
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2025我们继续出发。
GPT-4o,OpenAI最新的通用基座模型(非推理模型),最早发布于2024年5月13日,目前最新版本是chatgpt-4o-latest,即集成在ChatGPT上的GPT-4o,API最新版本则是gpt-4o-2024-11-20 。GPT-4o里的“o”意为“omni”,omni在英文里是“全能”的意思,说到这里,你应该能猜到GPT-4o的优势了吧。综合能力强是GPT-4o最大的优势(之一):响应速度快,平均响应时间仅为320毫秒;成本相比前代模型大幅降低;多模态能力强,采用统一神经网络处理文本、音频和图像输入,支持端到端的实时语音和视频。
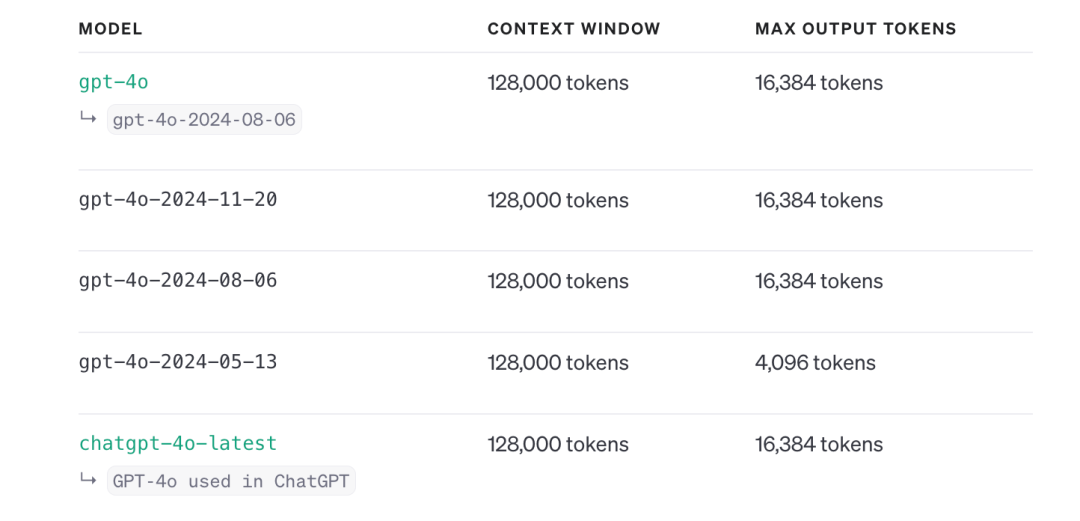
性能参数方面,GPT-4o是OpenAI的闭源模型,参数量网传为1.76 trillion,即1.76万亿,训练数据知识库截止日期为2023年10月,上下文窗口长度128K tokens,最大输出长度则为16,384 tokens。
可用性方面,GPT-4o提供免费试用,但数量很有限,约为10次每3小时;付费用户,以ChatGPT Plus为例,费用为每月20美元,GPT-4o模型的使用数量限制为80次每3小时。拥有更高额度的Team会员价格每月25美元,以及Sam Altman表示“还亏钱”的Pro会员,每月200美元。GPT-4o的API价格:输入token的价格为2.5美元每百万tokens,输出token的价格为10美元每百万tokens。
DeepSeek V3,国产AI领域冉冉升起的一颗新星,出道即巅峰,以黑马般的速度迅速走红。在各AI模型排行榜的表现也对得起这个热度,LMSYS竞技场目前位列第8名(前10名里唯一的一个国产大模型),LiveBench排行榜第4名,综合得分超过了Gemini-2.0-Flash-Exp。需要注意的是,DeepSeek V3是一个通用基座模型,它对标的就应该是GPT-4o、Claude 3.5 Sonnet以及Gemini 1.5 Pro这些模型。
性能参数方面,DeepSeek V3是量化私募幻方量化旗下的AI初创公司DeepSeek(深度求索)于12月26日推出的开源模型,参数量为6,710亿,激活参数仅为370亿。DeepSeek V3采用MoE(混合专家)架构,训练成本极低,仅为557.6万美元,远低于GPT-4的1亿美元。DeepSeek官方并未明确指出V3的知识库截止日期,但通过询问可推测其知识截止日期为2024年7月。上下文窗口长度为64K tokens,最大输出长度为8K tokens。

可用性方面,DeepSeek V3支持网页端、API调用以及本地部署三种方式。网页端(chat.deepseek.com)和国内大多数AI工具一样,注册登录后即纯免费,网页端默认的模型就是最新的DeepSeek V3,同时可以体验近期上线的联网搜索和深度思考功能。DeepSeek V3的API则主打一个“量大管饱”,毕竟“AI界的拼多多”不是吹的,每百万输入tokens 2元(缓存未命中),每百万输出tokens 8元,单位都是人民币。作为一个开源模型,本地部署是DeepSeek V3另一大优势,灵活性高,完全可控。
另外值得指出的是,当前的DeepSeek V3是一个纯文本模型,不支持多模态功能,这算是其一大弊端。但网页端的DeepSeek是支持图片和文件解析的,是通过单独的功能实现的。
DeepSeek V3 VS. GPT-4o
是骡子是马,拉出来遛遛。
下面的测试为DeepSeek网页端和ChatGPT 4o的对比。
1. 语言理解与生成能力
a. 阅读理解
阅读以下段落,并用两句话总结核心内容。
“In recent years, neural network architectures have achieved significant breakthroughs in image recognition tasks. However, scalability issues and energy consumption remain critical challenges. A recent study proposes a hybrid architecture combining transformers and convolutional layers to address these challenges.”
DeepSeek和ChatGPT完成的都不错,理解、翻译、总结出的最终结果大同小异。
DeepSeek:

ChatGPT:

b. 文体转换
将以下文字转换为适合初高中学生阅读的通俗科普风格:
“The Schrödinger equation, foundational to quantum mechanics, mathematically describes the behavior of subatomic particles in a potential field.”
DeepSeek和ChatGPT的回答惊人的相似,竟然连举的例子都几乎一模一样(大概率是训练数据的问题,所以有时候DeepSeek会声称自己是OpenAI训练的模型)。
DeepSeek:

ChatGPT:

c. 创意写作
假设你正在写一篇科幻小说,故事背景设定为地球上出现了一条神秘的时空裂缝。请继续以下开头,扩展为一段200字的情节描写,情感生动、逻辑合理。
“半年前,第一道金色裂缝在天空中出现,像是上帝不小心撕裂了夜幕。”
这个问题DeepSeek输出了一段438个字的答案,而ChatGPT则输出了一段366个字的答案。从生成的小说质量来看,个人感觉DeepSeek的输出更加具体,引出了主角,并为接下来的故事做了铺垫。ChatGPT的回答世界观则更大,算是各有优势吧。
DeepSeek:

ChatGPT:

2. 逻辑推理与数学计算
a. 真假话推断
依旧是之前测试过的“匣子问题”,正确答案应为“铅匣子”。
请注意,这道题对于推理模型来说不算难,但对于通用模型是有一定难度的,因为需要不少的推理。从昨天文章里对Claude的测试就能看出来,在没有用“Thinking Claude”提示词的情况下,Claude的回答也是错误的。
有三个匣子,分别是金匣子、银匣子和铅匣子,其中一个匣子里有宝物。每个匣子上都有一条题词:
金匣子:宝物不在此匣中。银匣子:宝物在金匣中。铅匣子:宝物不在此匣中。
已知这三句话中只有一句是真话。请问宝物在哪个匣子里?
本轮测试,DeepSeek的表现令人眼前一亮,一次性通过,推理过程也很严谨,准确无误。而ChatGPT很遗憾,被斩于马下,答案和推理过程都出现了明显的错误。
DeepSeek:

ChatGPT:

b. 数学计算
一个池塘中有莲叶,第一天覆盖面积是池塘的1%,每过一天面积都会翻倍。问:莲叶覆盖整个池塘需要多少天?
这是一个指数增长的数学计算题目,DeepSeek和ChatGPT均回答正确。相比较,DeepSeek的回答更有条理性,解答的步骤非常详细;而ChatGPT直接给出了指数求和公式,没有说明为什么。但ChatGPT在最后进行了二次验证,这是它回答的一大亮点。
DeepSeek:

ChatGPT:

c. 数列推理
观察下列数字序列,找出其规律并写出接下来的两个数字:
2,4,3,6,5,10,9,18,17,…
这是一个奇偶交替数列,正确答案34,33。DeepSeek一遍过,输出非常长,甚至用了两种方法来解答(找到了两种可解释的规律)。很不幸,ChatGPT再次出现了严重错误,我甚至怀疑我的ChatGPT被降智了(其实并没有)!
DeepSeek:

ChatGPT:

3. LeetCode – Hard
Robot Collisions
为了避免有些Hard题目是在训练数据里的,挑了一道序号比较大的LeetCode Hard题目来做测试。题目本身不算特别难,考察栈的。
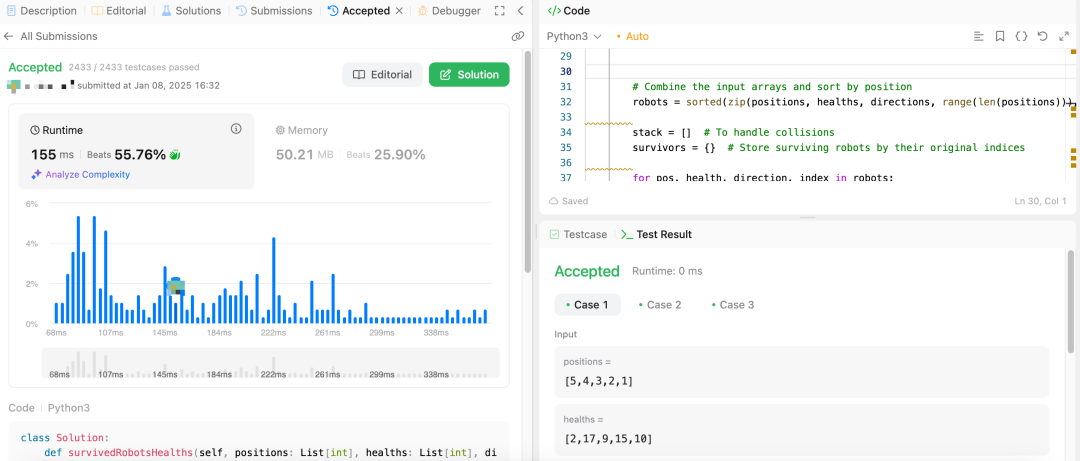
本轮测试ChatGPT胜出。美中不足的是,虽然我是用中文提问的,ChatGPT自动切换成了英文回答。DeepSeek的回答格式、思路都很好,代码块的展示也很漂亮,但遗憾的是,它在最后用了嵌套for循环,导致遍历效率不高,最终没有通过测试,报错“Time Limit Exceeded”。
DeepSeek:
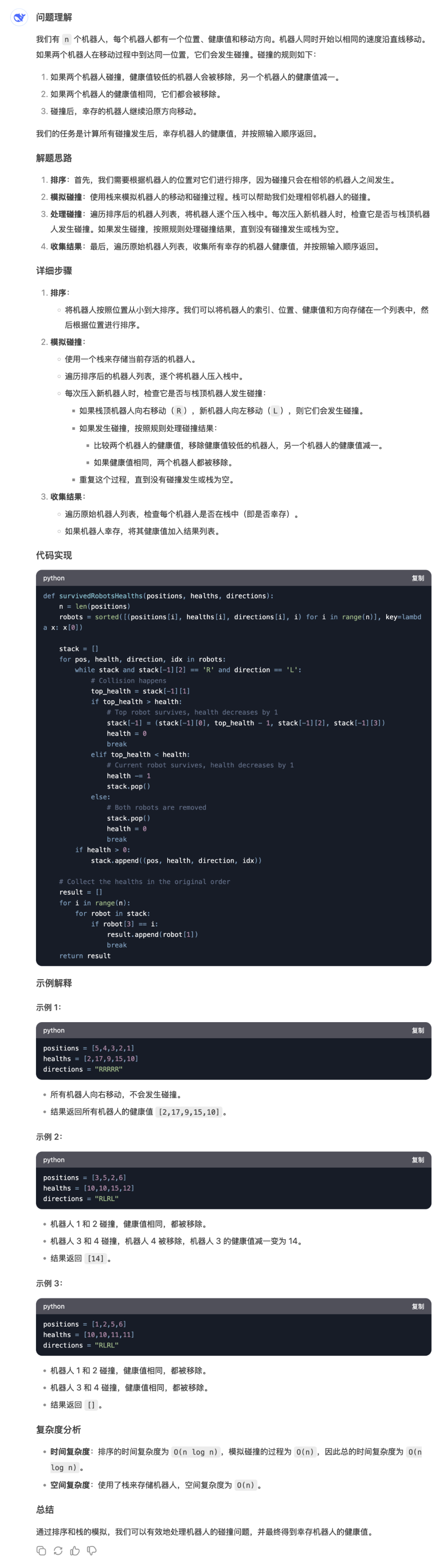
LeetCode提交结果:
ChatGPT:

LeetCode提交结果:
结语
测试完DeepSeek V3和GPT-4o,我不想再开ChatGPT会员了!
(文:AI信息Gap)