
今天是2025年4月25日,星期五,北京,晴。
我们继续看两个问题。
一个是文档智能方向,多模态模型将文档图片转markdown及转docx逻辑,看看prompt是如何写的,比较实用,包括Text、Mathematical Formula、Table、Figure、Output Format的限定instruction。
另一个是金融领域推理模型的进展,回顾下fin-r1,并且看下新的工作DianJin-R1,重点看数据和模型两个方面。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、多模态模型将文档转markdown跟docx逻辑
主要看几个,一个是Qwen2VL、internvl,GOT-OCR以及docling,具体如下:
1、Qwen2VL、internvl转md的prompt
地址:https://github.com/opendatalab/OmniDocBench/blob/main/tools/model_infer/Qwen2VL_img2md.py中可以找到对应的prompt:
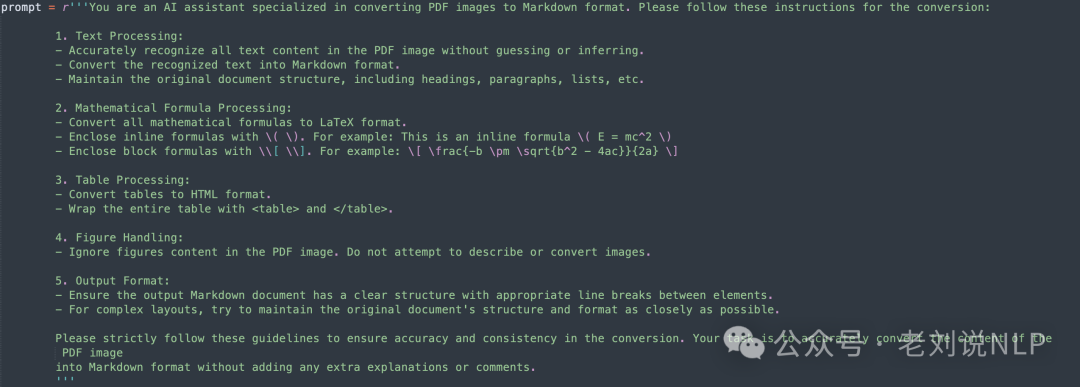
相统一的,在https://github.com/opendatalab/OmniDocBench/blob/main/tools/model_infer/internvl2_test_img2md.py中也可以看到具体写法。

2、GOT-OCR转md的使用方式
可以在地址:https://github.com/opendatalab/OmniDocBench/blob/main/tools/model_infer/GOT_img2md.py中找到对应转换脚本: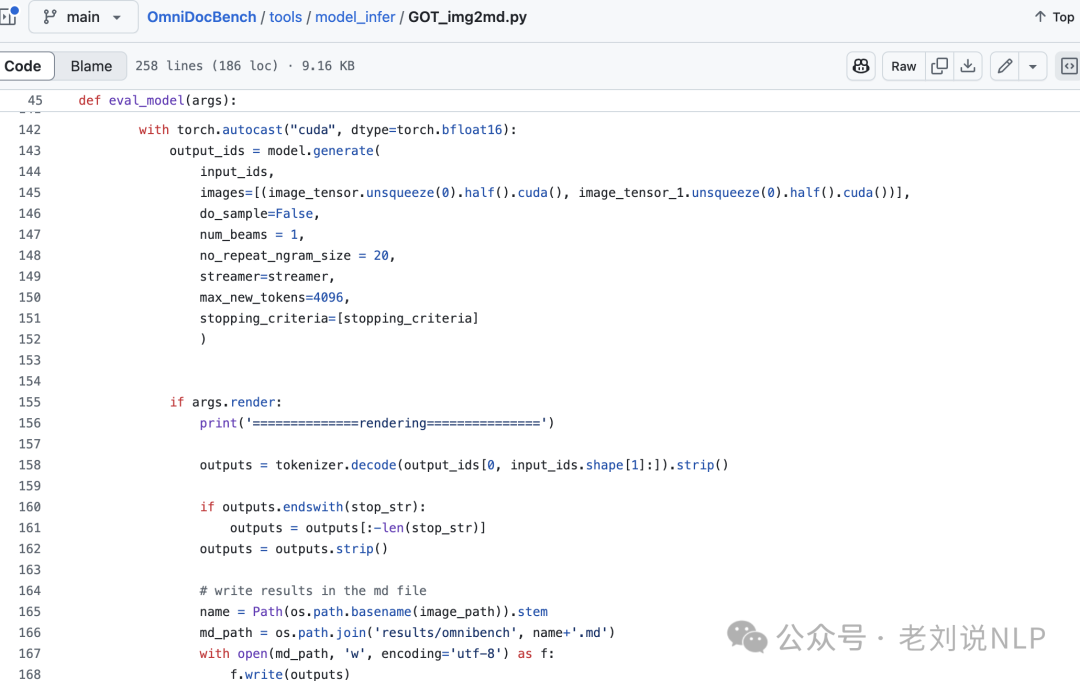
调用的prompt在: https://github.com/Ucas-HaoranWei/GOT-OCR2.0/blob/main/GOT-OCR-2.0-master/GOT/utils/conversation.py


3、docling转md的使用方式
可以在地址:https://github.com/opendatalab/OmniDocBench/blob/main/tools/model_infer/docling_img2md.py中找到对应的转换脚本:

对于docling部分的,在:https://github.com/docling-project/docling/tree/main/docling
此外,在转换完markdown之后,如果想转成docx,除了直接使用python-docx按照markdown与阿法进行写入之后,还可以看:https://github.com/vace/markdown-docx这个项目。

demo地址在:https://md-docx.vace.me,实现与纳利是以来浏览器和Node.js环境。
二、再看R1类思路用于金融领域DianJin-R1
在3月份,我们看过R1用于金融领域的工作 《Fin-R1: A Large Language Model for Financial Reasoning through Reinforcement Learning》,地址在https://arxiv.org/pdf/2503.16252,https://github.com/SUFE-AIFLM-Lab/Fin-R1。

实现思路很简单,在数据生成阶段,基于DeepSeek-R1进行数据蒸馏,并使用“llm-as-judge”方法进行数据过滤,创建高质量金融推理数据集Fin-R1-Data。
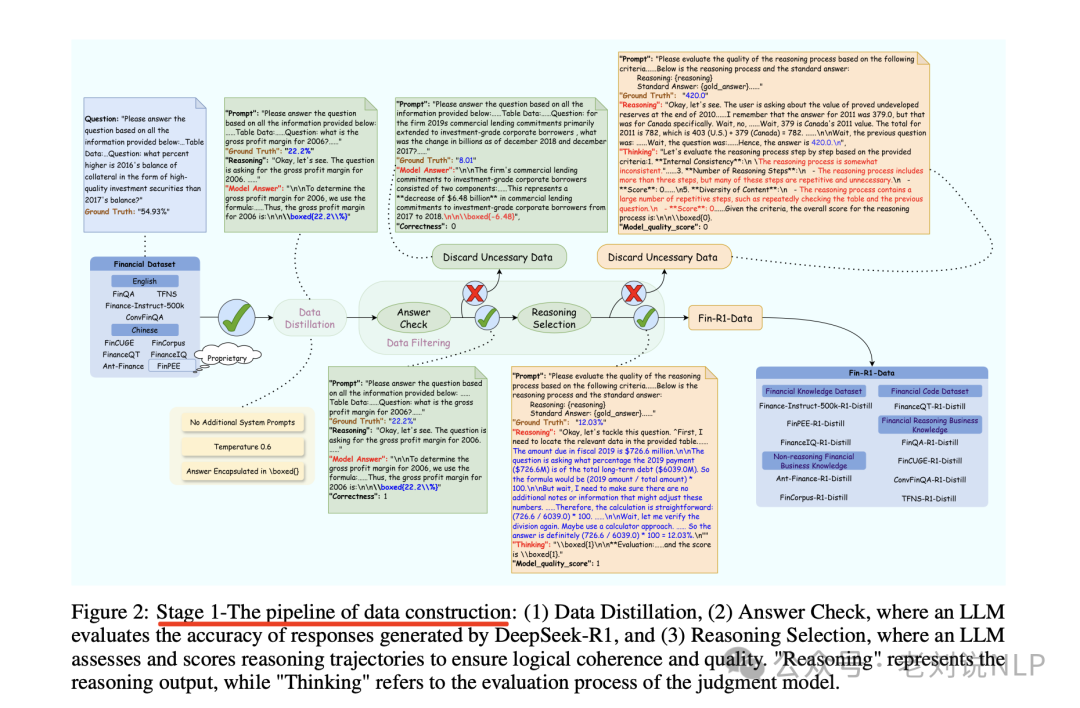
在模型训练阶段,基于Qwen2.5-7B-Instruct建立金融推理模型Fin-R1,通过有监督微调(SFT)和分组相对策略优化算法(GRPO)增强模型推理能力并规范输出格式。

一个月之后,看一个类似的工作《DianJin-R1: Evaluating and Enhancing Financial Reasoning in Large Language Models》(https://arxiv.org/pdf/2504.15716),模型及数据相关地址在:https://huggingface.co/DianJin,https://modelscope.cn/organization/tongyi dianjin,https://github.com/aliyun/qwen-dianjin,https://tongyi.aliyun.com/dianjin,https://github.com/aliyun/qwen-dianjin/blob/master/DianJin-R1/README_zh.md,这个工作认为,金融任务通常需要领域特定的知识、精确的数值计算和严格的合规规则,所以提出一个增强的推理框架DianJin-R1,通过推理增强的监督学习和强化学习来解决。
那么,具体如何解决的?核心看数据和模型两个点。
在数据集构建上,构建了一个高质量的数据集DianJin-R1-Data,结合了CFLUE、FinQA和一个专有的合规语料库(Chinese Compliance Check, CCC)。CFLUE包含超过31,000个金融资格模拟考试中的推理注释的多选和开放式问题,FinQA提供数值推理问题,CCC专注于需要多步逻辑的复杂合规场景。
具体的:
CFLUE包含超过31,000个推理注释的多项选择题和开放式问题。为了构建高质量的子集,研究团队应用了三个过滤步骤:长度过滤、难度过滤和歧义过滤。长度过滤去除了少于15个token的问题,难度过滤去除了所有小型语言模型都能正确回答的问题,歧义过滤则使用GPT-4o消除了包含歧义的问题,最终得到了高质量的推理增强数据集。具体的,首先使用gpt-4o把多项选择题转换为开放式问题,接着利用deepseek-r1获取推理数据。
FinQA包含8,281个金融问答对,需要数值推理。同样应用了长度和难度过滤,以确保数据质量和复杂性。
CCC包含真实世界的中国金融客户服务对话,标注了服务代理是否违反合规。为了生成推理路径,研究团队开发了一个基于工作流程的推理生成方法,分配一个LLM代理到每个条件节点,生成中间推理路径和答案,最终合并所有中间推理路径生成最终的统一推理路径。也就是,获取Multi-Agent System工作流中所有的推理步骤并使用gpt-4o合并为一个最终的推理过程和推理结果。

在模型训练上,使用Qwen2.5-7B-Instruct和Qwen2.5-32B-Instruct进行微调,生成推理步骤和最终答案。采用结构化输出格式,使用和标签。模型训练分为两个阶段:监督微调和强化学习。

在监督微调阶段,使用DeepSpeed的Zero-3进行优化,序列长度为16K,进行3个epoch的训练。在强化学习上,应用Group Relative Policy Optimization(GRPO),引入两种奖励信号:一种鼓励结构化输出(确保生成的输出遵循特定的结构,即输出必须在和标签之间,且没有其他额外内容,如果输出不符合这一严格格式,奖励分数为0;否则为1),另一种奖励答案的正确性。这些机制引导模型产生连贯、可验证的推理路径和可靠的答案(如果标签内的内容与参考答案完全匹配,奖励分数为1;否则为0)。进行5个epoch的训练。
参考文献
1、https://arxiv.org/pdf/2503.16252
2、https://arxiv.org/pdf/2504.15716
(文:老刘说NLP)