
一个周末就能将老破小的AI 模型性能提升12%?
这位研究人员做到了!

一场低成本的「迷你实验」,让我们看到了缩小版Gemini 2.0的无限可能。
从Gemini 2.0说起
受Gemini 2.0 Flash Thinking启发,来自CentraleSupelec的工程师Axel Darmouni萌生了一个大胆的想法!

谷歌最近发布的Gemini 2.0 Flash Thinking模型可以说是 「推理小能手」。
从基准测试数据可以看出,这个模型的性能接近Claude Sonnet 3.5。而它也与奥特曼的CloseAI 那半遮半掩的o1 系列模型不同,它不仅能给出答案,还能展示完整的推理过程。
工程师Axel Darmouni看到这个特点,灵光一闪:能不能用这个模型的推理能力来提升其他模型?
如果能将Gemini 2.0 Flash Thinking那种近乎Claude 3.5 Sonnet的推理能力「提炼」到一个小一点的模型中会怎样?
这听起来有点天方夜谭。
但Axel决定就用一个周末来验证这个想法。
于是,他开始整活了!
穷人版的实验配置
受限于算力,Axel选择了谷歌最新的视觉语言模型家族中的PaliGemma2-3B-448px 作为实验对象。

选择这个模型的主要原因有二:
-
专门为微调而生
-
只有3B参数,适合在单张H100上运行
而用来训练的数据集则选择了MathVista的testmini集。

从6.5%到18%的突破
实验初期并不顺利。基础模型在识别和计数任务上表现相当糟糕。
看这个例子:


这是一道关于交通工具数量的简单问题:「大摩托车的数量是否比橡胶切割器要少?」图中明显展示了不同类型的交通工具,包括红色摩托车、绿色踏板车和黄色自行车,但基础模型连最基本的数数和比较都做不好,准确率仅有6.5%。
为了提升性能,Axel采用了一个巧妙的方案:
-
用Gemini 2.0生成350个示例答案
-
用Claude 3.5 Sonnet标注这些答案的正确性
-
只保留正确的答案作为训练样本
看看这个测量杯的例子:


图中展示了一个带刻度的玻璃量杯,问题询问其总容量。
模型不仅能看懂刻度标记,还正确识别出单位为克(g),最终给出了准确答案:1000克。这种思维过程展示了Flash 2.0 Thinking模型具备了基本的观察和推理能力。
总体而言,在 350 个样本中,Flash 2.0 Thinking 答对了 72%。没有检查基本原理:可能是检查基本原理和结果是否一致的另一个步骤。
但受限于硬件条件,最终只能使用32个样本进行lora 微调训练。

但就是这32个样本,让模型准确率提升到了18%!

失败的有趣模式
在实验中,研究团队发现了几种典型的失败模式:
-
「循环思考」模式


这个案例涉及水箱中盐溶解的复杂计算。模型在处理这种需要多步推导的数学题时,往往会陷入无休止的思维循环。它能理解问题涉及浓度阈值和溶解过程,但就是无法得出最终结论。
这说明模型在处理多变量复杂推理时还存在短板。
-
「思路对答案错」模式


这是一道关于食物链的题目。图中清晰展示了从草到蚱蜢再到老鼠的能量传递过程。问题询问「如果夏季干草枯萎会发生什么」。模型理解了食物链的基本概念,也知道能量从底层向上传递,但在最后选择答案时却出错了。
这表明模型虽然掌握了基础知识,但在应用层面还不够稳定。
-
「胡说八道」模式


这个例子问及双层巴士的载客量。图片展示了一辆电动混合动力巴士,模型不仅没有专注于计算座位数,反而开始讨论丹尼士6型巴士等无关信息,最后给出了毫无依据的255这个数字。
这显示模型有时会完全偏离问题核心,陷入无关细节的讨论。
令人惊喜的成功案例
即便只有32个训练样本,模型还是展现出了一些令人惊喜的能力模式:
-
「完美推理」模式
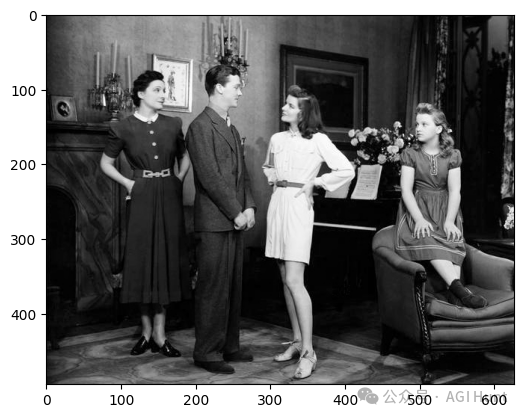

在这张二战时期的黑白照片中,模型成功识别出照片中4个人物的时代背景,并正确推断出他们都出生在1945年之前。
这个案例说明模型能很好地处理历史背景明确的场景判断。
-
「歪打正着」模式

这是一道几何题,涉及圆的直径和角度计算。虽然模型的推理过程不够严谨,但它成功从A、B、C、D四个选项中选出了正确答案。
这表明在有限选项的情况下,即便推理不完善,模型也能通过排除法得出正确结论。
-
「意外之喜」模式


这是一道关于点的分组问题。图中展示了三组紫色圆点,模型不仅正确计数,还能理解「相等的组」这个概念,最终给出正确答案。
这个案例证明模型确实掌握了一定的逻辑推理能力,能够处理训练集之外的新问题。
Axel已将完整代码开源在GitHub上:
https://github.com/axeld5/pali_reason
https://github.com/merveenoyan/smol-vision/blob/main/Fine_tune_PaliGemma.ipynb

这个实验给我们的启示是:虽然小模型在复杂推理任务上还存在诸多问题,但通过精心设计的蒸馏过程,确实能够提升它们的基础推理能力。
即便只有32个训练样本,模型也展现出了一些令人惊喜的能力,能够在完全没见过的问题类型上展现出正确的推理能力。
看完Axel Darmouni 的实验分享,Lucas Beyer 点赞表示:
这是个很酷的实验,但微调效果还有很大提升空间。
SkalskiP 则指出,其中一个关键问题可能是:
缺少或者很少出现EOS(结束)标记。
整个项目已在GitHub开源(https://github.com/axeld5/pali_reason),如果你不是我这样的GPU 穷人,而是拥有更多算力,可以进一步探索这个方向。
或许,推出首个开源版o3 的机会,就是你的了!
(文:AGI Hunt)