
今天是2025年5月26日,星期一,北京,晴
我们今天继续看强化的一些问题,目前更多的是在工程框架层上做一些工作。
具体分成两个:
一个是从Agent智能体强化学习框架RL-Factory看工程设计,尤其是其中的multi-turn tool use。
另一个是从统一强化学习框架One-RL-to-See-Them-All看数据工程及奖励策略,尤其是引入课程式学习方式,进行目标检测任务的动态IOU奖励和困难样本选择策略。
这些都是从技术角度能够有所启发的点,多总结,多深入,终会有所收获。
一、从Agent智能体强化学习框架RL-Factory看工程设计
Agent训练框架进展,RL-Factory(RLFactory: Plug-and-Play RL Post-Training Framework for Empowering LLM Tool-Use,https://github.com/Simple-Efficient/RL-Factory),图标长的很像llamafactory微调训练框架。
主要的infra是基于verl的,之所以将其与verl库分离而新建一个项目,出发点是希望专注于LLM tool use(尤其是multi-turn tool use),其包含两个核心的特征,工具调用能力训练以及多样的reward计算方式。
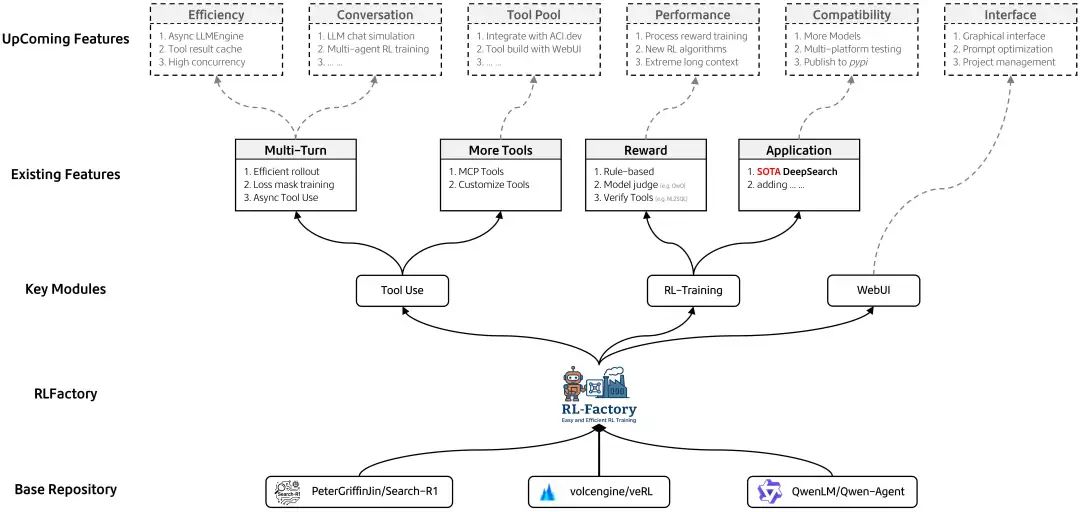
这类框架的工作,能够给我们启发的,其实是看他如何设计的,设计过程可以看:https://github.com/Simple-Efficient/RL-Factory/tree/main/docs/rl_factory/zh,里面也涉及到一些基本的概念解释,对工程化理解有帮助。
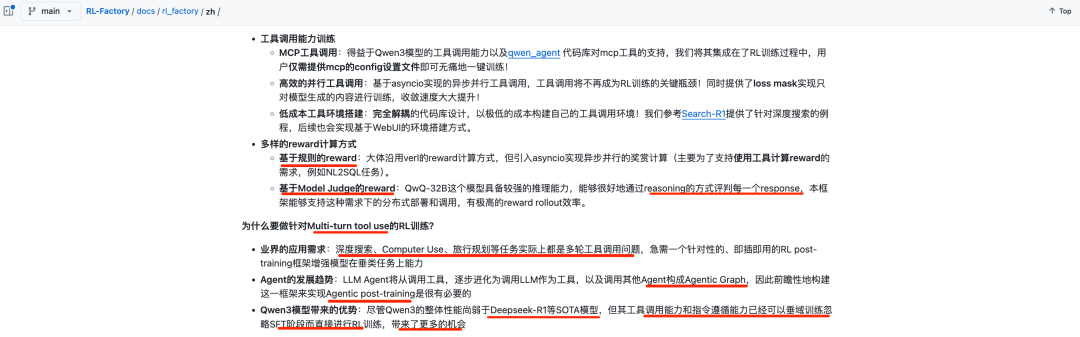
例如,为什么要做针对Multi-turn tool use的RL训练?的论述
又如,相关的概念辨析。
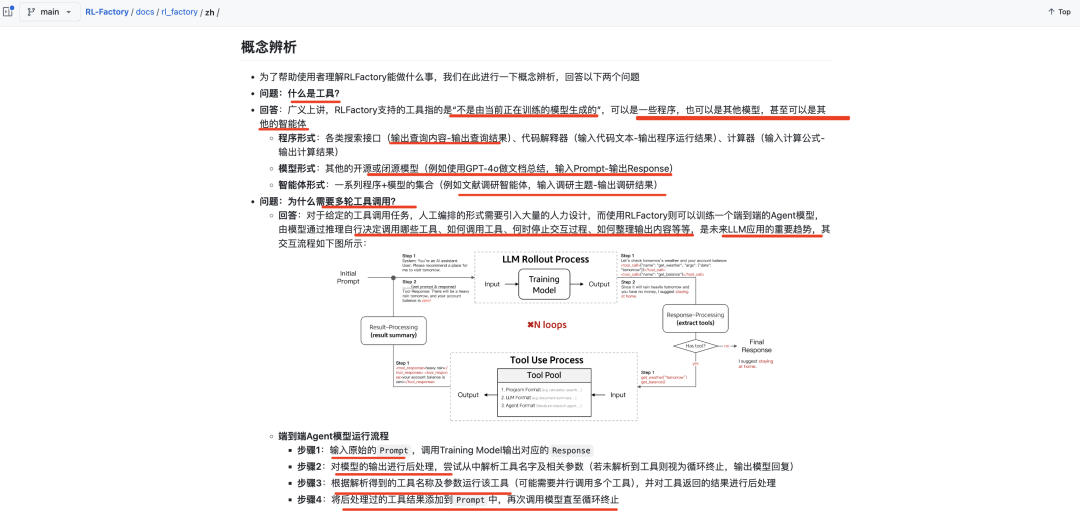
其中重点传递出来的,是对多轮工具训练的前沿方向,目前的框架越来越多,从脚本走向平台,是个大趋势。
二、从统一强化学习框架One-RL-to-See-Them-All看数据工程及奖励策略
强化学习进展,先看统一强化学习框架,One-RL-to-See-Them-All,目的是让视觉语言模型在单一训练框架中建模视觉推理和感知任务,支持8种任务(4推理+4感知),https://github.com/MiniMax-AI/One-RL-to-See-Them-All,https://github.com/MiniMax-AI/One-RL-to-See-Them-All/blob/main/MiniMax-One-RL-to-See-Them-All-v250523.pdf,我们分别从数据工程、模型选择、训练策略和可以借鉴的点几个角度来看这个工作
1、数据工程方面的工作
其中的数据构造策略,构造难样本以及正确样本的思路值得借鉴。

选择了四个推理任务(数学、拼图、科学和图表)和四个感知任务(检测、定位、计数和OCR)。数据来源包括mm_math、Geometry3k、mmk12、PuzzleVQA、AlgoPuzzleVQA、VisualPuzzles、ScienceQA、SciVQA、ChartQAPro、ChartX、Table-VQA、V3Det、Object365、D3、CLEVR、LLaVA-OV Data和EST-VQA。
数据过滤上应用了两阶段数据过滤过程:规则过滤和难度过滤。规则过滤去除不符合要求的样本,难度过滤去除过于简单或困难的样本。
视觉推理和视觉感知数据通过一个基于规则的过滤器,该过滤器会移除不符合预设标准的样本。随后,数据进入一个难度过滤器,该过滤器基于模型表现移除过于简单或过于困难的样本。具体的:
对于推理任务,使用Qwen2.5-VL-32B-0321来计算pass@8,只保留0≤pass@8<100% 的样本;
对于感知任务,特别是检测和定位任务,使用Qwen2.5-VL-7B和0.5的IoU阈值来计算pass@16,并选择累积IoU奖励在2到10之间的样本。
最终生成了47.7K高质量的样本。
2、模型选择上的工作
采用Qwen2.5-VL-7B-Instruct和Qwen2.5-VL-32B-Instruct作为基础模型。
3、训练策略上的工作
一个是使用动态GRPO算法,为视觉感知任务(如检测和定位)提供自适应、渐进和明确的反馈,即采用动态IoU奖励策略,在训练过程中逐步调整IoU阈值,以提供自适应、渐进和明确的反馈。
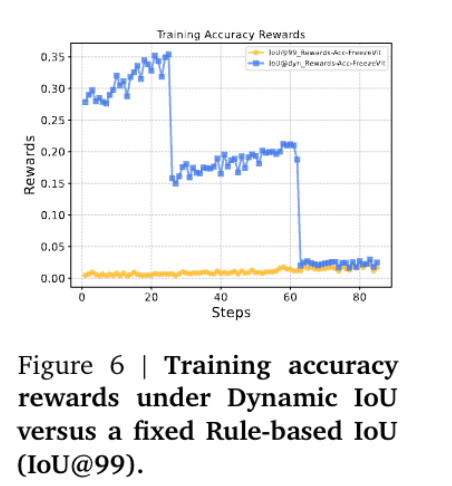
这个的底层逻辑在于,使用严格的IoU阈值(0.99)会增强感知和推理信号之间的一致性,但这个其严格的程度在早期展开中引入了冷启动问题,此时大多数预测获得0奖励,因此采用动态IOU策略,IoU阈值ϵ根据训练进度分阶段调整:在前10%的训练步骤开始时为0.85,在随后的15%步骤中增加到0.95(即从总步骤的10%到25%),最后在训练的其余时间内稳定在0.99。
一个是使用两种类型的验证器:MathVerifyVer-ifier和DetectionVerifier
3、可以借鉴的点
首先,课程学习的思路现在用的很多,无论是数据角度,还是阈值角度,还是超参角度,都可以按照这个思路去展开。
其次,如何设计不同的量化指标来量化模型行为?这个工作提出了几个,包括整体平均值、正确/错误响应的长度、截断率以及反射比率。其中,截断率(输出达到最大长度)可能表明过度冗长或生成崩溃。对于反射比率,跟踪15个预定义的与反射相关的单词(例如“重新检查”、“重新思考”、“验证”),然后计算包含这些反思词汇的回应比例;反思回应中的正确率:包含这些词汇的回应准确性。这有助于通过将反思与正确性联系起来,诊断模型倾向,如过度思考与表面回应。
最后,在结论侧。对于视觉推理任务,观察到随着任务难度的增加,性能有明显的提升趋势。随着训练的进行,神经序列长度和反射率的变化,类似于大型语言模型在测试时观察到的缩放律。然而,这些趋势在视觉感知任务中并不明显。推动感知性能提升的潜在因素仍然不清楚;在VLMs中进行强化学习主要作为一种对齐策略,它优化了模型的决策和响应行为,而不是促进新知识的获取。这支持了强化学习微调能够增强预训练VLMs的效用和鲁棒性,而不会改变它们的基础能力这一观点。
参考文献
1、https://arxiv.org/pdf/2505.13379
2、https://github.com/Simple-Efficient/RL-Factory
(文:老刘说NLP)