
-

-
• 应用价值: 多智能体是AI能力的新拐点,通过“AI团队协作”解决单个大模型无法应对的复杂研究任务,内部评估性能提升90.2%。核心价值在于实现动态、深度的信息综合,而非简单的静态RAG。 -
• 架构核心: 系统采用 “指挥官-士兵”(Orchestrator-Worker) 模式。一个主智能体(Lead Agent)负责策略与任务分解,多个子智能体(Subagents)并行执行,通过持久化记忆(Memory)和专用引用代理(CitationAgent) 确保长任务的连贯性与结果的可靠性。 -
• 成本与ROI: 性能提升的代价是高昂的Token消耗(约为普通聊天的15倍)。Token使用量是性能最关键的驱动因素(解释80%的方差)。这意味着需要为高价值任务进行明确的成本效益权衡。 -
• 工程挑战 : 生产级多智能体系统的三大核心挑战是:状态管理(错误会级联放大)、非确定性调试(传统Debug失效)和无缝部署(需采用彩虹部署等策略)。 -
智能倍增效应:AI协作的新范式
正如人类社会通过集体智慧实现了文明的指数级飞跃,人工智能也正迎来一个相似的转折点。我们正在从单纯提升单个AI模型的“智商”,迈向构建能够系统化协作、放大集体能力的“AI团队”。这,就是多智能体系统(Multi-agent Systems)带来的智能倍增效应。
对于开放式、复杂的探索性任务(如深度市场研究、技术路径分析),传统AI方法——即便是最强大的单个大模型——也常常力不从心。这些任务的本质是动态和不可预测的,需要同时探索多条线索,并综合来源各异的信息。
Anthropic的实践证明,通过构建一个多智能体研究系统,能够有效地应对这一挑战,将AI的能力边界从“个体天才”扩展到“高效团队”。
架构设计:从静态RAG到动态“指挥官-士兵”模型
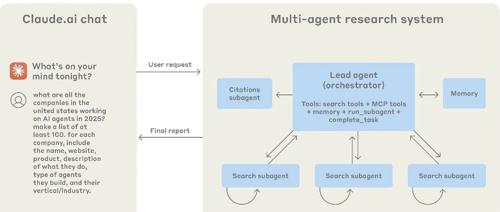
为了让AI团队有效运作,一个清晰的组织架构至关重要。Anthropic的系统借鉴了人类研究团队的协作模式,构建了一个 “指挥官-士兵”(Orchestrator-Worker) 架构。

架构解读:这张图展示了系统的核心协同模式。一个主智能体(Lead Agent)扮演研究总监的角色,负责战略规划和任务分解。它将大问题拆解成多个子任务,并委派给并行的子智能体(Subagents)。这种分工协作模式,与传统的检索增强生成(RAG)有本质区别——它不是一次性的静态信息检索,而是动态、多步、自适应的问题解决过程。
完整工作流拆解
系统的运作流程精密而高效,每一步都为最终的高质量输出服务:
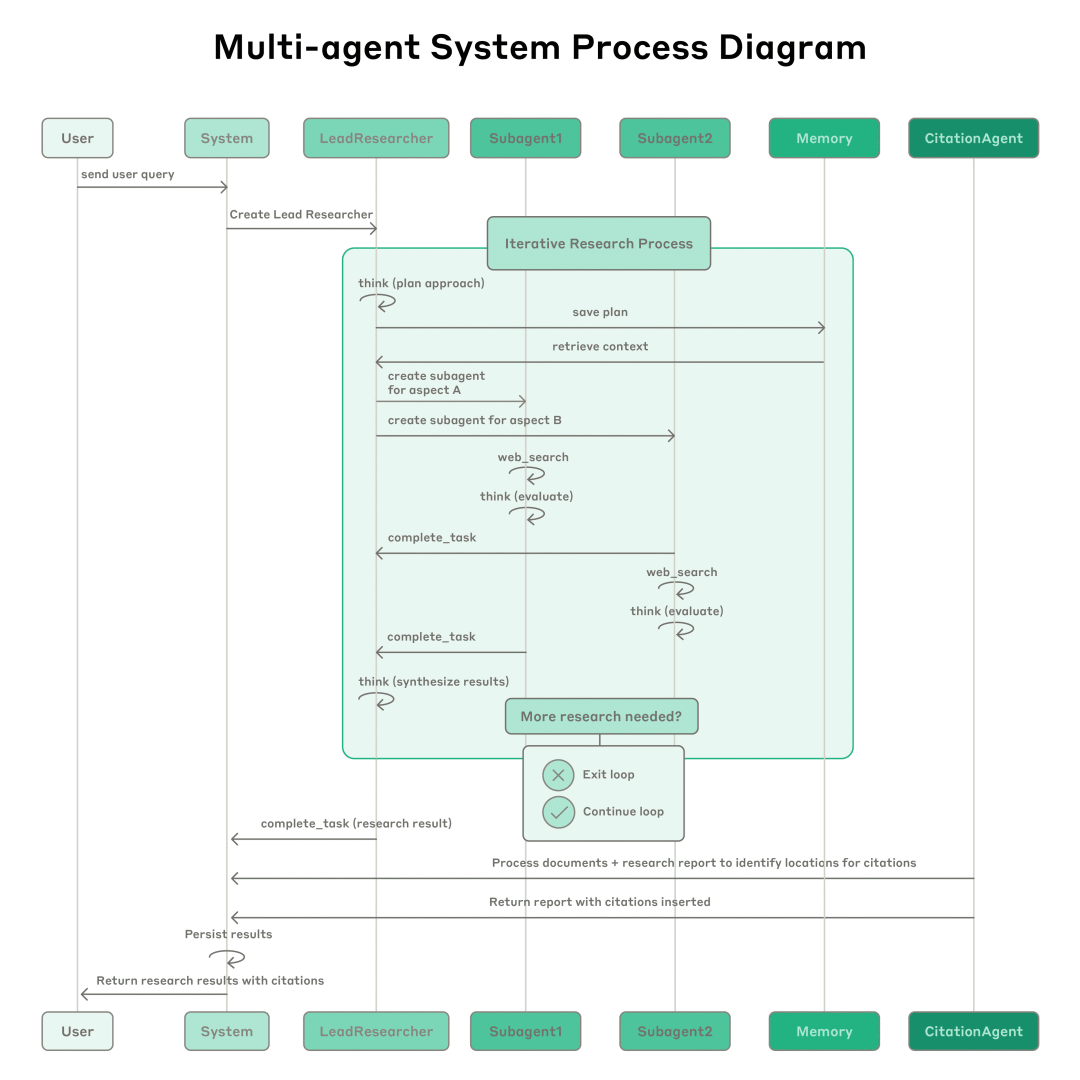
工作流剖析:这张图是给工程师的系统蓝图。关键组件和流程包括:
-
1. 查询分析与规划:LeadResearcher(主智能体)接收用户请求,制定详细研究计划。 -
2. 持久化记忆 (Memory Persistence):为解决超长上下文(>200k tokens)问题,研究计划被存入外部Memory,确保任务在长时间运行中不“失忆”。 -
3. 创建子智能体 (Subagent Spawning):根据计划,创建具备特定研究任务授权的Subagents。 -
4. 并行执行与交错思考:各Subagents独立、并行地使用工具进行研究,并通过**交错思考(Interleaved Thinking)**技术在每一步后进行自我评估和调整。 -
5. 结果综合与迭代:LeadResearcher汇总各方发现,判断是否需要发起新一轮研究。 -
6. 引用处理 (Citation Processing):研究完成后,一个专用的CitationAgent会介入,核实所有结论,并为其匹配精确的信源引用,确保交付结果的严谨性。
性能突破与成本权衡
多智能体系统带来的性能提升是惊人的。Anthropic内部评估显示,由Claude Opus 4担任主智能体、Claude Sonnet 4担任子智能体的组合,在研究任务评估中,性能比最强的单个Claude Opus 4模型高出90.2%。
Token经济学:性能背后的成本
这种性能飞跃的背后,是显著增加的Token消耗。理解其“经济模型”对于产品决策至关重要:
-
• 普通聊天交互:基准Token用量 (1x) -
• 单智能体交互:约 4倍 于普通聊天 -
• 多智能体系统:约 15倍 于普通聊天
Token消耗的急剧增加,是因为多智能体架构通过将推理任务分散到多个拥有独立上下文窗口的智能体中,从根本上解决了单个模型上下文长度的限制。它用“更多的并行思考”换取了单个智能体无法企及的深度和广度。
更深层次的分析揭示,在复杂的浏览任务中,95%的性能差异可由三个因素解释:
-
1. Token使用量(解释了80%的方差) -
2. 工具调用次数 -
3. 模型的选择
这对产品和工程团队的启示是:对于高价值、复杂的任务,设计一个能有效扩展Token使用的架构,是提升性能上限的关键,其重要性甚至高于单纯追求单个模型的极致效率。
构建可靠多智能体系统的三大支柱
从一个能跑的Demo到一个可靠的生产系统,需要跨越巨大的鸿沟。Anthropic的经验总结为三大支柱:
支柱一:提示工程 (Prompt Engineering) – 从指令到协作框架
在多智能体系统中,Prompt不仅是指令,更是定义智能体间协作规则、资源预算和行为模式的框架。糟糕的Prompt会导致协作灾难(如启动过多子智能体、任务重叠)。
-
• 教会授权 (Teach Delegation):主智能体的Prompt必须包含清晰的任务分解框架,指导其如何为子智能体创建包含目标、输出格式、工具和边界的精确指令。 -
• 动态扩展 (Scale Effort Appropriately):在Prompt中嵌入资源分配规则。例如:简单事实核查(1个智能体,3-10次工具调用);复杂对比研究(10+个子智能体,分工明确)。 -
• 像智能体一样思考 (Think Like Your Agents):通过模拟环境,逐步观察智能体的行为,是理解和调试Prompt最有效的方式。
支柱二:工具设计 (Tool Design) – 智能体的“瑞士军刀”
工具的可用性直接决定了智能体的效率。
-
• 清晰的工具描述:每个工具的文档(description)都必须清晰、明确,避免歧义。 -
• 内置使用启发式规则:在Prompt中指导智能体如何选择和使用工具,例如“先浏览所有可用工具”、“优先使用专用工具”、“先广泛搜索再聚焦”。 -
• 让智能体自我优化工具:一个创新的实践是创建一个“工具测试智能体”。它反复试用一个工具,根据失败案例自动重写和优化工具描述。这一过程使后续智能体使用该工具的任务完成时间缩短了40%。
支柱三:并行化 (Parallelization) – 速度与性能的倍增器
并行是多智能体系统效率的灵魂。
-
• 并行创建子智能体:主智能体一次性启动3-5个子智能体,而非串行等待。 -
• 并行调用工具:每个子智能体可同时调用3个以上工具。 -
• 最终结果:对于复杂查询,研究时间最多可缩短90%。
从原型到生产:直面工程的“最后一公里”
将多智能体系统产品化,工程师会面临一系列传统软件开发中不常见的挑战。Anthropic将这段“最后一公里”的经验总结为以下三点:
-
1. 状态管理复杂性 (State Management Complexity):智能体是长周期、状态化的。一个微小的错误(如工具API超时)就可能导致行为链的连锁反应,使整个任务偏离轨道。 -
• 解决方案:必须构建持久化执行(Durable Execution)和断点续传能力,允许系统从错误点恢复而非完全重启。同时,利用模型的智能,让其自主适应工具故障。 -
2. 非确定性调试 (Debugging Non-Deterministic Systems):由于智能体的动态决策,两次运行即便输入相同,路径也可能完全不同,导致Bug难以复现。 -
• 解决方案:传统断点调试失效。必须依赖全链路生产追踪(Production Tracing),在保护用户隐私的前提下,监控决策模式和交互结构,从宏观层面诊断问题根源。 -
3. 部署协调 (Deployment Coordination):如何更新一个7×24小时运行、包含大量长耗时任务的系统? -
• 解决方案:采用彩虹部署(Rainbow Deployments)。新旧版本同时在线,流量逐步切换,同时允许旧版本上的现有任务继续运行至完成,实现平滑过渡。
真实世界的应用:谁在用,做什么?
多智能体研究系统已经在高价值的知识密集型领域展现出巨大影响力。

用户画像解读:这张Clio嵌入图谱揭示了产品的核心应用场景(PMF)。排名前列的包括:
-
• 软件系统开发 (10%): 在特定领域进行系统设计与开发。 -
• 专业内容创作 (8%): 开发和优化技术文档、报告等。 -
• 商业策略制定 (8%): 研究市场趋势,制定增长和营收策略。 -
• 学术研究 (7%): 辅助学术探索和教育材料开发。 -
• 信息核查 (5%): 对人物、地点或组织进行深度背景调查。
用户反馈称,该系统帮助他们“发现了未曾考虑过的商业机会”、“解决了复杂的技术难题”,甚至“节省了数天的工作量”。
总结与展望
多智能体系统不只是对现有AI能力的增量改进,它代表着一种根本性的范式转移——从追求个体智能到构建集体智能。
尽管从原型到生产的“最后一公里”充满挑战,但其背后的架构模式和工程原则正逐渐清晰。对于产品经理和AI工程师而言,未来AI产品的竞争力,将越来越多地取决于我们如何设计、组织和驾驭这些能协同作战的AI系统。
AI协同的新纪元,已经到来。
(文:子非AI)