
今天是2025年4月22日,星期二,北京,晴。
关于RAG切分,已经有很多的方案了,我们也说过很多文档解析的方案,例如基于文档布局分析,将文档解析成段落、标题、图片等等block。可以以这些block作为一个单位做切分。
但随着大模型的上下文越来越大,可能不需要切的这么细,可以直接作为目录进行索引,那么问题就来了,如何进行目录生成?我们来看一个实现方案。
然后,继续回到文档解析,我们可以再看文档解析的代表模型工具池,东西越来越多,有哪些主流的,表现又如何,如何评价,都可以找到答案。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、RAG文档解析中的目录生成思路
先看一个方案,声称是用长文本做RAG的一个索引思路,PageIndex,将冗长的PDF文档转换为语义树形结构,类似于“目录”,优化后适用于大型语言模型(LLM),适合用于财务报告、监管文件、学术教科书、法律或技术手册或任何超出LLM上下文限制的文档。https://pageindex.ai/introduction,https://github.com/VectifyAI/PageIndex
在PDF上运行PageIndex,命令如下:
预处理工作流为:使用页面索引处理文档以生成树形结构->将树形结构及其对应的文档ID存储在数据库表中->将每个节点的内容单独存储在另一个表中,通过节点ID和树ID进行索引。
实现的代码在:https://github.com/VectifyAI/PageIndex/blob/main/pageindex/page_index.py,代码的核心功能是处理文档(尤其是PDF文档),提取目录(Table of Contents, TOC)信息,并将其结构化为JSON格式。同时,代码还支持对目录中缺失的页码信息进行补充和校正,并对文档结构进行递归分析和处理。
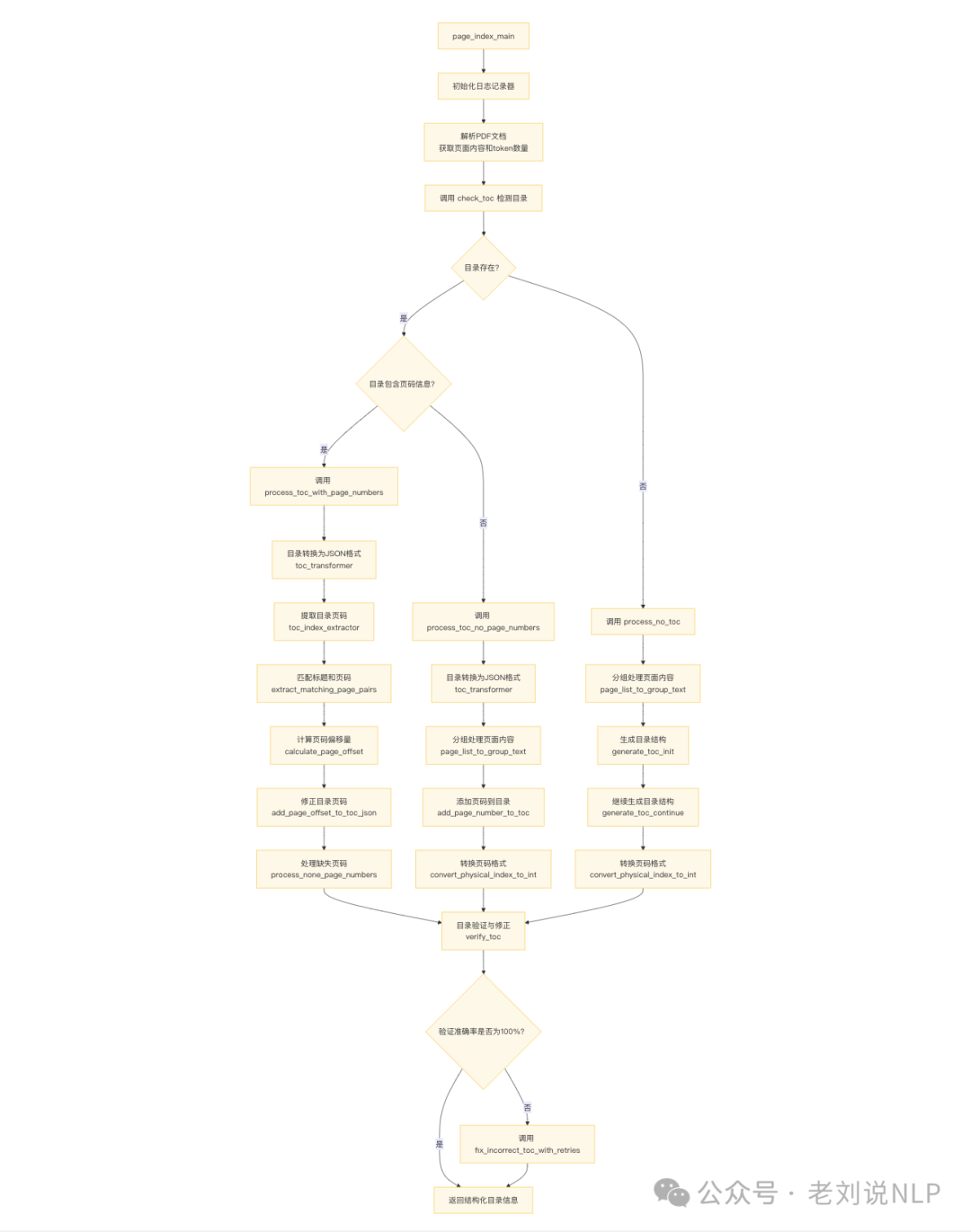
1)主入口:page_index_main是程序的主入口,负责初始化日志记录器、解析PDF文档,并调用目录检测函数check_toc。
2)目录检测:check_toc检测文档中是否存在目录,并判断目录是否包含页码信息。
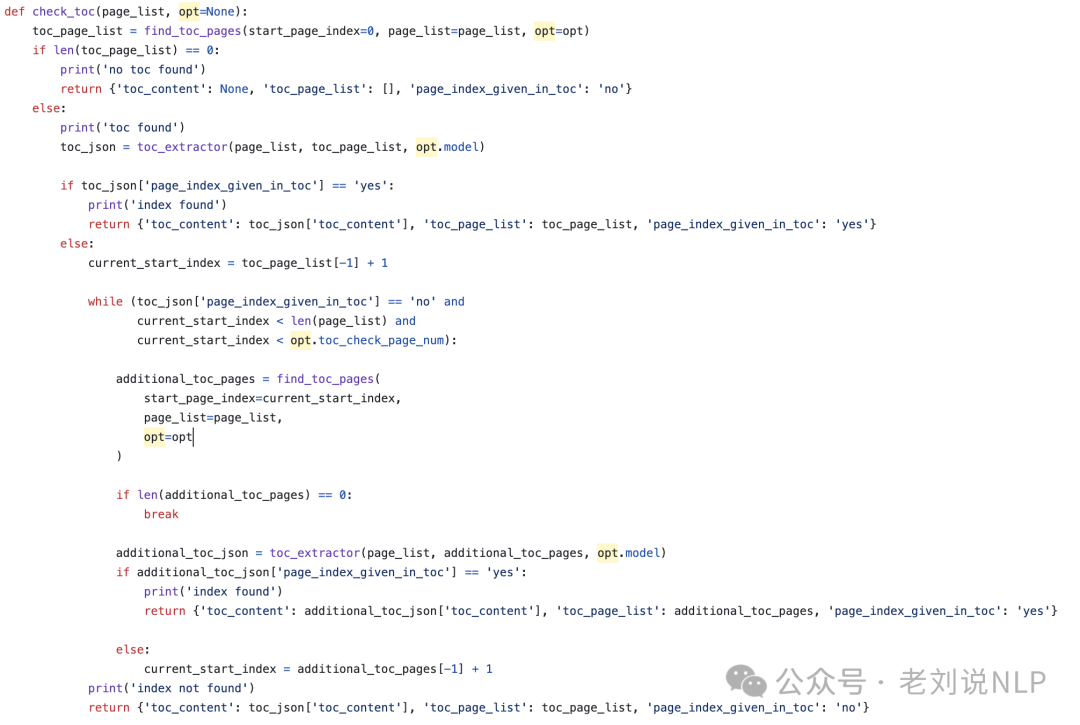
3)目录处理:如果目录存在且包含页码信息,调用process_toc_with_page_numbers进行处理。

如果目录存在但不包含页码信息,调用process_toc_no_page_numbers进行处理。
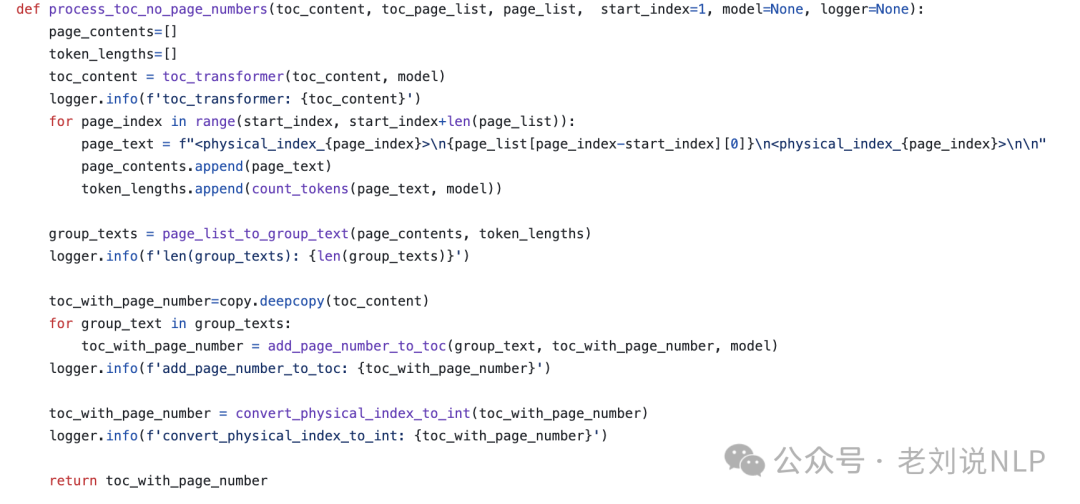
如果目录不存在,调用process_no_toc生成目录结构。
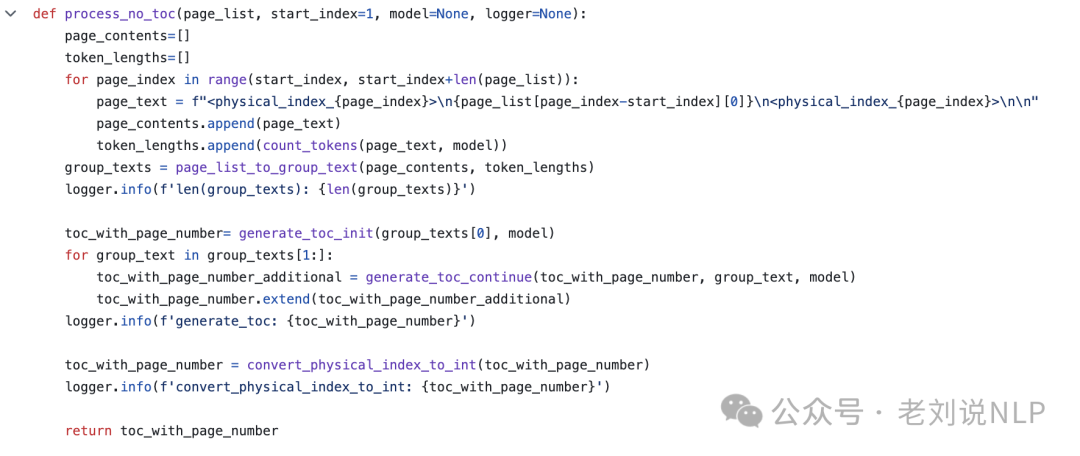
4)目录验证与修正:使用verify_toc验证目录的准确性。如果验证准确率不是100%,调用fix_incorrect_toc_with_retries进行修正。
5)递归处理大型节点:对目录树的每个节点递归调用process_large_node_recursively,处理大型节点。
6)最终输出:返回结构化的目录信息,例如几个例子:
就是把一个pdf做成目录结构的工作,有目录的,做页码映射;没目录的,找到标题,根据标题层级,组装成目录。
例如,这个文档,是个pdf的英文论文,把一级标题、二级标题都弄出来了,提取成json,具体的做法是一个prompt工程,https://kkgithub.com/VectifyAI/PageIndex/blob/main/pageindex/page_index.py,用来生成目录结构的,使用的是”gpt-4o-2024-11-20″,https://kkgithub.com/VectifyAI/PageIndex/blob/main/pageindex/config.yaml,

从(https://github.com/VectifyAI/PageIndex/blob/main/pageindex/utils.py)可以看到,使用的是PyPDF2,解析成text后,送gpt-4o后做的解析,注意,每个节点都做了一下summary摘要,用于索引,但这块比较费token。
对于存在目录的,先找到对应页码,做存储:

然后进一步在原有的目录基础上进行补充。
然后,在具体用法上,构建好之后,进行RAG的思路如下:查询预处理分析查询以识别所需的知识->文档选择搜索相关的文档及其ID,从数据库中检索对应的树形结构**->节点选择在树形结构中搜索以识别相关节点->LLM生成从数据库中检索所选节点的对应内容,格式化并提取相关信息,将组装好的上下文与原始查询一起发送给LLM,生成具有上下文信息的响应。
节点选择提示示例如下:

实际上,里面的核心的核心其实还是如何利用llm进行目录识别,例如:
prompt=“你是一个XML标题层级校正专家,根据语义,将标题层级调整为正确的层级,如果存在,谨慎修改标题的内容错误,如不确定不应该修改。根据情况,可以有多个一级标题。输入格式的<{{id}}>是用于匹配结果的,你绝对不应该修改。不允许添加、删除标题,不允许调整标题顺序。”
又如prompt=prompt = “””Your job is to detect if there is a table of content provided in the given text.Given text: {content}return the following JSON format:{{“thinking”: <why do you think there is a table of content in the given text> "toc_detected": "<yes or no>",}}Directly return the final JSON structure. Do not output anything else.Please note: abstract,summary, notation list, figure list, table list, etc. are not table of contents.“””
但是,这种方式有很强的假设性。1)假设pypdf解析的东西不乱,不遗漏;2)不可编辑的使用多模态做,准确率高;3)llm解析目录的效果好【但其实并不一定,需要加入视觉特征】;
二、文档解析的代表模型全家桶
关于文档解析,我们可以找到不少的文档解析的方案,可以这个可以作为一个工具模型池,如下:
1、文档解析方案方案
1)MinerU:https://mineru.org.cn/;
2)ppstructure:https://github.com/PaddlePaddle/PaddleOCR/blob/main/docs/ppstructure/overview.md
上面两个是pipeline式的,下面是端到端的文档领域微调大模型:
1)Marker:https://github.com/VikParuchuri/marker;
2)Unstructured:https://github.com/Unstructured-IO/unstructured;
3)OpenParse:https://github.com/Filimoa/open-parse;
4)Docling:https://ds4sd.github.io/docling/;
5)Mistral-OCR:https://mistral.ai/news/mistral-ocr?utm_source=ai-bot.cn;
6)GOT-OCR:https://github.com/Ucas-HaoranWei/GOT-OCR2.0;
7)Nougat:https://github.com/facebookresearch/nougat;
8)olmOCR:https://github.com/allenai/olmocr;
9)SmolDocling:https://huggingface.co/ds4sd/SmolDocling-256M-preview;
下面是通用多模态大模型:
1)GPT4o:https://openai.com/index/hello-gpt-4o/;
2)Gemini2.0-flash:https://deepmind.google/technologies/gemini/flash/;
3)Gemini2.5-pro-exp-0325:https://deepmind.google/technologies/gemini/pro/;
4)Qwen2-VL-72B:https://qwenlm.github.io/zh/blog/qwen2-vl/;
5)Qwen2.5-VL-72B:https://github.com/QwenLM/Qwen2.5;
6)InternVL2-Llama3-76B:https://github.com/OpenGVLab/InternVL
2、Text Recognition文本识别
1)PaddleOCR:https://www.paddlepaddle.org.cn/hub/scene/ocr;
2)Tesseract:https://tesseract-ocr.github.io/tessdoc/;
3)OpenOCR:https://github.com/Topdu/OpenOCR;
4)EasyOCR:https://www.easyproject.cn/easyocr;
5)Surya:https://github.com/VikParuchuri/surya
3、Layout版式布局分析
1)DiT-L:https://github.com/facebookresearch/DiT,https://huggingface.co/docs/transformers/model_doc/dit;
2)LayoutMv3:https://github.com/microsoft/unilm/tree/master/layoutlmv3,https://huggingface.co/docs/transformers/model_doc/layoutlmv3;
3)DOCX-Chain:https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/Applications/DocXChain,https://github.com/AlibabaResearch/AdvancedLiterateMachinery/releases/download/v1.2.0-docX-release/DocXLayout_231012.pth;
4)DocLayout-YOLO:https://github.com/opendatalab/DocLayout-YOLO,https://huggingface.co/spaces/opendatalab/DocLayout-YOLO;
5)SwinDocSegmenter:https://github.com/ayanban011/SwinDocSegmenter,https://drive.google.com/file/d/1DCxG2MCza_z-yB3bLcaVvVR4Jik00Ecq/view?usp=share_link;
6)GraphKD:https://github.com/ayanban011/GraphKD,https://drive.google.com/file/d/1oOzy7D6J0yb0Z_ALwpPZMbIZf_AmekvE/view?usp=sharing;
4、Formula公式解析模型
1)Mathpix:https://mathpix.com/;
2)Pix2Tex:https://github.com/lukas-blecher/LaTeX-OCR;
3)UniMERNet-B: https://github.com/opendatalab/UniMERNet,https://huggingface.co/datasets/wanderkid/UniMER_Dataset
5、Table表格解析模型
1)PaddleOCR:https://github.com/PaddlePaddle/PaddleOCR,https://paddlepaddle.github.io/PaddleOCR/latest/model/index.html
2)RapidTable:https://github.com/RapidAI/RapidTable,https://www.modelscope.cn/models/RapidAI/RapidTable/files
3)StructEqTable:https://github.com/Alpha-Innovator/StructEqTable-Deploy/blob/main/README.md,https://huggingface.co/U4R/StructTable-base
对于具体效果,可以看https://github.com/opendatalab/OmniDocBench,https://arxiv.org/pdf/2412.07626,作为一个选型参考。
参考文献
1、https://github.com/VectifyAI/PageIndex
2、https://github.com/opendatalab/OmniDocBench
(文:老刘说NLP)