

今天是2025年7月12日,星期六,北京,雨
继续温故而知新,看看四个具有代表性的大模型训练框架,做个记录,包括大模型推理、部署资源计算器。
另外,顺着这个计算器,看看最新万亿参数模型Kimi-K2如果要运行以及微调,那么需要多少资源,来看看几个来源的数据,顺便也说下Deepseek-R1。
重复重复再重复,会有更多的发现和体会。
一、几个具有代表性的大模型训练框架
来看看目前比较流行的4大主流LLM训练框架。包括unsloth, llamafactory等,也包括一个对应的资源估算。
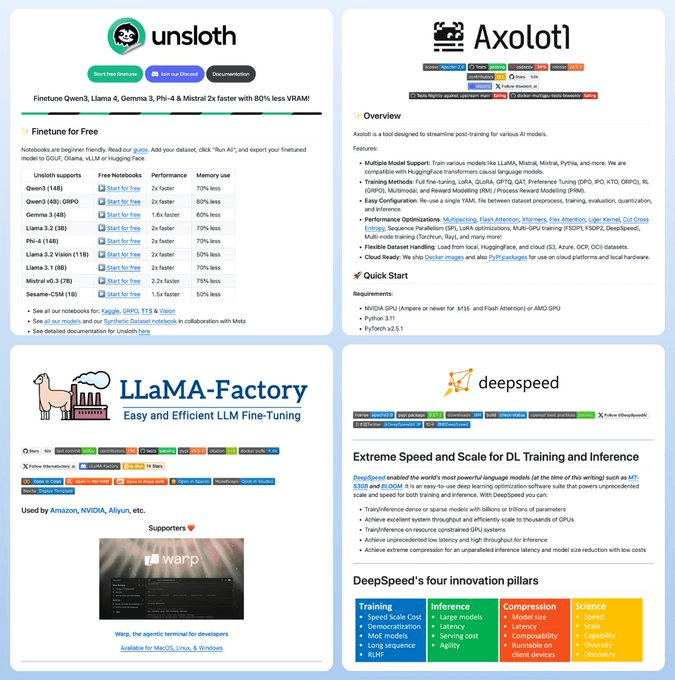
1、Unsloth(42k)
Colab/Kaggle一键微调;Triton内核:2×提速、显存↓80%;支持文本/语音/扩散/BERT,4/8/16bit全量或LoRA/QLoRA,适用:12–24GBGPU、快速实验、无需配置DeepSpeed
地址:https://github.com/unslothai/unsloth
2、Axolotl(10k)
一个YAML跑完整pipeline(数据准备→训练→部署),支持全参、LoRA、QLoRA、RLHF、FlashAttn、XFormers、FSDP、DeepSpeed、Ray,适用:需要可复现、团队级生产;

地址:https://github.com/axolotl-ai-cloud/axolotl
3、LlamaFactory(54k)
零代码Web界面,向导式微调,一键部署OpenAI兼容API;内置FlashAttn-2、LongLoRA、GaLore、DoRA、W&B、MLflow看板,适用:偏好GUI、想快速上线;

地址:https://github.com/hiyouga/LLaMA-Factory
4、DeepSpeed(39k)
支持ZeRO、MoE、3D并行,支撑万亿级训练;ZeroQuant、XTC压缩,亚秒级推理内核,适用:企业或研究,>10B模型、高并发服务
地址:https://github.com/deepspeedai/DeepSpeed
二、大模型推理、部署资源计算器及kimi-k2,R1资源要求
继续关注落地,输入模型、量化方式、批大小、硬件配置,可以估算LLM显存,包括生成速度(token/s)、显存占用明细、系统吞吐,目内置75款开源模型(DeepSeek、Gemma、Llama 3/4、Qwen…),也包括最新的kimi-k2,可以从这个里面设定参数找到答案。
(文:老刘说NLP)