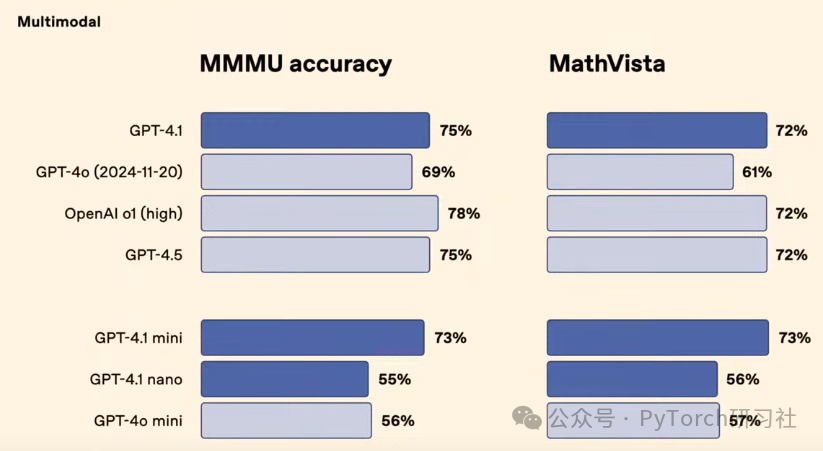
在其他多模态基准测试中 GPT-4.1 极具竞争力(75%),GPT-4.1 mini 在多模态推理和智能方面也表现出色(73%)。
GPT-4.1 mini 是多模态推理任务的推荐模型。
(文:PyTorch研习社)