
苹果的AI 研究团队这次真的翻车了!

他们最近发布的一篇论文引发了AI 圈的集体吐槽,原因竟然是测试方法出了大问题。
见前文:苹果宣判推理模型死刑!Google CEO:忘了AGI吧,先用好AJI
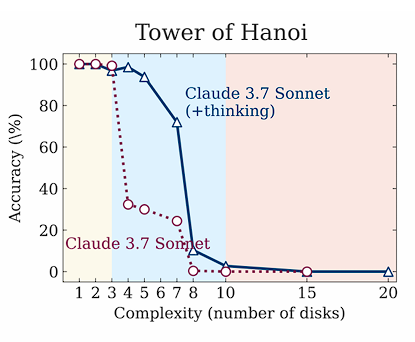
研究者Lisan al Gaib在复现苹果论文中的汉诺塔(Tower of Hanoi)测试后发现了一个惊人的事实:模型根本不是因为推理能力不行而失败,而是因为输出token限制!

要知道,汉诺塔问题需要至少2^N – 1步才能解决,而输出格式需要每步10个token外加一些固定内容。
这意味着什么?
对于Sonnet 3.7(128k输出限制)、DeepSeek R1(64K)和o3-mini(100k),当盘子数超过13个时,所有模型的准确率都会变成0——不是因为它们不会解,而是物理上就输出不了那么多内容!

更讽刺的是,当问题规模变大时,模型们的反应非常人性化。它们会直接说:「由于移动次数太多,我将解释解决方法而不是列出所有32,767步」。
这就像让一个数学家在一张A4纸上写下一百万个数字,然后说他数学不行一样荒谬!
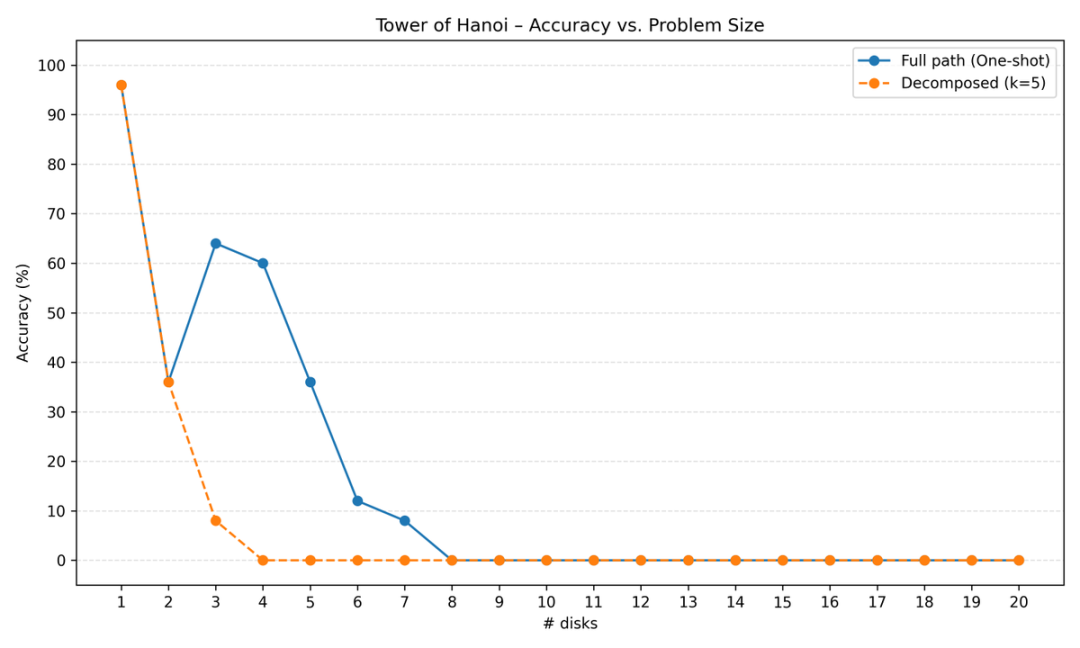
Lisan al Gaib还尝试了将问题分解成更小的块,每次只让模型执行5步。
结果呢?
使用Gemini 2.0 Flash测试后发现,分解反而让性能变得更差。
模型在处理过程中会迷失在算法里,重复执行某些步骤。
虽然汉诺塔理论上是无状态的(每一步的最优移动只依赖当前状态),但模型需要历史记录才能知道自己执行到哪里了。
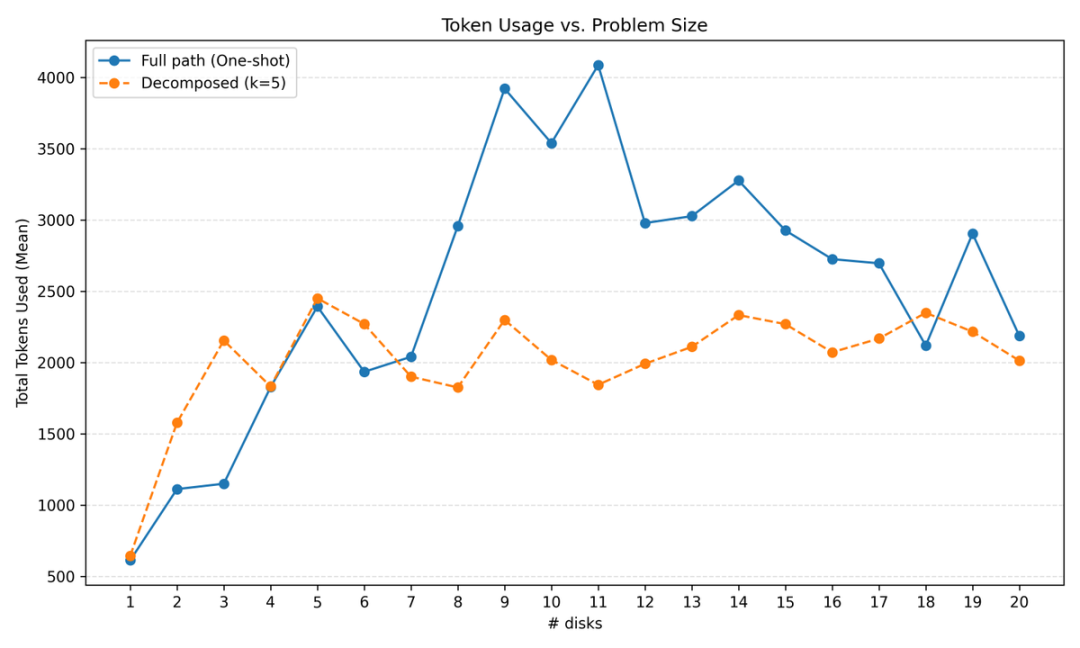
研究还发现了一个有趣的现象:在9-11个盘子时,token使用量会达到峰值。
为什么?
因为这正是模型们开始说「我才不要写下2^n_disks – 1步」的临界点。
在此之前,模型们也不是在逐步推理。
对于5-6个盘子的小问题,还能看到一些推理过程。但超过这个规模后,它们基本就是:复述问题→复述算法→打印步骤。到了10-11个盘子,就开始拒绝输出所有步骤了。
最离谱的是苹果论文的结论。

他们声称汉诺塔比其他测试更难,是因为训练数据的问题。但Lisan al Gaib指出:
这完全是胡说八道!
模型在思维链中明明白白地背诵了算法,有的甚至用代码形式展示出来。汉诺塔需要指数级的步骤(2^n),而其他游戏只需要二次方或线性的步骤,这并不意味着汉诺塔在推理上更困难。
不同游戏的单步难度是不一样的,不能简单地用步骤数来判断难度!

其他研究者也加入了吐槽大军。
Shin Megami Boson直言这篇论文「sucks ass」,他通过让模型使用工具,在苹果评为0%准确率的复杂度上达到了100%的准确率——
而且用的还是更弱的模型!
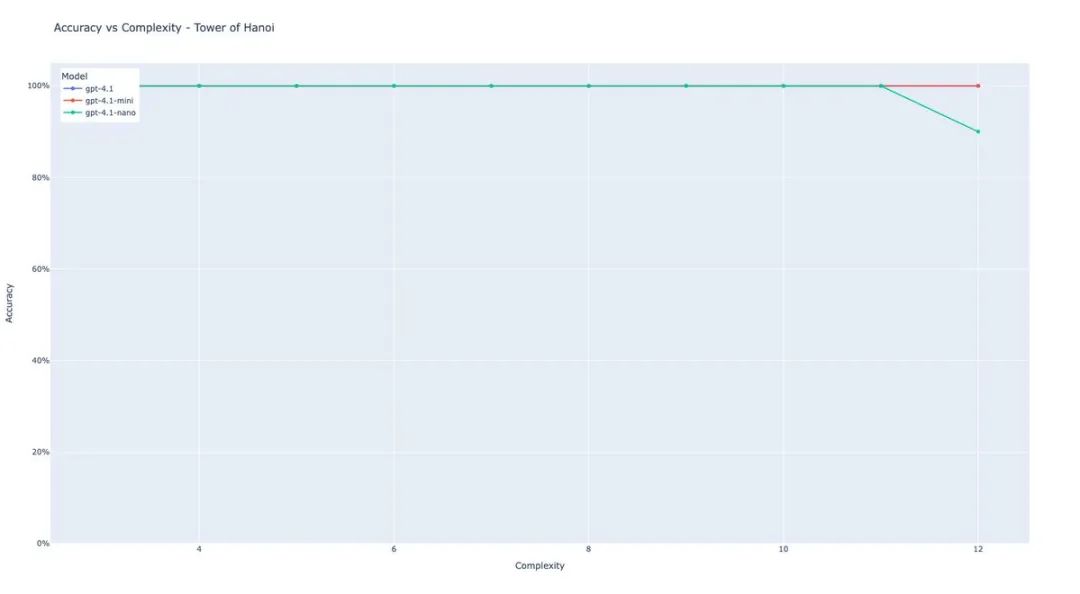
他的实验结果图「看起来像什么都没有」,因为就是一条100%准确率的直线。

他总结道:「他们试图用锤子拧螺丝,然后写了篇论文说锤子在固定东西方面其实很有限。」
而最让我气愤加失望的是,苹果似乎在努力证明AI有问题,而不是去用AI 改进用户体验。
Pliny the Liberator(@elder_plinius)的吐槽一针见血:
在Siri能做到不止是第四次尝试才成功创建日历事件之前,我不会读任何来自库比蒂诺那个巨大陈腐甜甜圈的AI研究论文。
他接着说:
如果我是苹果CEO,看到我的团队发表一篇只专注于记录当前方法局限性的论文,我会当场解雇所有参与者。谁他妈在乎这个。去想办法突破它们!
Luci Dreams(@Luci_Drea)调侃道:
「我们没有好的AI,所以看看你们AI的缺陷,别玩得太开心了」
Chris Fry(@Chrispyfryz)质疑:
说真的,他们在那边到底在干什么
R(@rvm0n_)表示:
我无法理解他们怎么搞砸得这么厉害

Freedom_Aint_Free(@baianoise)的比喻更是精准:
这就像起亚的工程师写论文说丰田车无法在没有大修的情况下跑200万英里
Ben Childs(@Ben_Childs)幽默地说:
看,苹果确实有AI,而且很棒。他们只是在另一所高中上学。你不会认识她的。
SPUDNIK(@tuber_terminal)模仿Siri的语音识别错误:
「好的,所以你想让我在勺子日的六点火腿创建一个应用软膏?我应该创建它吗?」
苹果正在被Tim Cook「Cook」了——这些研究人员花时间证明AI有问题,而不是去改进用户体验。
你说,Cook 是不是该裁了这帮人?
(文:AGI Hunt)