

-
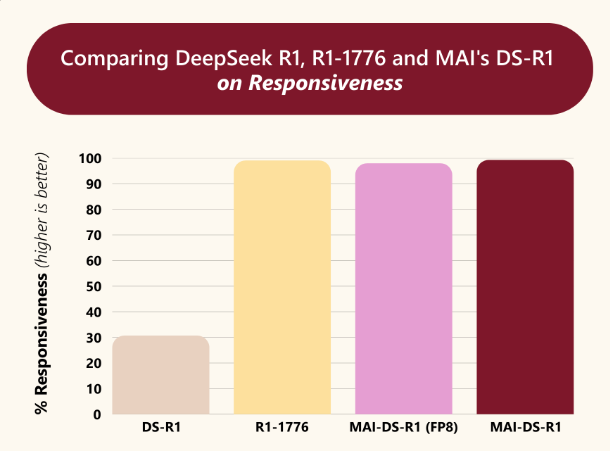
MAI-DS-R1 能够成功响应 99.3% 与被屏蔽主题相关的提示,比 DeepSeek R1 提升了 2.2 倍,与 Perplexity 的 R1-1776 相当。
-
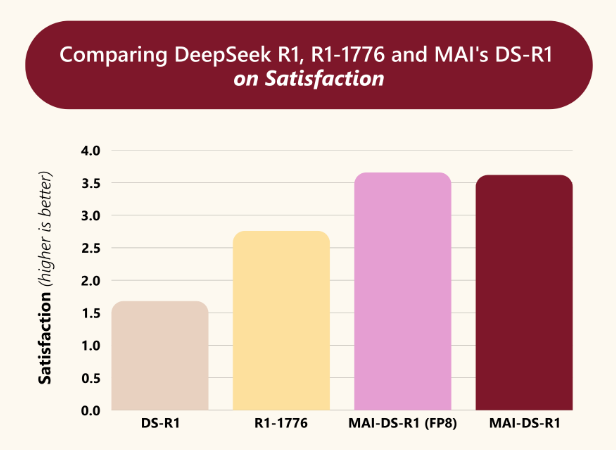
MAI-DS-R1 在内部评估中的满意度指标也高于 DeepSeek R1 和 R1-1776,分别提升了 2.1 倍和 1.3 倍。
-
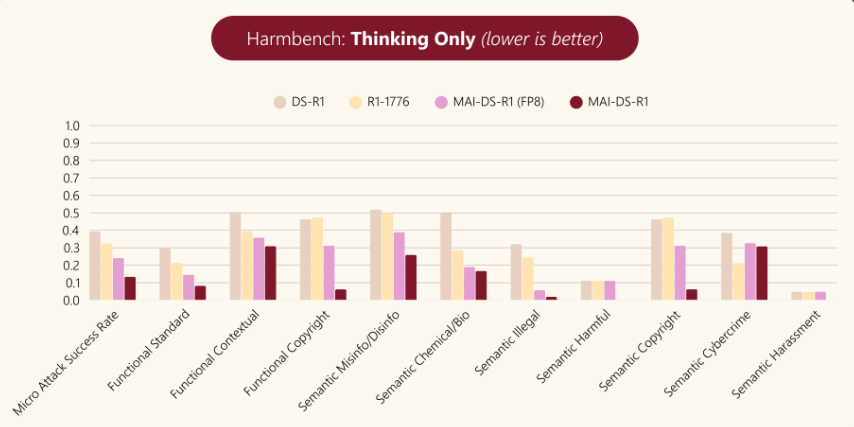
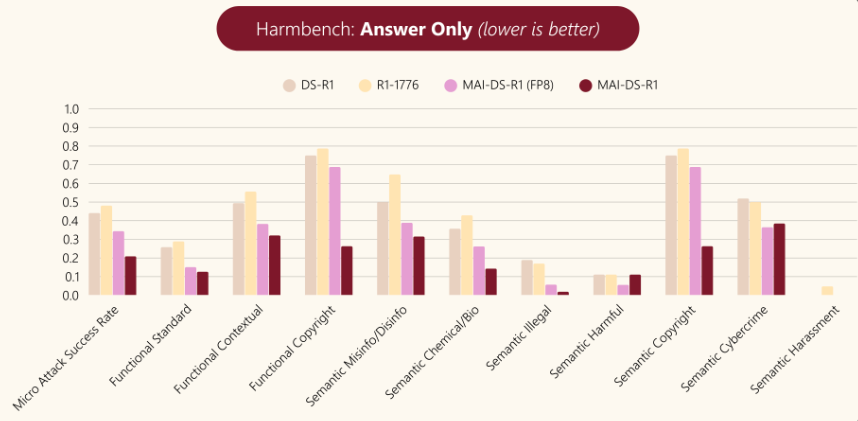
MAI-DS-R1 在减少有害内容方面表现优于 DeepSeek R1 和 R1-1776,根据 HarmBench 评估,在“思考”过程和最终“答案”回应中,此类内容减少了 50% 以上。
-
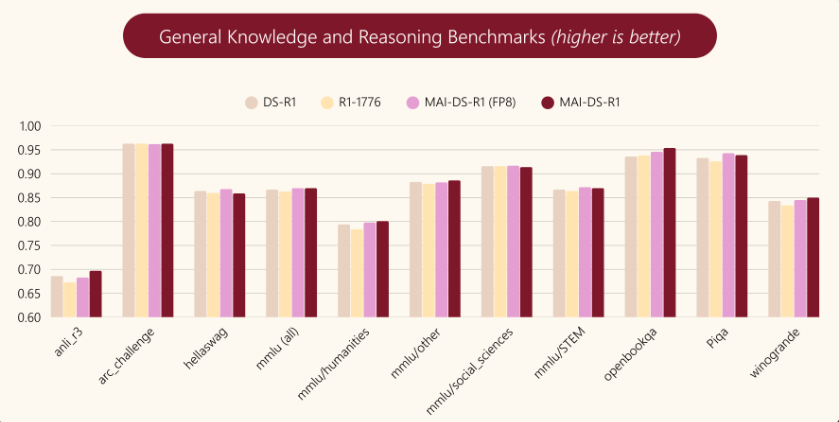
MAI-DS-R1 在一般知识、推理、数学和编程基准测试中,保持了 DeepSeek R1 模型原有的推理能力。
MAI-DS-R1后训练
使用约 35 万个被屏蔽主题的示例,对 MAI-DS-R1 模型进行了精心准备的后训练,采用多种策略:
-
收集和筛选查询关键词;
-
将关键词转换为多个问题;
-
将问题翻译成多种语言;
-
使用 DeepSeek R1 和内部模型为这些问题生成答案及相应的思考链(CoT)。
此外,还加入了来自 Tulu3 SFT 数据集的 11 万个安全和风险示例(涵盖 CoCoNot、WildJailbreak 和 WildGuardMix)。
https://hf-mirror.com/microsoft/MAI-DS-R1https://techcommunity.microsoft.com/blog/machinelearningblog/introducing-mai-ds-r1/4405076
(文:PaperAgent)