



一、项目概述
MOSS-TTSD(Text to Spoken Dialogue)是由清华大学语音与语言实验室(Tencent AI Lab)开发的开源口语对话语音生成模型。它基于先进的语义 – 音学神经网络音频编解码器和大规模预训练语言模型,结合超过100万小时的单人语音数据和40万小时的对话语音数据进行训练,能够将文本对话脚本转化为自然流畅、富有表现力的对话语音,支持中英文双语生成,并具备零样本语音克隆能力,可广泛应用于AI播客、访谈、新闻报道等多种场景,为语音合成领域带来了重大突破。
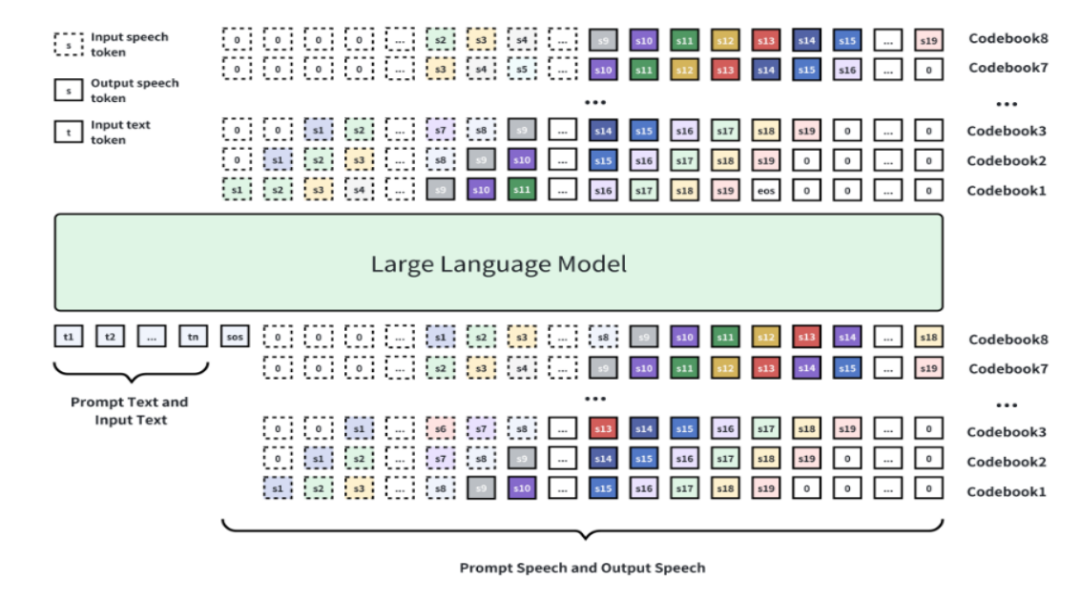
二、技术原理
(一)基础模型架构
MOSS-TTSD基于Qwen3 – 1.7B-base模型进行续训练,采用离散化语音序列建模方法。通过八层RVQ(Residual Vector Quantization)码本对语音进行离散化处理,将连续的语音信号转换为离散的token序列。这些token序列通过自回归加Delay Pattern的方式生成,最后通过Tokenizer的解码器将token还原为语音。
(二)语音离散化与编码器创新
核心创新之一是XY – Tokenizer,这是专门设计的语音离散化编码器。XY – Tokenizer采用双阶段多任务学习方式训练:
1. 第一阶段:训练自动语音识别(ASR)任务和重建任务,让编码器在编码语义信息的同时保留粗粒度的声学信息。
2. 第二阶段:固定编码器和量化层,仅训练解码器部分,通过重建损失和GAN损失补充细粒度声学信息。XY – Tokenizer在1kbps的比特率和12.5Hz的帧率下,能同时建模语义和声学信息,性能优于其他同类Codec。
(三)数据处理与预训练
MOSS-TTSD使用了约100万小时的单说话人语音数据和40万小时的对话语音数据进行训练。团队设计了高效的数据处理流水线,从海量原始音频中筛选出高质量的单人语音和多人对话语音进行标注。模型进行了TTS预训练,使用110万小时的中英文TTS数据显著增强了语音韵律和表现力。
(四)长语音生成能力
基于超低比特率的Codec,MOSS-TTSD支持最长960秒的音频生成,能一次性生成超长语音,避免了拼接语音片段之间的不自然过渡。
三、主要功能
(一)高表现力对话语音生成
MOSS-TTSD能够将对话脚本转换为自然、富有表现力的对话语音,准确捕捉对话中的韵律、语调等特性,生成的语音听起来就像真实的人在对话一样自然流畅。
(二)零样本多说话人音色克隆
支持根据对话脚本生成准确的对话者切换语音,无需额外样本即可实现两位对话者的音色克隆。这意味着用户无需提供额外的语音样本,模型就能自动匹配对话脚本中的不同说话者,并生成相应音色的语音,大大提高了使用便捷性。
(三)中英双语支持
MOSS-TTSD可在中文和英文两种语言中生成高质量的对话语音,满足不同语言环境下的应用需求,拓宽了其应用场景。
(四)长篇语音生成
基于低比特率编解码器和优化的训练框架,MOSS-TTSD能够一次性生成超长语音,避免拼接语音片段的不自然过渡,这对于需要生成长篇对话内容的场景非常有帮助,例如长篇访谈、新闻报道等。
(五)完全开源且商业就绪
模型权重、推理代码和API接口均已开源,支持免费商业使用。这为开发者提供了极大的便利,他们可以自由地使用该模型进行二次开发和创新,同时也为企业在相关领域的应用提供了成本效益。
四、应用场景
(一)AI播客制作
MOSS-TTSD能够生成自然流畅的对话语音,特别适合用于AI播客的制作。它可以模拟真实的对话场景,生成高质量的播客内容,为听众带来全新的听觉体验。
(二)影视配音
模型支持中英双语的高表现力对话语音生成,能进行零样本音色克隆,适用于影视作品中的对话配音。它可以为角色生成符合其性格和情感的语音,提升影视作品的配音质量。
(三)长篇访谈
MOSS-TTSD支持最长960秒的音频生成,能一次性生成超长语音,避免了拼接语音片段之间的不自然过渡,非常适合长篇访谈的语音生成。这使得访谈内容听起来更加连贯自然,增强了听众的收听体验。
(四)新闻报道
在新闻报道中,MOSS-TTSD可以生成自然的对话式语音,用于播报新闻内容,提升新闻的吸引力。它可以根据新闻稿件生成主播和嘉宾的对话语音,让新闻报道更具互动性和生动性。
(五)电商直播
模型可以用于数字人对话带货等电商直播场景,通过生成自然的对话语音来吸引观众。它可以模拟主播和观众之间的互动对话,提高直播的趣味性和观众的参与度。
五、快速使用
(一)环境搭建
1. 安装依赖
使用conda创建虚拟环境并安装依赖:
conda create -n moss_ttsd python=3.10 -y && conda activate moss_ttsdpip install -r requirements.txtpip install flash-attn
2. 下载XY Tokenizer模型权重
mkdir -p XY_Tokenizer/weightshuggingface-cli download fnlp/XY_Tokenizer_TTSD_V0 xy_tokenizer.ckpt --local-dir ./XY_Tokenizer/weights/
(二)本地推理
1. 准备输入文件
创建一个JSONL格式的输入文件,包含对话脚本和说话者提示信息。例如:
{"base_path": "examples","text": "[S1]Speaker 1 dialogue content[S2]Speaker 2 dialogue content[S1]...","prompt_audio_speaker1": "path/to/speaker1_audio.wav","prompt_text_speaker1": "Reference text for speaker 1 voice cloning","prompt_audio_speaker2": "path/to/speaker2_audio.wav","prompt_text_speaker2": "Reference text for speaker 2 voice cloning"}
2. 运行推理脚本
python inference.py --jsonl examples/examples.jsonl --output_dir outputs --seed 42 --use_normalize(三)Web UI使用
运行以下命令启动Gradio Web UI:
python gradio_demo.py通过浏览器访问生成的本地地址,即可在Web界面中输入对话脚本并生成语音。
六、结语
MOSS-TTSD作为清华大学语音与语言实验室开源的口语对话语音生成模型,凭借其高表现力的对话语音生成能力、零样本多说话人音色克隆功能以及中英双语支持等特点,在AI播客、影视配音、新闻报道等多个领域展现出巨大的应用潜力。其完全开源且支持商业使用的特性,也为开发者和企业提供了极大的便利。
七、项目地址
项目官网:https://www.open-moss.com/en/moss-ttsd/
Github仓库:https://github.com/OpenMOSS/MOSS-TTSD
HuggingFace模型库:https://huggingface.co/fnlp/MOSS-TTSD-v0.5
在线体验Demo:https://huggingface.co/spaces/fnlp/MOSS-TTSD
(文:小兵的AI视界)