


作者:椰椰
编辑:李宝珠
转载请联系本公众号获得授权,并标明来源
「HealthGPT:AI 医疗助手」已上线至 HyperAI超神经官网的「教程」板块,仅需上传医疗影像,便可开启与专业医生媲美的问诊对答,快来体验吧~
现代医学诊断与研究高度依赖医学影像的解读与生成,从 X 光片的病灶识别到 MRI 向 CT 的图像转换,每一个环节都对 AI 系统的多模态处理能力提出了严苛要求。然而,当前医疗视觉语言模型(LVLMs)发展面临双重瓶颈:一方面,医疗数据的特殊性导致大规模高质量标注数据稀缺,公开可用的医学影像数据集规模通常仅为通用数据集的万分之一,难以支撑从零构建统一模型的需求;另一方面,理解与生成任务的内在矛盾难以调和——理解任务需要抽象语义概括,而生成任务要求细节精准保留,传统混合训练往往导致「顾此失彼」的性能衰减。
从技术演进来看,早期医疗 LVLMs 如 Med-Flamingo、LLaVA-Med 等主要聚焦于视觉理解任务,通过图像-文本对齐实现医学影像的语义解读,但缺乏「可视化」生成能力。而通用领域的统一 LVLMs 如 Unified-IO 2、Show-o 等,虽具备生成功能,却因医疗数据适配不足,在专业任务上表现欠佳。2024 年诺贝尔化学奖授予 AI 蛋白质结构预测领域的突破,从侧面印证了 AI 在生命科学领域的潜力,也让学术界意识到:构建兼具理解与生成能力的医疗 LVLMs,已成为突破当前医疗AI应用瓶颈的关键。
对此,浙江大学联合中国电子科技大学等团队提出 HealthGPT 模型,通过创新性的异构知识适配框架,成功构建了首个统一医疗多模态理解与生成的大规模视觉语言模型,为医疗 AI 的发展开辟了新路径,相关成果已入选 ICML 2025。
论文地址:
https://go.hyper.ai/OtAQQ
针对医疗数据限制与任务冲突两大挑战,研究团队提出了三层递进式解决方案:
首先,设计异构低秩适应(H-LoRA)技术,通过任务门控解耦机制,将理解与生成知识存储在独立「插件」中,避免传统联合优化的冲突问题;
其次,开发分层视觉感知(HVP)框架,利用 Vision Transformer 的层次化特征提取能力,为理解任务提供抽象语义特征,为生成任务保留细节视觉特征,实现「按需供给」的特征调控;
最后,构建三阶段学习策略(TLS),从多模态对齐到异构插件融合,再到视觉指令微调,逐步赋予模型专业化的多模态处理能力。
数据集:VL-Health 的多模态医疗知识图谱
为支撑 HealthGPT 的训练,研究团队构建了首个面向医疗多模态理解与生成的综合数据集 VL-Health。该数据集整合了 76.5 万理解任务样本和 78.3 万生成任务样本,覆盖 11 种医学模态(包括 CT、MRI、X 光、OCT 等)和多类疾病场景(从肺部疾病到脑部肿瘤)。
数据集地址:
https://hyper.ai/cn/datasets/40990
在理解任务方面,VL-Health 融合了 VQA-RAD(放射学问题)、SLAKE(语义标注知识增强)、PathVQA(病理学问答)等专业数据集,并补充 LLaVA-Med、PubMedVision 等大规模多模态数据,确保模型学习从基础影像识别到复杂病理推理的全链条能力。生成任务则主要聚焦模态转换、超分辨率、文本-图像生成和图像重建四大方向:
数据处理阶段,团队对医学影像进行了标准化预处理,包括切片提取、图像配准和数据增强,并将所有样本统一为「指令-响应」格式,便于模型的指令跟随训练。
模型架构:从视觉感知到自回归生成的全链条设计
HealthGPT 采用「视觉编码器-LLM 核心-H-LoRA 插件」的分层架构,实现多模态信息的高效处理:
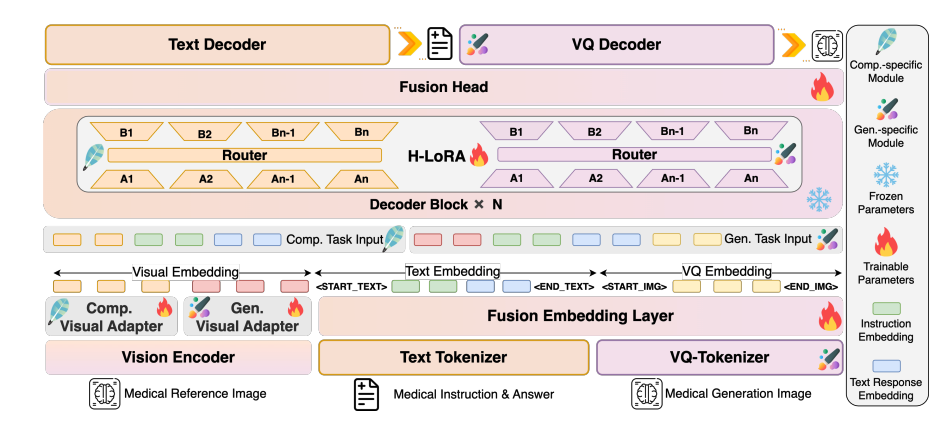
模型架构图
视觉编码层:分层特征提取
采用 CLIP-L/14 作为视觉编码器,提取浅层(第 2 层)和深层(倒数第 2 层)特征。浅层特征通过 2 层 MLP 适配器转换为具体粒度特征,保留图像细节;深层特征经适配器处理为抽象粒度特征,捕获语义概念。这种双轨特征提取机制,为后续的理解与生成任务提供了适配的视觉表示。
LLM 核心:通用知识基座
基于 Phi-3-mini 和 Phi-4 构建 2 类不同参数的模型:HealthGPT-M3(模型参数量为 3.8B)和 HealthGPT-L14(模型参数量为 14B)。LLM 核心不仅负责文本理解与生成,还通过自回归机制统一处理视觉 token 序列——理解任务时输出文本响应,生成任务时输出 VQGAN 索引序列,再通过 VQGAN 解码器重建图像。
H-LoRA 插件:任务专属适配器
在 LLM 的每个 Transformer 块中插入 H-LoRA 插件,包括理解和生成两类子模块。每个子模块包含多个 LoRA 专家,通过任务类型和输入隐藏状态动态路由,实现知识的选择性激活。插件与 LLM 的冻结权重结合,形成「通用知识+任务专长」的混合推理模式。
实验结论:HealthGPT 在医学视觉理解与生成任务上大幅领先
理解任务:专业能力全面领先
在医疗视觉理解任务上,HealthGPT 大幅超越现有模型。通过将 HealthGPT 与其他医学专用和通用模型比较(例如 Med-Flamingo、LLA-VA-Med、HuatuoGPT-Vision、BLIP-2 等),结果表明,HealthGPT 在医疗视觉理解任务中表现出色,显著优于其他医学专用和通用模型。
在 VQA-RAD 数据集上,HealthGPT-L14 达到 77.7% 的准确率,较 LLaVA-Med 提升 29.1%;在 OmniMedVQA 基准测试中,其平均得分 74.4%,在 CT、MRI、OCT 等 7 个子任务中 6 项取得最优,尤其在复杂的 MRI 模态理解上准确率高达 99.7%,展现出对高难度医学影像的深度理解能力。
生成任务:模态转换与超分辨率的突破
生成任务实验显示,HealthGPT 在医学图像转换与增强中表现卓越。在 CT-MRI 模态转换任务中,HealthGPT-M3 的 SSIM 指标达到 79.38(Brain CT2MRI),较传统方法 Pix2Pix 提升 11.6%,且在骨盆等复杂区域的转换精度同样领先;超分辨率任务上,其 SSIM 达 78.19,PSNR 32.76,在细节恢复上超越 SRGAN、DASR 等专用模型,尤其在脑部结构的精细重建上优势明显。
值得注意的是,HealthGPT 能够在单一模型中处理多种生成任务,而传统方法需为每个子任务训练独立模型,凸显了统一框架的效率优势。
方法有效性验证:H-LoRA 与三阶段策略的价值
消融实验证实了核心技术的必要性:移除 H-LoRA 后,理解与生成任务的平均性能下降 18.7%;采用混合训练而非三阶段策略时,任务冲突导致性能衰减 23.4%。
H-LoRA 与 MoELoRA 的对比显示,当使用 4 个专家时,H-LoRA 训练时间仅为 MoELoRA 的 67%,但性能提升 5.2%,证明了其在计算效率与任务表现上的双重优势。分层视觉感知的作用也得到验证——理解任务使用抽象特征时收敛速度提升 40%,生成任务采用具体特征时图像保真度提高 25%。
临床应用潜力:从研究到实践的桥梁
Human Evaluation 实验中,5 名临床医生对 1,000 个开放问题的回答进行盲评,HealthGPT-L14 的回答被选为「最佳答案」的比例达 65.7%,远超 LLaVA-Med(34.08%)和 HuatuoGPT-Vision(21.94%)。
目前,HyperAI超神经官网(hyper.ai)的教程板块已上线「HealthGPT:AI 医疗助手」教程。仅需上传医疗影像,便可开启与专业医生媲美的问诊对答,快来体验吧!
教程链接:
https://go.hyper.ai/jifgl
Demo 运行
1.进入 hyper.ai 首页后,选择「教程」页面,并选择「HealthGPT:AI 医疗助手」,点击「在线运行此教程」。
2.页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
3.选择「NVIDIA RTX A6000」以及「PyTorch」镜像,OpenBayes 平台提供了 4 种计费方式,大家可以按照需求选择「按量付费」或「包日/周/月」,点击「继续执行」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
HyperAI超神经专属邀请链接(直接复制到浏览器打开):
https://openbayes.com/console/signup?r=Ada0322_NR0n
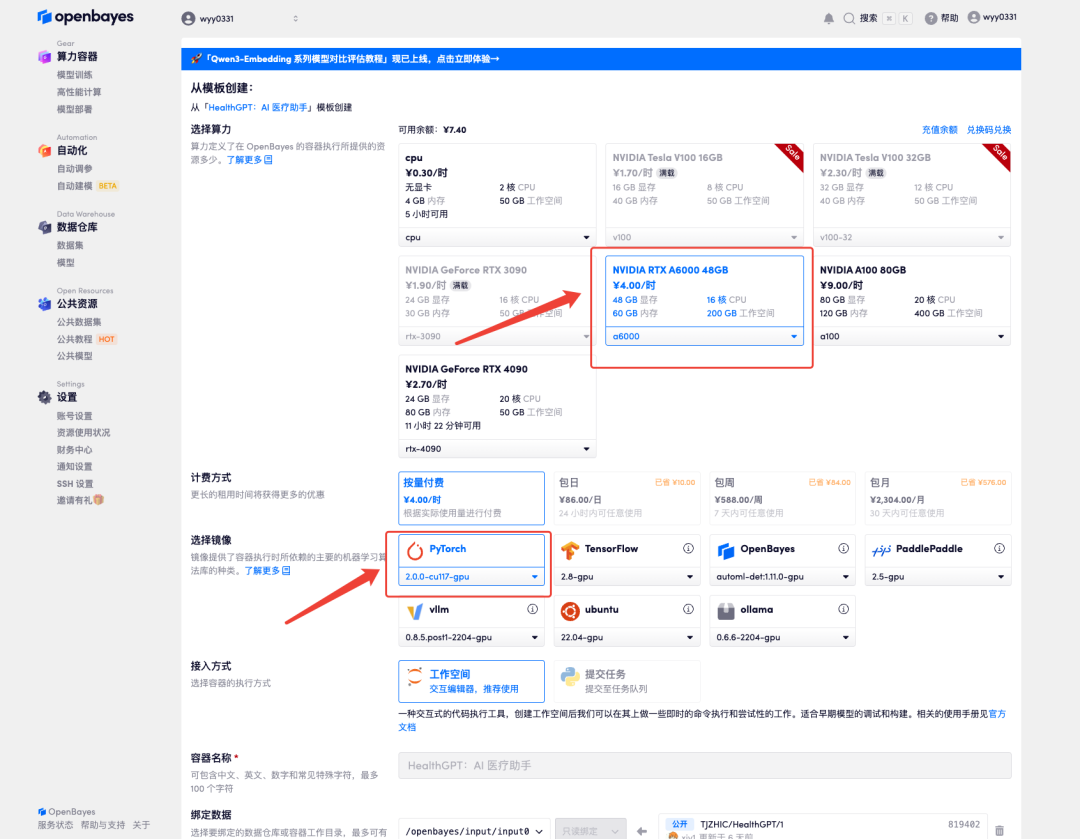
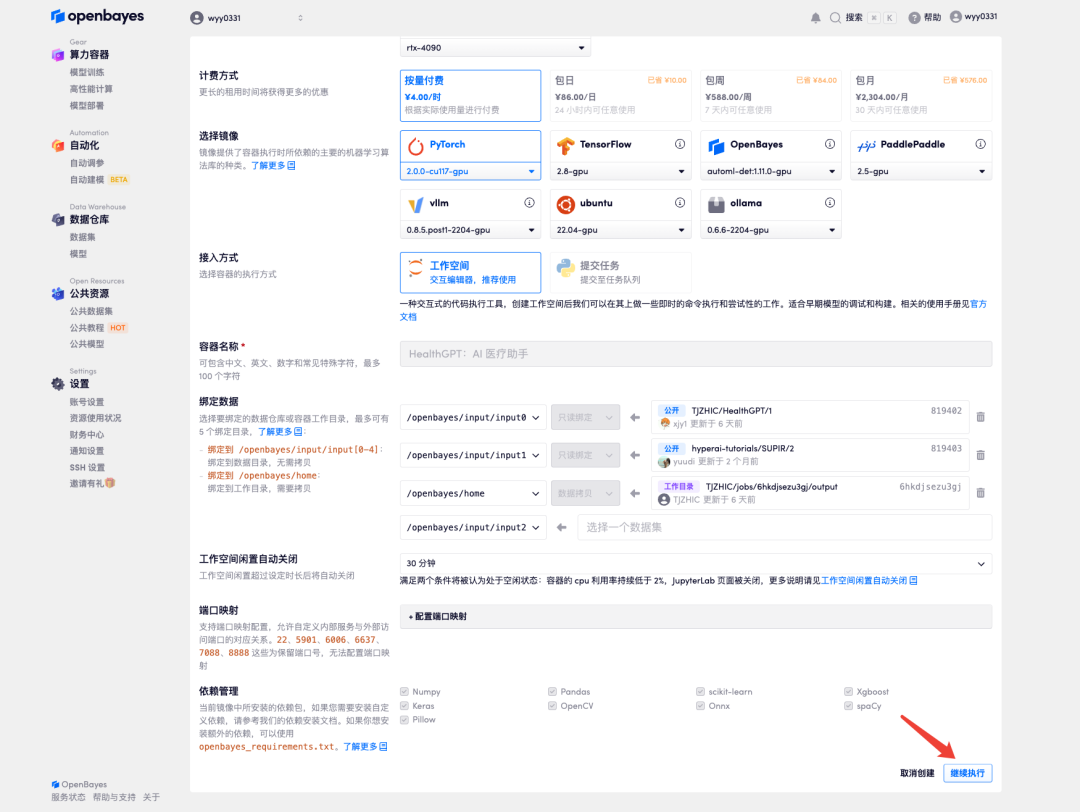
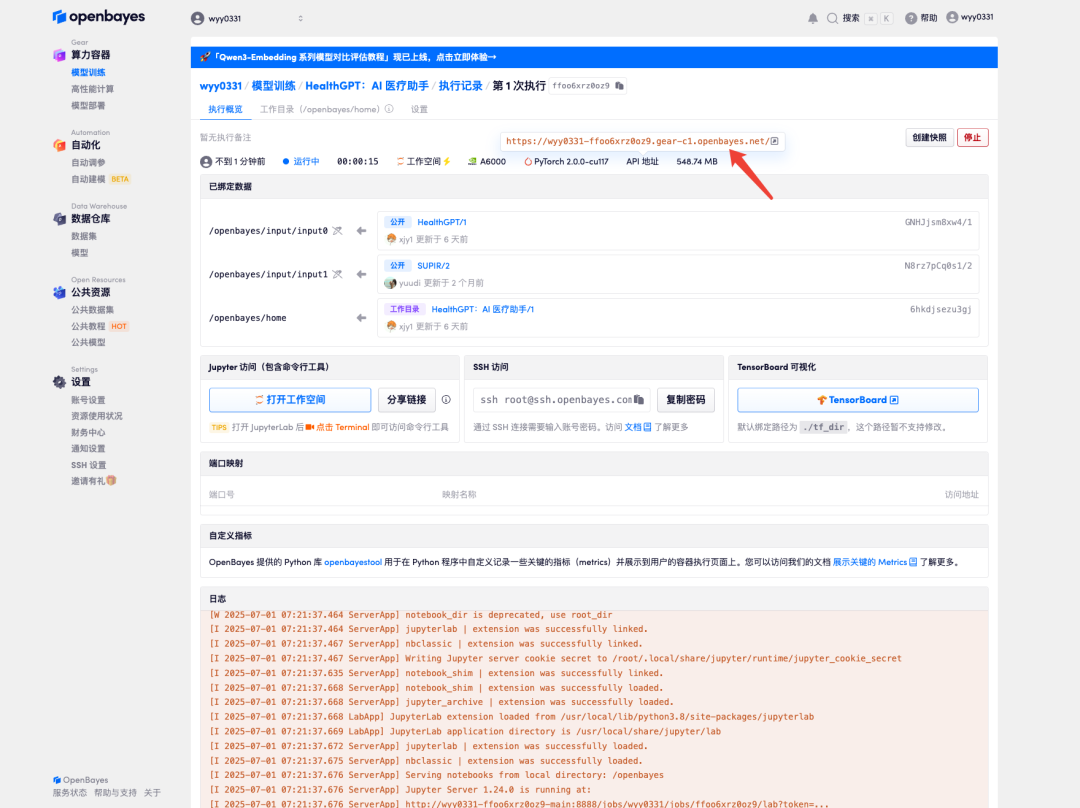
4.等待分配资源,首次克隆需等待 2 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」旁边的跳转箭头,即可跳转至 Demo 页面。由于模型较大,需等待约 3 分钟显示 WebUI 界面,否则将显示「Bad Gateway」。请注意,用户需在实名认证后才能使用 API 地址访问功能。
效果演示
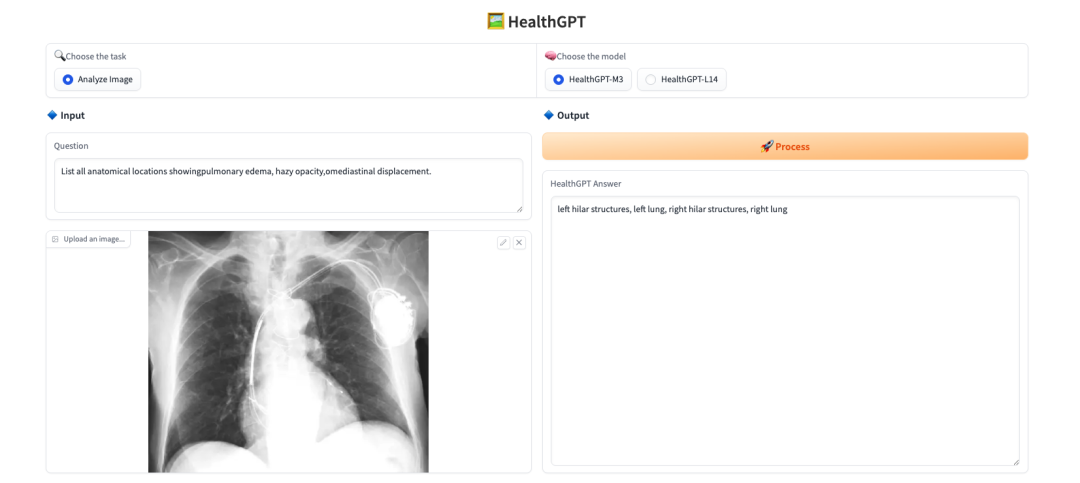
上传一张图片,在「Question」处输入想问的问题,「Choose the model」选择模型,点击「Process」即可实时进行解答。
回复案例如下图所示:
以上就是 HyperAI超神经本次推荐的教程,欢迎感兴趣的读者前来体验 ⬇️
教程链接:
https://go.hyper.ai/jifgl



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)