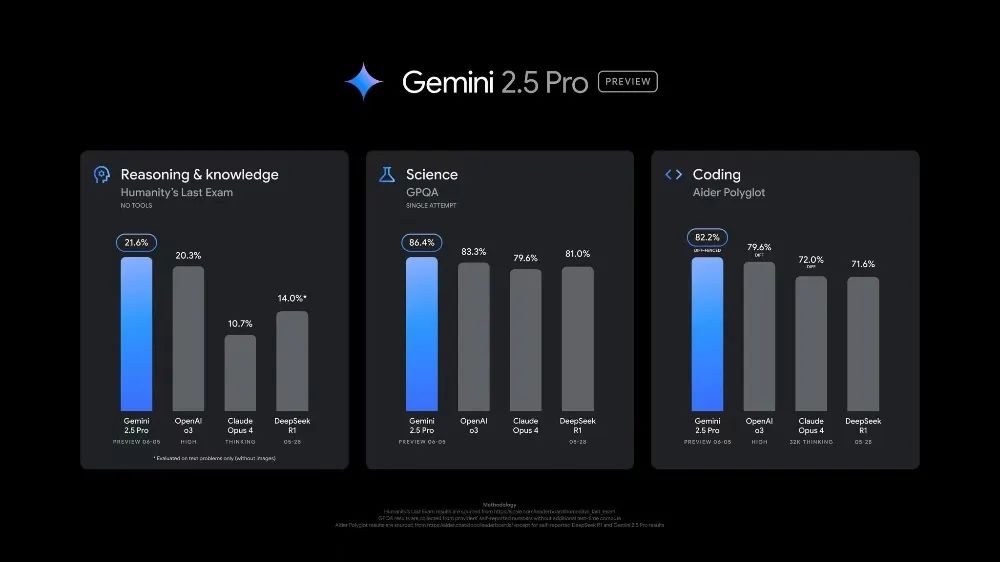
智东西6月6日消息,谷歌今日突袭推出Gemini 2.5 pro的重磅更新版本Gemini 2.5 Pro Preview 06-05 Thinking,该版本在推理能力、科学以及编程能力测试中超越OpenAI o3、DeepSeek R1和Claude Opus 4,其中编程能力更是领跑Aider Polyglot等高难度编程基准测试。
价格方面,06-05版本沿用了先前版本的价格策略,即每百万token输入(无缓存)1.25美元(约合人民币9元),输出10美元(约合人民币72元)。
谷歌CEO桑达尔·皮查伊(Sundar Pichai)在海外社交媒体X上亲自官宣:“我们最新的Gemini 2.5 Pro更新现已发布预览版……我们听取了您的反馈,并对回答的风格和结构进行了改进。您可以在Al Studio、Vertex Al平台和Gemini app中进行试用。正式版即将推出!”
在5月年度I/O开发者大会上,谷歌宣布已对Gemini 2.5 Pro进行静默升级。谷歌DeepMind首席执行官戴米斯·哈萨比斯(Demis Hassabis)当时评价I/O版本是公司迄今最佳编程模型。
而此次名为“Gemini 2.5 Pro Preview 06-05 Thinking”的新预览版在05-06版本之上进行的更新,测试表现更优,谷歌在博客中评价该版本为“我们迄今为止最有智慧的模型”。谷歌还透露说,新版本“具备企业级应用成熟度”,将于两周后作为稳定版面世。
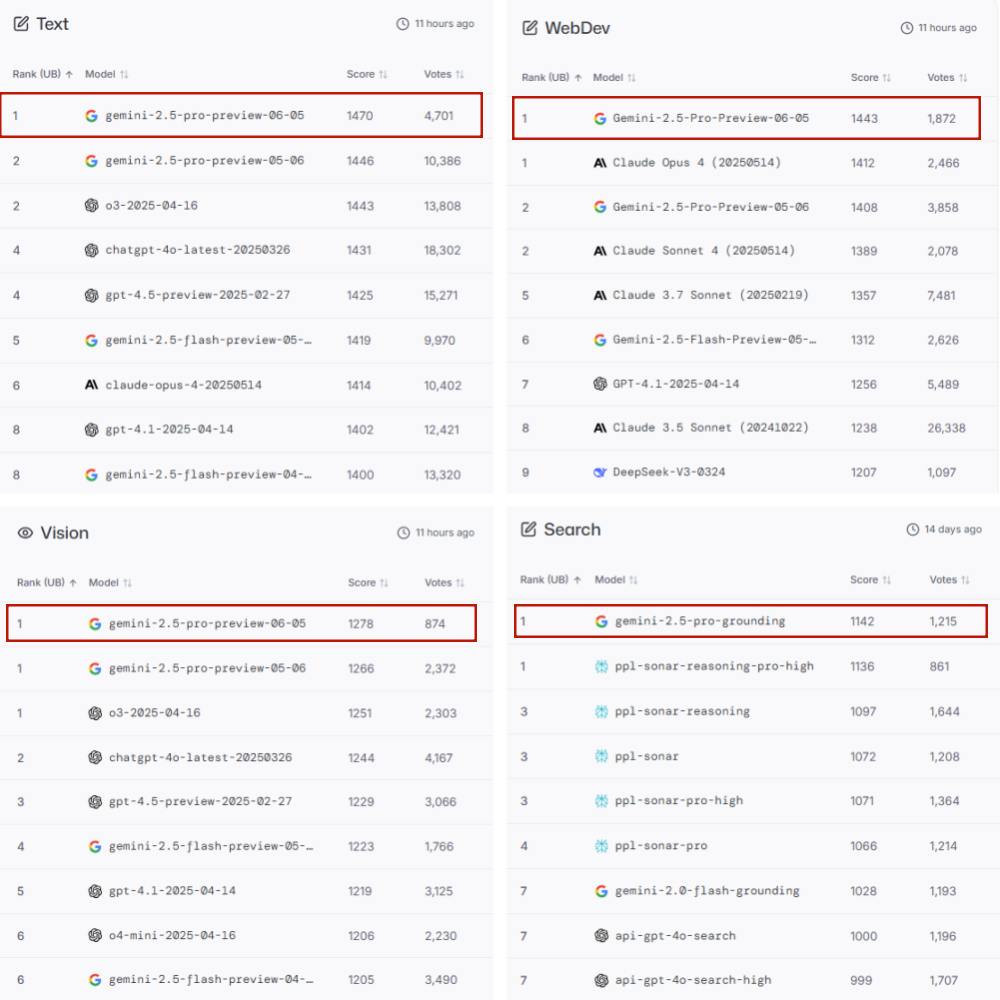
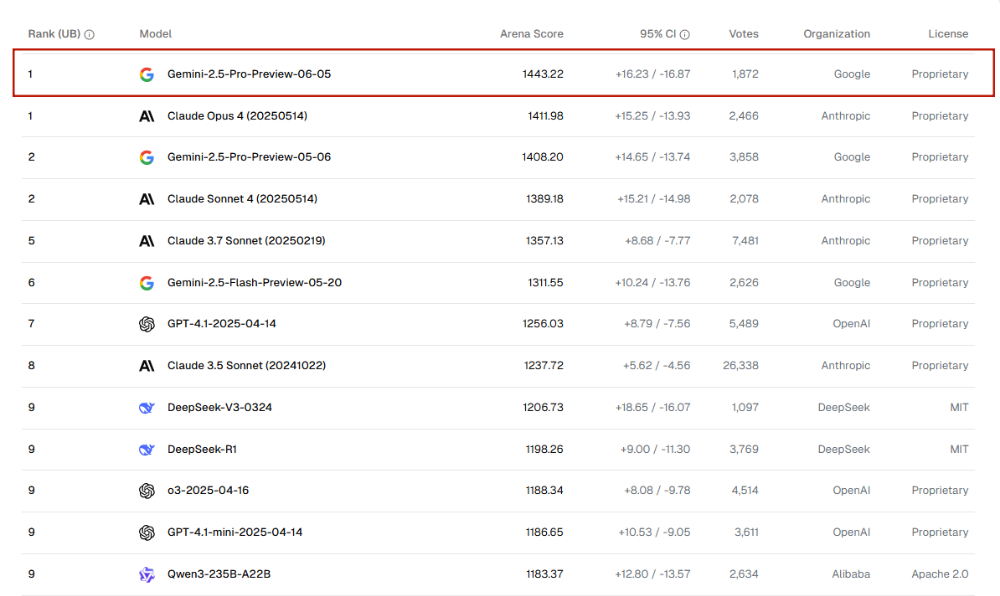
Gemini 2.5 Pro Preview 06-05 Thinking在基准测试中全面屠榜,文本、视觉、网页开发、编程、数学、创意、多轮对话、指令跟随及长查询类别等能力上均拔得头筹。
▲综合榜单(来源:LMArena)
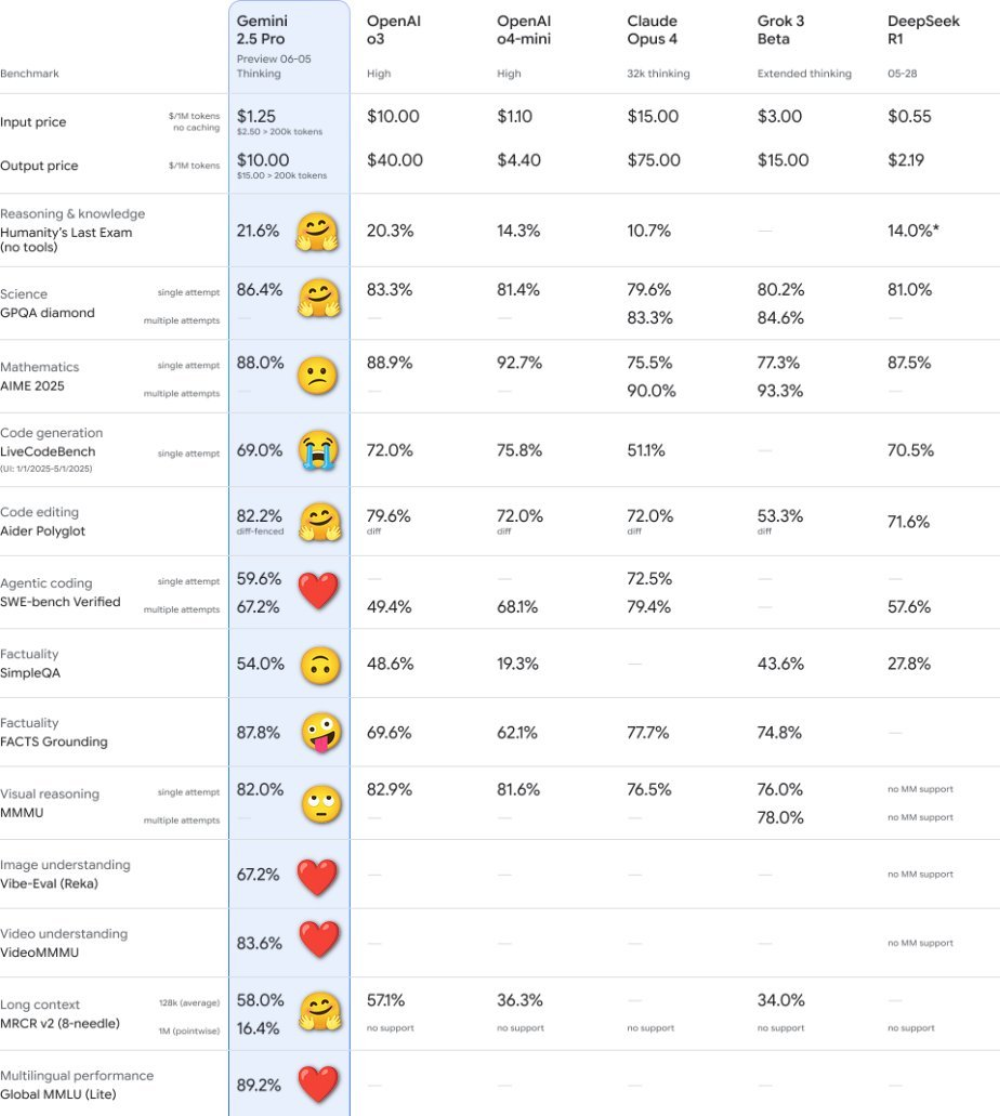
有网友在用Emoji表情标出了06-05版本的表现对比,可以看出其在测试数学能力的AIME 2025、测试代码生成的LiveCodeBench上并未超过o3和o4-mini,视觉推理的MMMU榜单上也未超过o3,仍有进步空间。
且在价格上,06-05版本与榜单中的其他模型相比较为实惠,但仍远高于DeepSeek R1。
从细分榜单来看,LMArena文本基准测试中,06-05版本的Elo分数较05-06版提升24分,以1470分保持榜首。WebDevArena测试中,其Elo分数以1443分领先,较此前提升了35分。06-05版本也领跑Aider Polyglot等高难度编程基准测试,超越DeepSeek R1等一众大模型。
▲WebDevArena榜单(来源:LMArena)
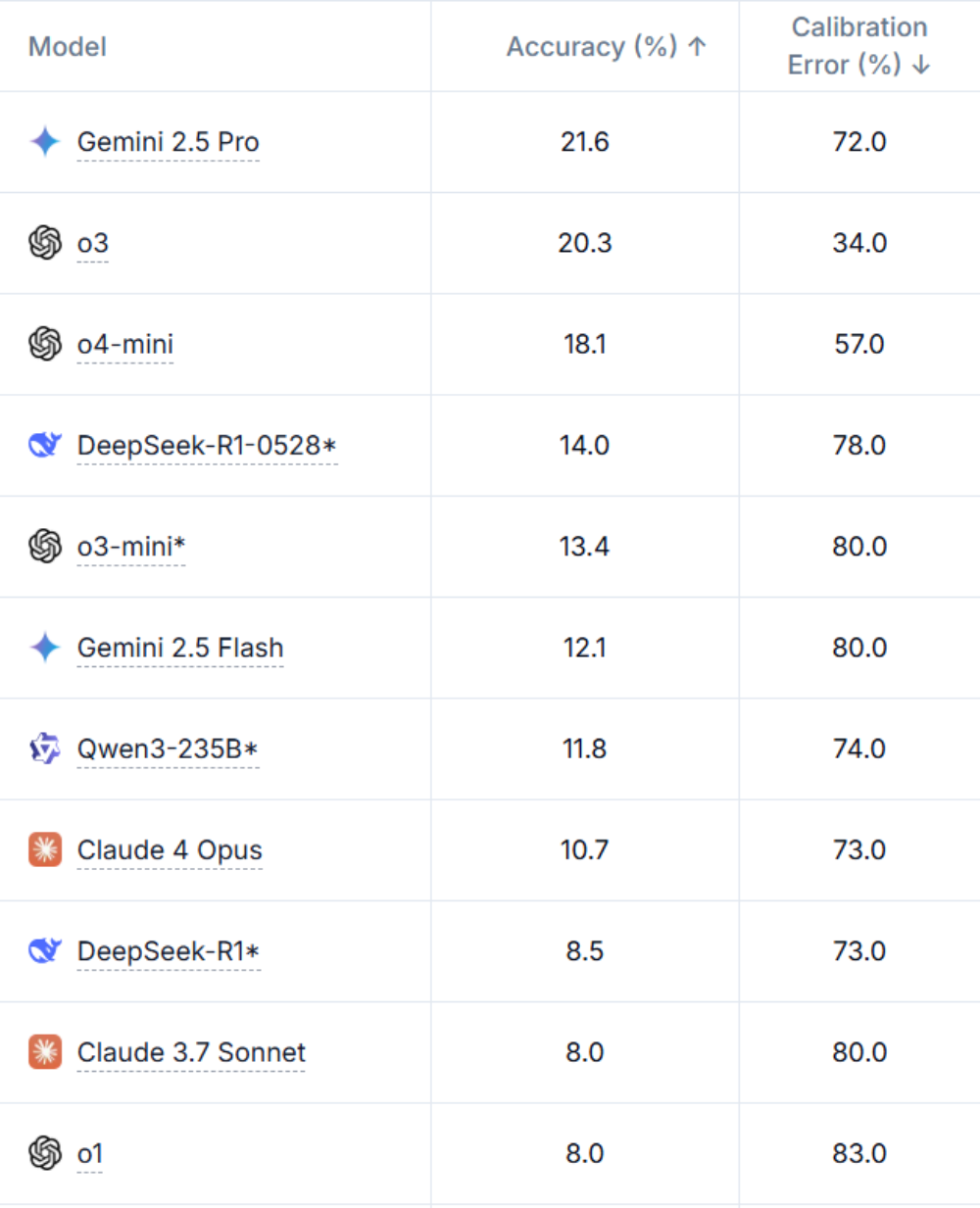
在HLE(Humanity’s Last Exam,人类终极测试)中,06-05版本的成绩为21.6%,几乎是Claude 4 Opus的2倍,GPQA测试的成绩也同样占据榜首。这两个测试是评估数学、科学、知识及推理能力的超高难度测试,06-05版本的亮眼成绩足以说明它的实力。
▲HLE榜单(来源:Humanity’s Last Exam官网)
即刻起,开发者们可以从谷歌AI Studio和Vertex AI平台接入Gemini API体验最新版本,谷歌还在这两个平台上新增了“思考预算”功能,优化成本与延迟控制。同时,新版本也将在Gemini应用上逐步推出。
06-05版本一经推出就有许多开发者和用户进行体验尝鲜。
首先是图像生成方面,皮查伊自己用Gemini生成了一张狮子的特写照片,图片十分生动:
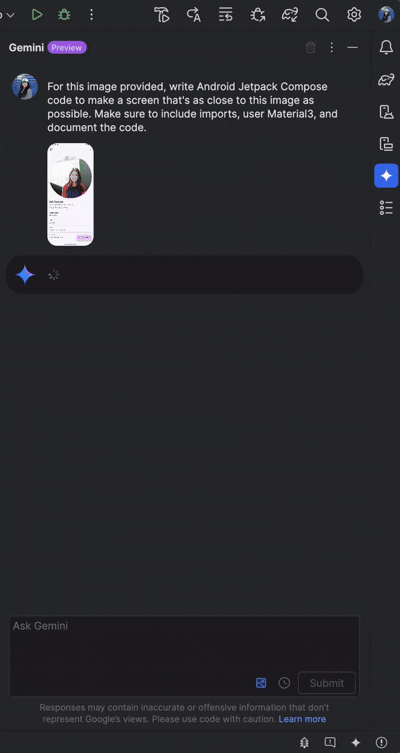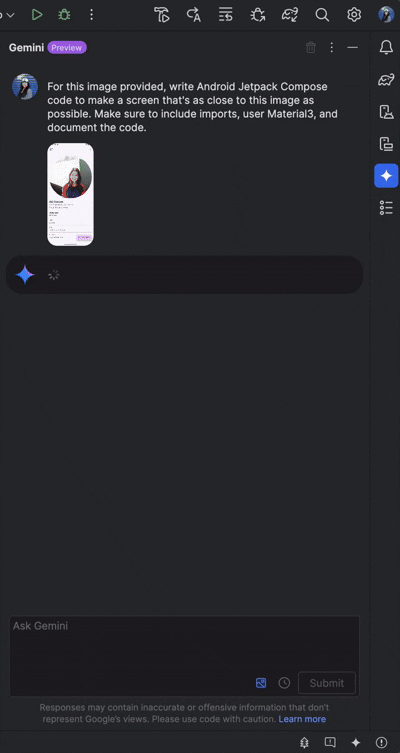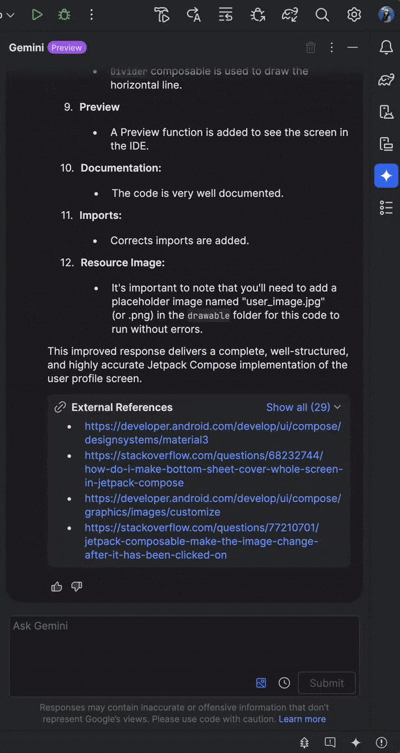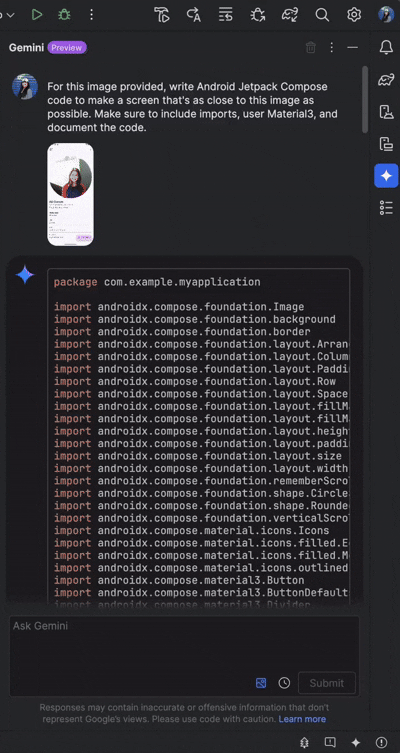
编程方面:Android studio提示Gemini 2.5 Pro Preview 06-05 Thinking创建一个用户个人资料图片,要求包含:Android Jetpack Compose 代码,能够生成类似该用户个人资料图片的代码以及导入语句、Material3和代码文档,结果十分惊艳:
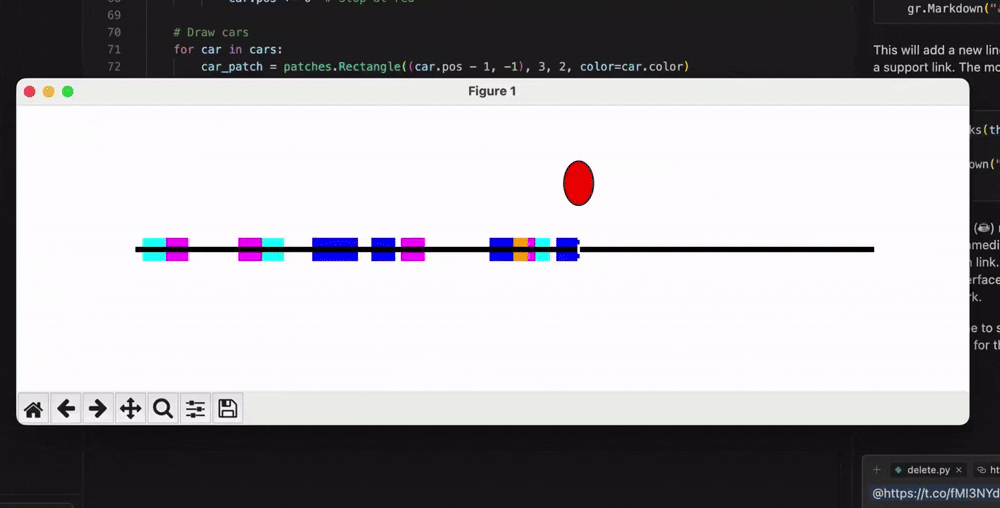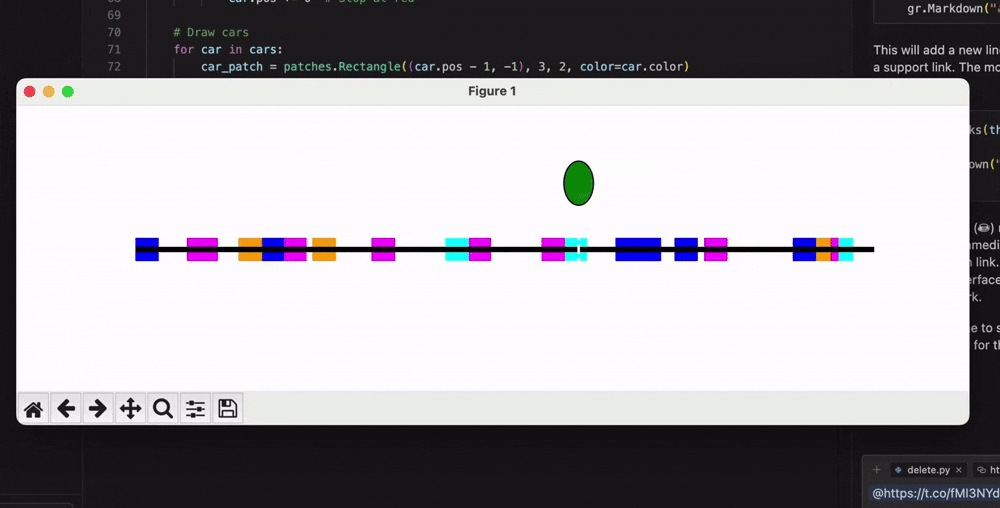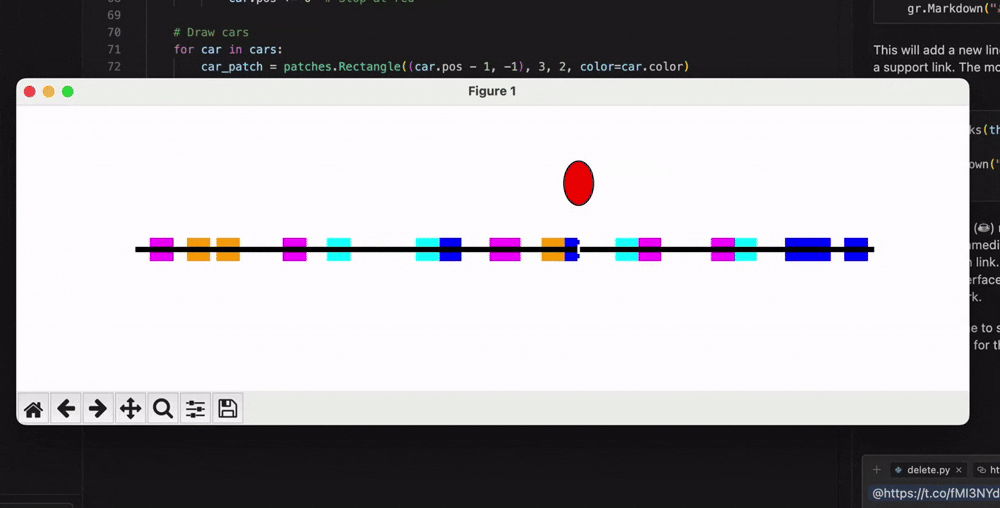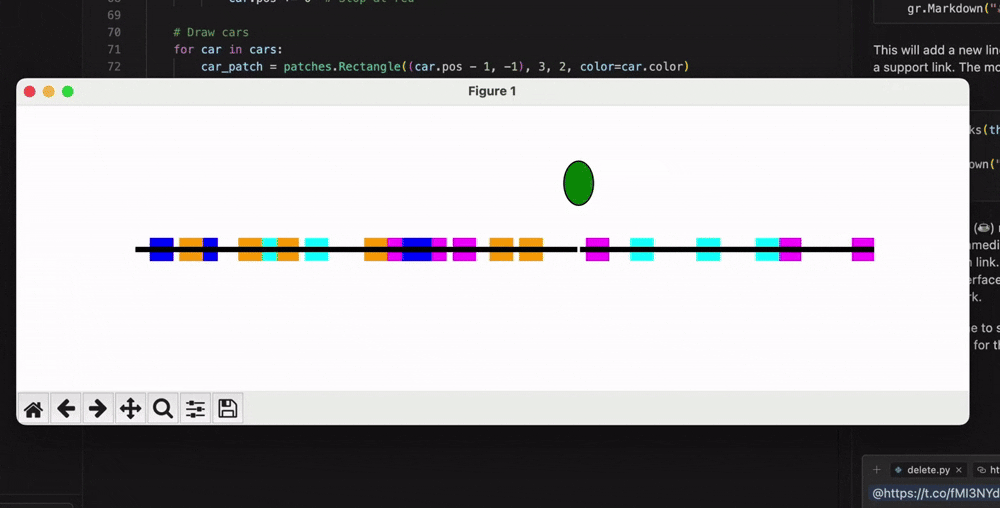
有网友要求06-05版本编写一个Python程序,模拟随机车流量单行道上的交通信号灯运作过程:
还有网友要求06-05版本编写一个“3D球体”代码来展示它的能力,结果它仅凭一句指令就生成了这个交互式粒子系统,让网友直呼“这不可能是真的!”
此前,DeepSeek和OpenAI的推理模型曾主导行业关注焦点,智东西不久之前曾报道DeepSeek-R1-0528开源,其性能接近OpenAI在4月中旬发布的o4 mini和o3模型高版本。谷歌此番更新更是迎头赶上,全面屠榜,基准测试结果超越DeepSeek R1和OpenAI的o3、o3-mini和o4-mini。
Gemini 2.5 Pro初代版本于3月发布时,Venture Beat的马特·马歇尔(Matt Marshall)就称其为“最被低估的智能模型”。这一评价很快得到验证,凭借2.5 Pro及其两个升级版本的快速迭代,谷歌不仅大幅提升了模型的多模态理解、长文本推理和代码生成能力,更在大语言模型性能基准测试中多次超越竞品。
如今大模型的迭代周期越来越短,基准测试榜单的头把交椅也时常易主。AI较量的白热化提醒我们,大模型从一开始的大爆发时代已经进入快迭代时代。
来源:谷歌Blog、X、LMArena、Humanity’s Last Exam以及Venture Beat

(文:智东西)