

今天是2025年7月3日,星期四,北京,雨
先来看多模态RAG进展,关于这块,已经在多模态RAG专题中介绍过很多了。
其中提到最多的,就是ColBERT、ColPali这两类embedding模型,不过,从技术角度上讲,两者存在一定局限性。
例如:
ColBERT和ColPali可以检索到了包含相关信息的页面,但仅检索到页面是不够的,还需要进一步分析页面中的具体内容;
ColBERT仅依赖文本信息,未能准确解析文本中的数值数据,例如,在某些场景下或错误地得出“外国出生的拉丁裔人口更多”的结论;
此外,标准的多模态RAG框架,例如M3DocRAG,虽然结合了文本和图像信息,但由于缺乏对关键信息的细致提取和跨模态整合能力,未能正确回答问题。
因此,针对这个问题,一个很自然的方式,就是召回后,再做一些内容上的过滤,再贴点边,就是跟Agent相结合,所以,就搞个Agent? 那么可以怎么玩?看一个工作。
另外,说到文档处理,那么,就可以再看看文档预处理,尤其是一些不规则的非印刷体文档,如何做标准化,这个对RAG也很重要。
一、MDocAgent多模态RAG思路
最近的工作《MDocAgent: A Multi-Modal Multi-Agent Framework for Document Understanding》,https://arxiv.org/pdf/2503.13964,https://github.com/aiming-lab/MDocAgent,多模态多智能体框架,利用文本和图像信息来提高文档问答的准确性。
1、有哪几个Agent?
五个专门的Agent:General Agent、Critical Agent、Text Agent、Image Agent、Summarizing Agent,每个Agent主要是基于prompt在驱动,具体形势如下:

在具体选型上,使用Llama-3.1-8B-Instruct作为文本智能体的基础模型,Qwen2-VL-7B-Instruct作为其他四个智能体的基础模型,ColBERTv2和ColPali分别作为文本和图像检索器。
2、具体实现步骤是什么?
具体步骤分成5步,如下图所示:
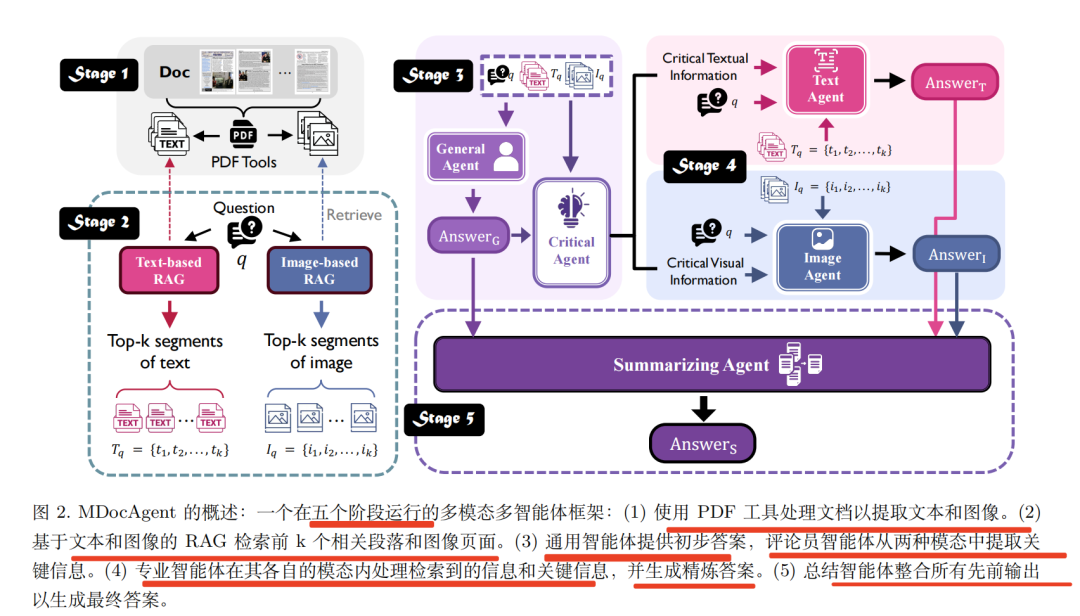
1)文档预处理:使用OCR和PDF解析提取文本,并将每页文档保存为图像,形成文本和视觉表示
2)多模态上下文检索:使用ColBERT和ColPali分别对文本和图像进行检索,获取与问题最相关的文本段和图像页
3)初始分析和关键信息提取:General Agent生成初步答案,Critical Agent提取关键信息,指导文本及图像细分处理进行分析
4)文本及图像细分处理:Text Agent和Image Agent分别在各自模态内分析检索到的上下文,生成详细的答案
5)答案合成:Summarizing Agent综合所有智能体的输出,生成最终答案。可以重点看架构选型。
二、RAG做文档解析的前处理-文档图像增强问题
文档解析是当前RAG系统的重点问题,在实际处理过程中,并非总是会遇到标准的印刷体文档,还会存在一些拍照版本的问题,这个如果不做处理,直接送到layout或者ocr,会影响实际效果。
1、具体存在哪些问题?
这类问题常常表现为几何失真、阴影、污渍等多种问题,如下:

所以,经常需要做去畸变(去扭曲消除几何失真,如弯曲和褶皱)、去阴影、外观增强、去模糊和二值化任务,这个其实也叫文档恢复任务。
那么, 是否可以将这几个任务放在一起做?
前沿的方案可以看《DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks》,代码在:https://github.com/ZZZHANG-jx/DocRes/tree/master,https://arxiv.org/pdf/2405.04408
其意义在于提出一个统一了五种文档图像还原任务的通用模型,包括去扭曲、去阴影、外观增强、去模糊和二值化。
其中:
外观增强(也称为照明校正)不限于特定的退化类型,旨在恢复类似于从扫描仪或数字原生 PDF 文件获得的清晰外观;
去阴影的目的是消除主要由遮挡引起的阴影,以获得无阴影的文档图像;
去扭曲,也称为几何校正,旨在校正受到曲线、折叠、皱褶、透视/仿射变形和其他几何扭曲的文档图像;
1、架构及训练阶段?
架构方面,特征提取网络使用DTPrompt生成器根据指定任务从输入图像中提取先验特征,并将其与输入图像拼接,恢复网络使用Restormer。
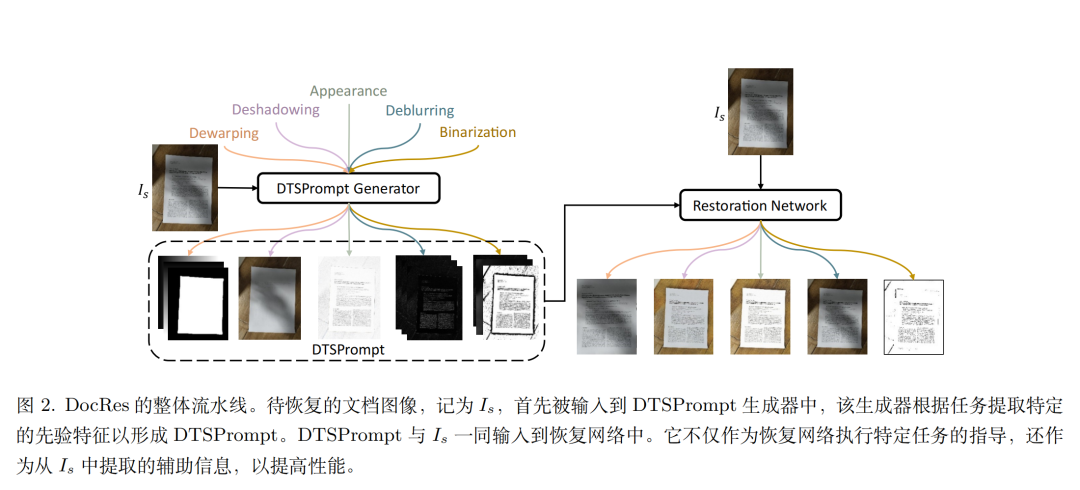
核心两个阶段:
1)动态任务特定提示(DTPrompt),根据输入图像的特征提取不同的先验特征,这些特征包括文档分割掩码、二值化结果、梯度图等,这个解决的是特征提取问题。
2)提示融合和恢复网络:将DTPrompt与输入图像沿通道维度拼接,形成新的输入用于恢复网络,选择Restormer作为恢复网络,并对其进行微调,这个解决的是恢复问题。
2、训练数据有哪些?
数据往往更为重要,这块没办法,还是合成方案居多,例如:
去扭曲处理数据包括Doc3D,一个包含100K样本的合成数据集,其中包括几何扭曲的文档图像及相应的反向映射图。
去阴影数据及包含来自FSDSRD的14200张合成图像和来自RDD训练集的4371张真实图像。
外观增强包含来自Doc3DShade数据集的90K张合成图像和来自RealDAE训练集的450张真实世界图像。
去模糊使用文本去模糊数据集(TDD)包含66K训练样本;二值化使用(H)-DIBCO数据集。
3、看下实际效果
看论文中提到的一些实现效果,包括输入、DTSPrompt、DocRes修复结果及真实值的可视化对比,包括去弯曲、去阴影、外观增强、去模糊 和二值化。

4、关于文档处理这块更进一步的延伸?
如果要文档处理这块有更深的了解,可以看一个技术总结,包含文档图像处理方法的论文集,包括外观增强、去阴影、去扭曲、去模糊和二值化,可以跟一下一个技术总结项目。

地址在:https://github.com/ZZZHANG-jx/Recommendations-Document-Image-Processing
参考文献
1、https://github.com/aiming-lab/MDocAgent
2、https://arxiv.org/pdf/2405.04408
(文:老刘说NLP)