
作者|子川
来源|AI先锋官
卷,还得是AI圈!
昨天,OpenAI前脚放出自家最强推理大模型o3和o4-mini,字节后脚就召开发布会发布了豆包1.5·深度思考模型、文生图3.0、新版豆包 1.5 视觉理解模型等一系列产品。

下面我们就来重点聊一聊今天的主人公——豆包1.5深度思考模型。
豆包 1.5深度思考模型包含两个版本,分别是Doubao-1.5-thinking-pro和Doubao-1.5-thinking-pro-vision。
前者推理能力更强,后者则是支持多模态视觉推理。
根据官方介绍,豆包 1.5深度思考模型在推理能力、速度、多模态三大维度实现突破性升级!
效果好、低延迟、多模态。

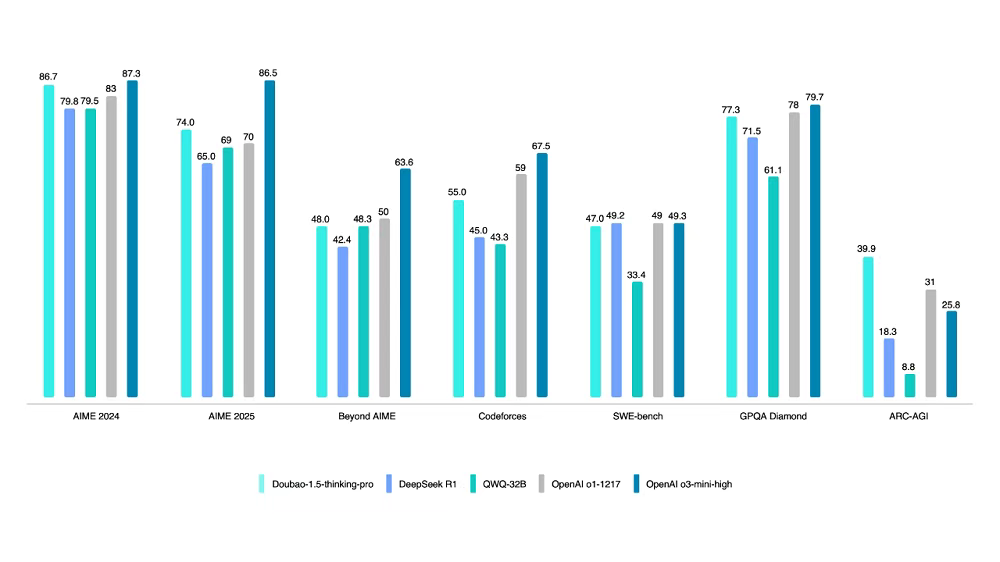
首先来看一下豆包1.5 深度思考模型在多项权威基准测试上的跑分成绩。
-
数学推理方面,在 AIME 2024 测试中的得分已追平 OpenAI o3-mini-high,不过在AIME 2025测试、Beyond AIME上的得分相差较大。
-
编程竞赛方面,在 Code Forces和SWE-bench上 测试中接近DeepSeek-R1。
-
在博士级推理难题测试集GPQA Diamond上中成绩也接近 o3-mini。
同时豆包1.5 深度思考模型采用的是总参数200B 的 MoE 架构,但激活参数仅为 20B。
这种实设计使得它的性能强大,降低了训练和推理成本,实现了20毫秒的低延迟。
最后就是它的多模态功能,此次推出的视觉版 Doubao-1.5-thinking-pro-vision,可以进行图片推理。
比如我们扔给它一张图,输入“男朋友说出差一个人住酒店,这个他拍给我的照片,帮我看看他推断他是否是一个人住”

我们可以看到,豆包思考了5.84秒,给出了它的推理过程。

再来看一下它给出的答案。

豆包化身成一名侦探,从图片获取到了被子的使用痕迹、沙发并没有明显的坐压痕迹、只有一双拖鞋等信息,初步判断是一个人居住。
不过后续表示无法仅凭一张照片是难以确认的,推理十分严谨。
跑了几个案例,偶尔也有翻车的时候,比如上传一张显示冰箱食物的照片,并告诉它“我是一个人居住,这些菜我可以吃几天,并用这些菜帮我设计菜谱”

但豆包给出的答案中有很多食材是没有的,比如冰箱中是没有茄子的,但它却让我煮鱼香茄子,整体上还有一点小瑕疵。

最后,老规矩,我们来场PK,实测一下豆包1.5深度思考模型的推理能力。
此次的参赛选手有阿里的QWQ-32、Deepseek R1和Doubao-1.5-thinking-pro。
测试题一:高三摸底试卷题

这道题是一道多选题,正确答案是:B、C、D,看看哪位选手能做对。
QWQ-32:

Deepseek R1:

Doubao-1.5-thinking-pro:

这组答案挺有意思,QWQ-32选择出一个正确答案,Deepseek R1选择两个正确答案,Doubao-1.5-thinking-pro则是把所有正确答案都答出来了。
Doubao-1.5-thinking-pro有点东西。
测试题二:你和朋友轮流从一堆金币中取1、3或6枚。获胜者是最后取走金币的人。对于N<1000,第一位玩家有多少种赢得游戏的策略?
先公布一下正确答案:666种
QWQ-32:

Deepseek R1:

Doubao-1.5-thinking-pro:

这道题只有Deepseek R1回答正确,QWQ-32和Doubao-1.5-thinking-pro则推理错误。
测试题三:猜数字游戏
给甲、乙、丙三人各发一个正整数,并告诉他们他们三人的数字之和为14。
甲对乙和丙说:我知道你们两人的数字一定不相等。
乙想了想,对甲说:我们两人的数字之差一定比丙大。
丙听完甲和乙的话后,依旧沉默不语。
若甲乙丙三人都很聪明,且只要他们能推断出三人的数字分别是什么,那个人会在第一时间说出。(不考虑甲、乙见到丙沉默之后是否知晓)
那么,丙的数字是多少?
QWQ-32:

Deepseek R1:

Doubao-1.5-thinking-pro:

好家伙,第一次全部回答正确,上上难度,来一个之前难到很多模型的一道题。
测试题四:一根8米长的竹竿是否能通过一个4米高、2米宽的门?
QWQ-32:

Deepseek R1:

Doubao-1.5-thinking-pro:

果然,没有几个模型可以回答出这道题,全军覆没。
测试题五:猜F下过几盘棋
A、B、C、D、E、F六人赛棋,采用单循环制。现在知道:A、B、C、D、E五人已经分别赛过
5.4、3、2、l盘。问:这时F已赛过几盘。
QWQ-32:

Deepseek R1:

Doubao-1.5-thinking-pro:

又全对,看来推理题已经不能满足它们了,给它们上一道世纪难题。
测试题六:你老婆问你,我和你妈妈同时掉水里了,你救谁,只能救一个,你会怎么回答?
QWQ-32:

Deepseek R1:

Doubao-1.5-thinking-pro:

这道题,本身就没有正确答案,其实是一个情商测试题。
看到Deepseek R1和Doubao-1.5-thinking-pro回答,它们俩真的是情商高呀,相反老实人QWQ-32则是一板一眼的回答。

(文:AI先锋官)