
-
提供0.6B/4B/8B三种版本 -
支持119种语言 -
在MMTEB、MTEB和MTEB-Code上达到了最先进的性能
-
文档检索、检索增强生成(RAG)、分类、情感分析、代码搜索等!

-
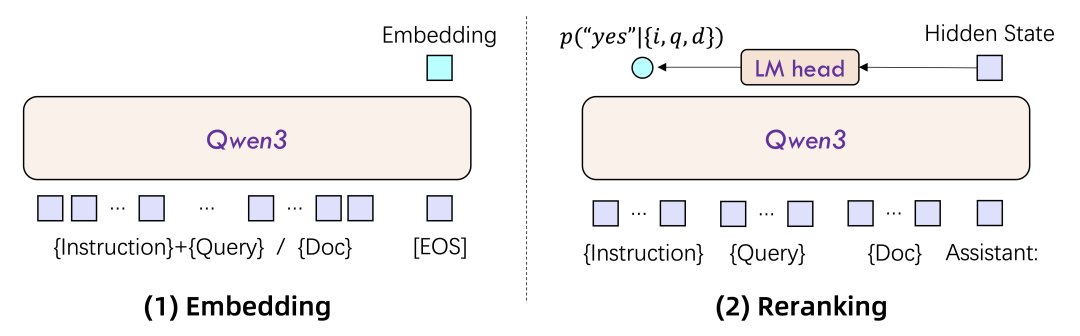
嵌入模型以单个文本片段作为输入,利用最终的[EOS]标记对应的隐藏状态向量来提取语义表示。 -
重排序模型以文本对(如用户查询和候选文档)作为输入,通过单塔结构计算并输出文本对之间的相关性分数。
-
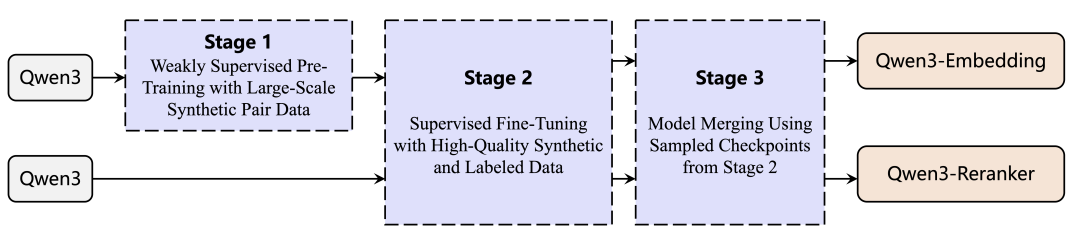
第一阶段涉及使用大量弱监督数据进行对比预训练; -
第二阶段专注于使用高质量标注数据进行监督训练; -
第三阶段通过合并策略整合多个候选模型,以提升整体性能。

Hugging Face:Qwen3-Embedding: https://huggingface.co/collections/Qwen/qwen3-embedding-6841b2055b99c44d9a4c371f…Qwen3-Reranker: https://huggingface.co/collections/Qwen/qwen3-reranker-6841b22d0192d7ade9cdefea…ModelScope:Qwen3-Embedding: https://modelscope.cn/collections/Qwen3-Embedding-3edc3762d50f48…Qwen3-Reranker: https://modelscope.cn/collections/Qwen3-Reranker-6316e71b146c4f…GitHub : https://github.com/QwenLM/Qwen3-EmbeddingBlog : https://qwenlm.github.io/blog/qwen3-embedding/Paper: https://arxiv.org/pdf/2506.05176
(文:PaperAgent)