
这次,Meta 不玩表面功夫了!
他们直接从底层动手,用BLT(Byte Latent Transformer)新架构,干掉了传统的分词器,让模型直接处理原始字节数据!

这个BLT可不是三明治,而是一个全新的字节级LLM架构。
它不仅能在规模上匹配基于分词的LLM性能,还在推理效率和鲁棒性上实现了显著提升!
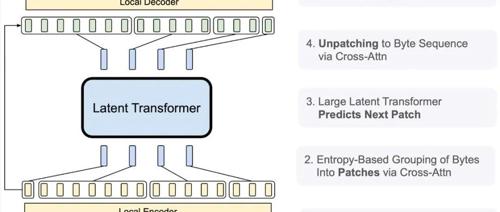
BLT:一个不一样的三明治架构

BLT的架构像一个三明治:
-
底层是轻量级局部编码器,处理原始字节
-
中间是强大的潜在Transformer,处理动态补丁
-
顶层是轻量级局部解码器
最妙的是它用了一个「熵补丁」技术,能根据数据复杂度动态调整补丁大小。简单的预测用大补丁,复杂的预测用小补丁,这样就能把计算资源用在刀刃上!
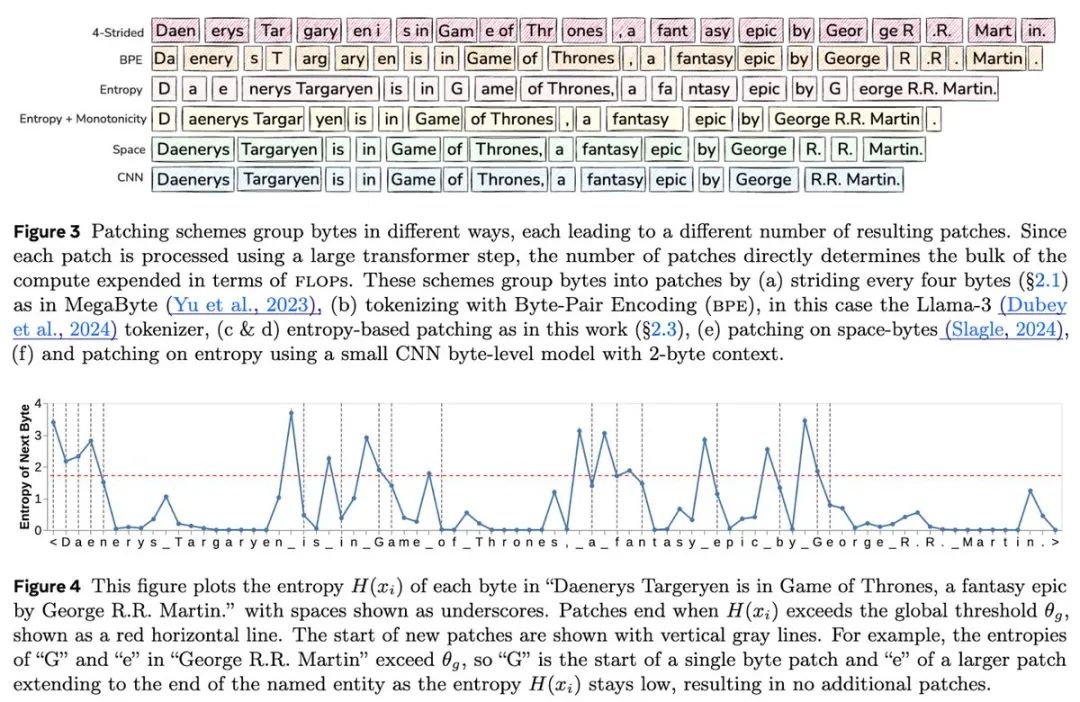
玩转规模效应
实验结果显示,BLT在规模扩展上有惊人表现:
-
支持同时增加补丁和模型大小,而不增加训练或推理成本
-
在400B到1T字节的训练数据上,快速超越了BPE分词方式的Llama 2和3
-
在8B参数和4T训练字节的规模下,完全匹配了Llama 3的性能
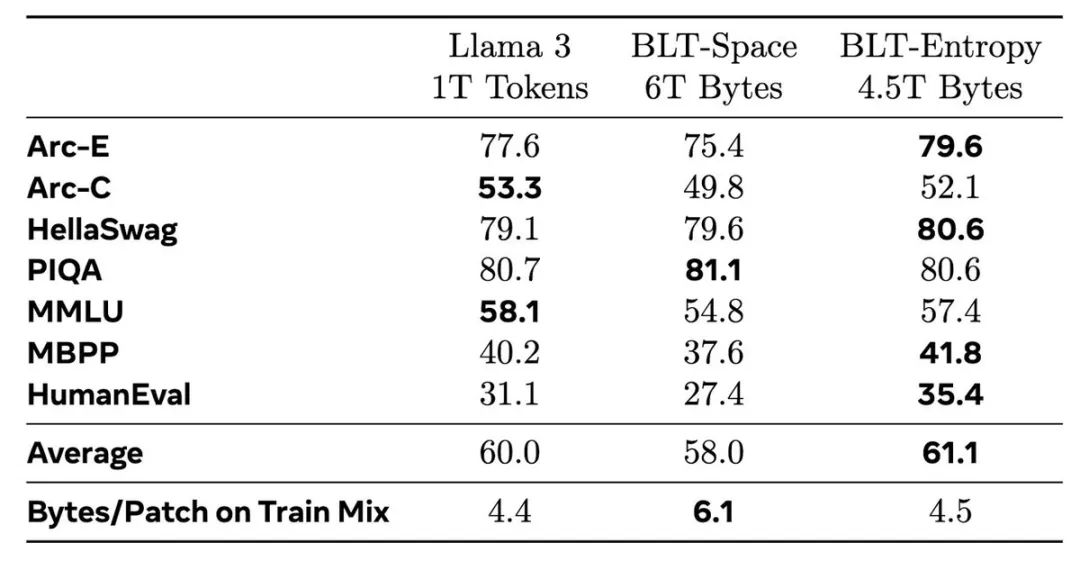
效率惊人
BLT不仅性能强,效率更是惊人:
-
可以用相同的推理成本换取更大的模型规模
-
在保持训练效率的同时,可节省高达50%的推理计算量
-
特别擅长处理数据的长尾分布,对噪声更鲁棒
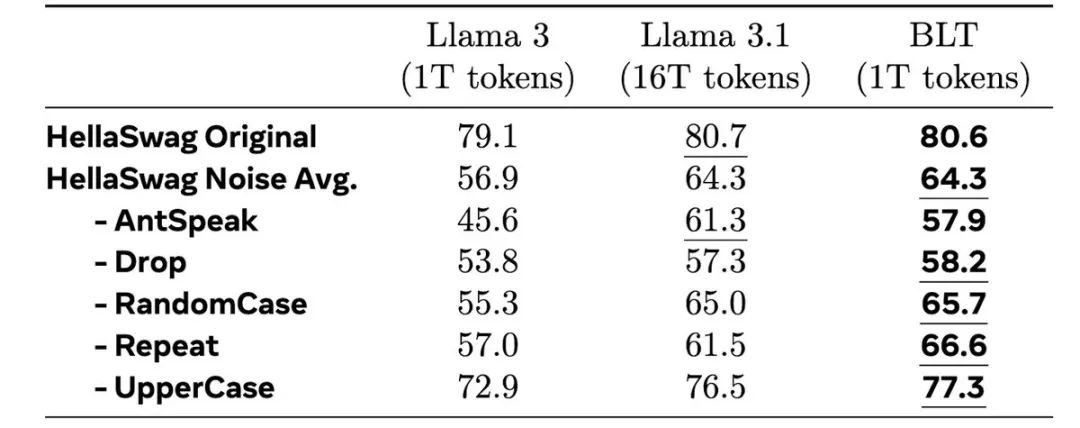
意想不到的优势
最让人惊喜的是,BLT在一些特殊任务上表现出众:
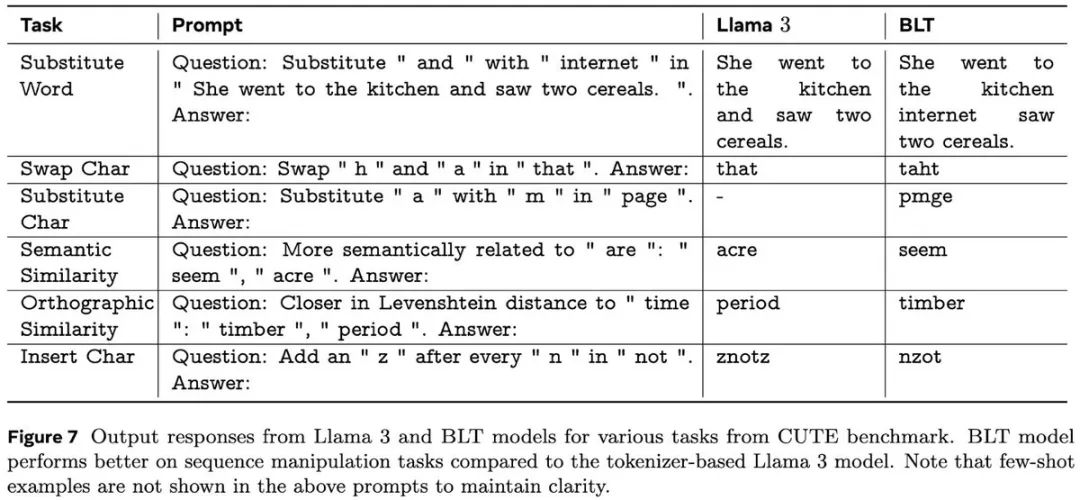
即便是训练了16倍数据量的Llama 3.1,在某些任务上也追不上BLT的表现!
该架构已经开源,代码可在GitHub上获取:
https://github.com/facebookresearch/blt
论文见:
https://dl.fbaipublicfiles.com/blt/BLT__Patches_Scale_Better_Than_Tokens.pdf
(文:AGI Hunt)