


Prologue
关于Swizzle的原理,网上已经有大量的技术博客对其进行了解读。此类博客中,大多数都是以一个固定的共享内存逻辑Layout和一组固定的BMS参数为例,来分析这组BMS参数如何将逻辑Layout转换为访问时无Bank Conflict的物理Layout。从一个初学者的角度来说,很自然的就会提出一个问题:假如我们面对一个新的共享内存逻辑Layout,我们应该如何选择BMS参数呢?关于这一个问题,网上似乎并没有太多相关的解答。因此,在本文中,我会谈一谈我个人对于这个问题的思考和理解。本文包含大量的个人观点,若有不足之处也请各位网友们在评论区批评指正,欢迎大家积极讨论。
注:阅读本文需要对Swizzle的基本原理有一定的了解,如果读者对于Swizzle的基本原理并不了解,可以阅读reed大佬的CuTe系列文章(https://zhuanlan.zhihu.com/p/671419093)。
Swizzle<B, M, S>
在本文中,我们仍然以广泛使用的共享内存逻辑Layout——(8, 32):(32, 1)为例,来探索如何一步一步的确定M,S,和B三个参数。
M & S
首先,我个人认为,Swizzle模板参数中的M和S与PTX指令ldmatrix以及GPU共享内存的多Bank结构高度相关。
在本系列之前的文章(https://zhuanlan.zhihu.com/p/702818267)中,我们了解到,ldmatrix以warp为单位,从共享内存中加载一个或多个8×8子矩阵到warp threads的寄存器中。由于我们的参考Layout——(8, 32):(32, 1)是行主序的,因此,我们以行主序的8×8子矩阵为例进一步展开说明,对于行主序的8×8子矩阵,ldmatrix指令要求一行的8个元素为一组,整个8×8子矩阵共分为8组,每一组元素占据共享内存中的一段连续的地址空间,但不同的组不需要在地址上连续。
此时,我们可以将一行的8个元素视为一个整体,当作一个新的“元素”,进一步简化ldmatrix的加载行为——我们认为ldmatrix分一次或多次加载,每次加载8个“元素”,这8个“元素”位于共享内存中。
对于这种新的类型的“元素”,它由8个基本元素(half/bfloat16)构成,每个基本元素为2Byte,因此,每个新类型的“元素”的大小为16Byte。16Byte占据共享内存连续的4的Bank,而共享内存的的32个Bank恰好能够提供并行访问8个“元素”的能力。
此时,我们可以将共享内存的多Bank结构也进一步简化,我们可以认为共享内存只有8个”Bank”,每个”Bank”的宽度恰好能够容纳一个“元素”,8个”Bank”恰好能够提供并行访问8个“元素”的能力。
现在,Swizzle任务的目标就变得更加简单和清晰——一条ldmatrix指令会发起一次或多次加载,每次加载8个“元素”,这些“元素”分布在具有8个”bank”的共享内存中,每个”bank”的宽度恰好能容纳一个“元素”,整个共享内存能够提供并行访问8个“元素”的能力。现在,Swizzle的任务就是——寻找到一种Layout排布方式,使ldmatrix指令每发起一次加载动作时,都能无Bank Conflict的并行加载所需的8个“元素”。
Swizzle模板参数中的M和S用于表达上述的抽象简化过程:
-
模板参数M:新类型的“元素”由 个基本元素构成——在上文中,M对应为3,表示新的类型的“元素”,它由8个基本元素(half/bfloat16)构成。
-
模板参数S:新类型“元素”的大小确定后,我们可以进一步推算共享内存能够提供几路并行访问能力,即新的”Bank”数,用 表示——在上文中,S对应为3,表示共享内存具有8个新的”bank”,能够提供并行访问8个新类型“元素”的能力。
接下来,我们将参考Layout——(8, 32):(32, 1)带入上述的抽象简化过程。我们以新类型“元素”的视角,将Layout简化为(8, 4):(4, 1),并将其放入具有8个”Bank”的共享内存,此时新类型的“元素”与新”Bank”的映射关系如图1所示:
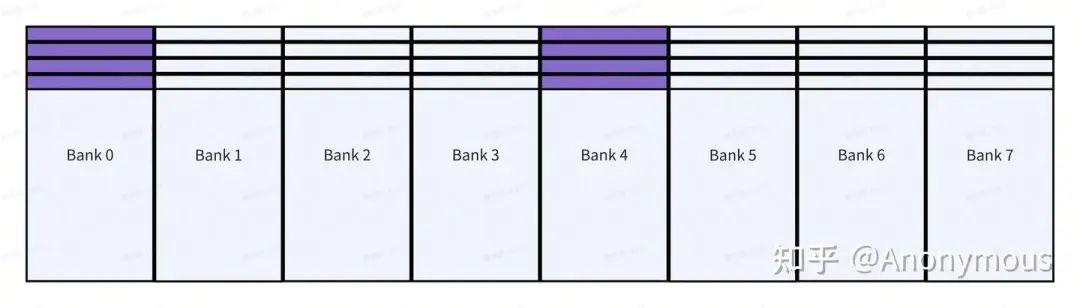
由于简化后的参考Layout仅有4列,但共享内存包含8个”Bank”,因此,简化Layout的第一行占据”Bank”0~3,第二行占据”Bank”4~7,依此类推。
对于ldmatrix指令,每次加载的8个“元素”为简化后的Layout的一列,这里我们以第一列为例,图1中的紫色部分代表第一列“元素”,可见第一列元素占据”Bank”0和”Bank”4,每个”Bank”包含第一列的4个“元素”,显然,此时ldmatrix的加载操作会导致4-way bank conflict。接下来,就需要Swizzle的模板参数B来指定Swizzle的行数以避免bank conflict。
B
确定了Swizzle模板参数S,即新的共享内存”bank”数后,Swizzle模板参数B代表了进一步以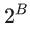 行为基本单位执行Swizzle重映射。
行为基本单位执行Swizzle重映射。
对于上文示例中”bank”数为8的情况,若指定B=2,则Swizzle重映射关系如图2所示:
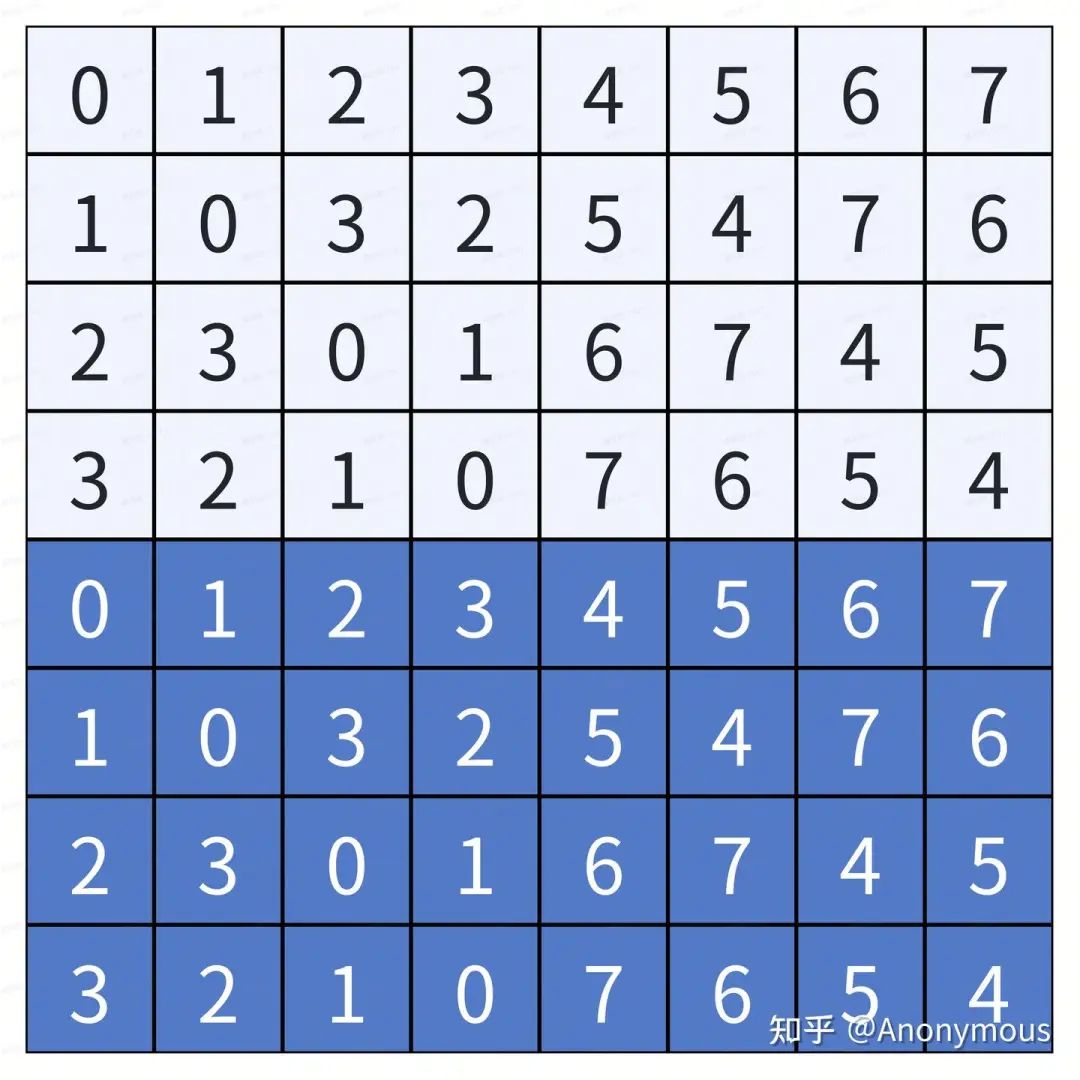
在图2中我们可以观察到,Swizzle是以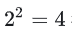 行为单位的,后4行与前4行的重映射关系是完全相同的。
行为单位的,后4行与前4行的重映射关系是完全相同的。
如果指定B=3,那我们就又可以得到这张经典的Swizzle映射关系图:
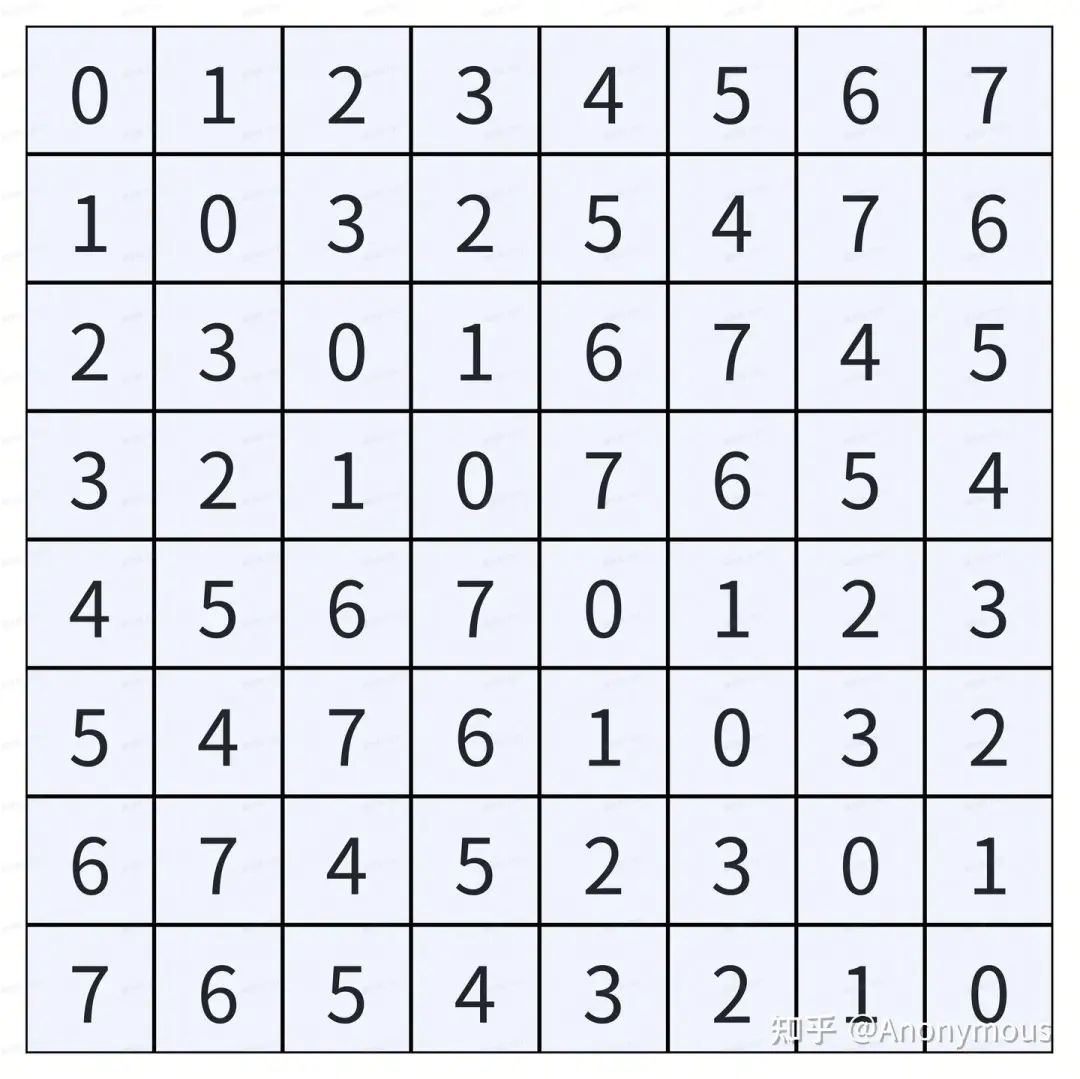

static_assert(abs(num_shft)>=num_bits,"abs(SShift) must be more than BBits."); // S >= B对于上文中,参考Layout发生4-way bank conflict的情况,我们可以指定B=2,以4行为基本单位进行Swizzle重映射,如下图所示:
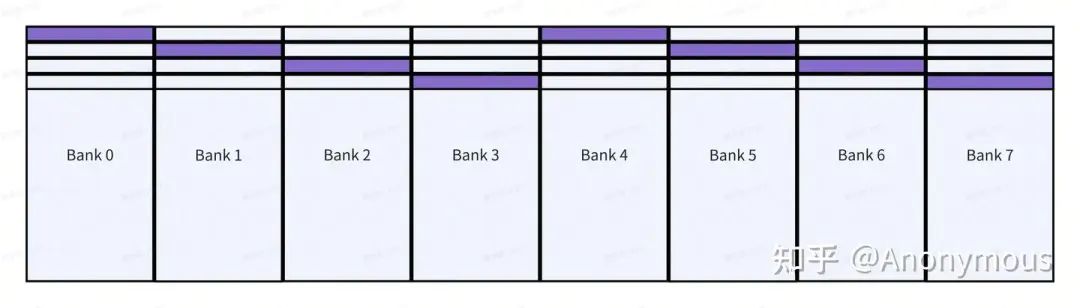
此时,我们访问任意一列,都不会出现bank conflict。但如果我们指定B=1,即以两行为基本单位进行Swizzle重映射,虽然可以避免4-way bank conflict的情况,但仍然会存在2-way bank conflict的情况,如下图所示:
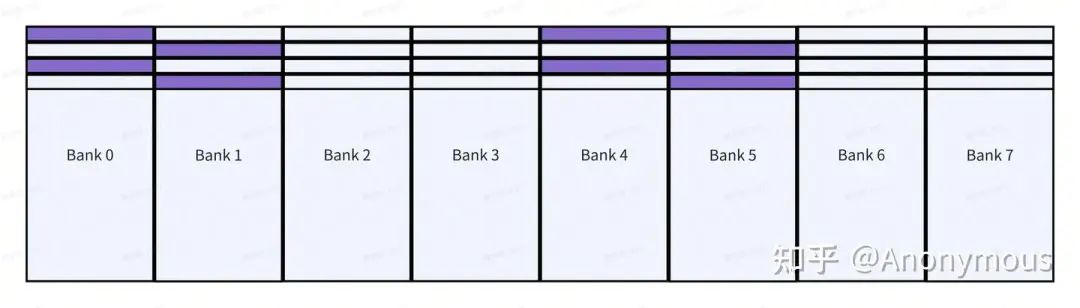
显然,B=2就已经能够满足我们的需求了,但网上许多博客对于(8, 32):(32, 1)这个Layout,均使用Swizzle<3, 3, 3>来避免bank conflict,由于这个Layout仅仅占据新的共享内存布局的4行,所以使用Swizzle<3, 3, 3>与Swizzle<2, 3, 3>的结果是完全相同的,这是因为这两组模版参数所表达的重映射关系在前4行是完全相同的。 因此,指定 即可,但基于本文中所描述的简化抽象模型来看,Swizzle<2, 3, 3>才是更加直观的答案。
对于其它的Layout,我们仍然可以基于这个简化的抽象模型来推算<B, M, S>的取值。例如,对于(8, 64):(64, 1)或者是列主序的(64, 8):(1, 64),我们别无选择,只能选Swizzle<3, 3, 3>以避免8-way bank conflict,如果是(8, 16):(16, 1),那么我们选择Swizzle<1, 3, 3>即可,如下图所示:
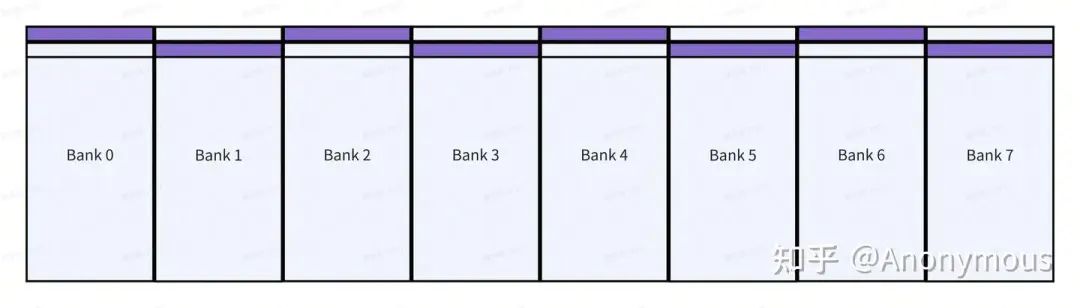
当然,Swizzle<2, 3, 3>和Swizzle<3, 3, 3>也能达到同样的效果,但Swizzle<1, 3, 3>仍是是最直观的答案。
Epilogue
本文详细的描述了在CUTLASS CuTe中,如何选取Swizzle<B, M, S>的模板参数。本文所描述的方法具有很强的扩展性,不仅可以扩展到其它的Layout中,甚至可以适配其它的mma + ldmatrix指令组合。希望本文能够帮助大家更深入的理解CuTe相关的编程组件。未来如果有充足的时间的话,本人希望进一步尝试分析SM90+的GPU架构在CUTLASS CuTe中的编程模型,并形成技术文章的持续更新。
– The End –

长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
(文:GiantPandaCV)