
SmartFlowAI


点击上方蓝字关注我们

作者:企鹅火烈鸟🦩
全文约 2400 字,预计阅读时间 6 分钟
引子
Deepseek V3的报告在网上放出之后,在知乎也看了很多训练分析和推理的文章。前段时间也转发了一位大佬的pp分析和通信文章,正好赶上前两天没空。29号凌晨才把文章看完,顺着这股劲儿写一些Deepseek V3里fp8训练。若有错误请大家指正,也希望和大佬们一起讨论。
FP8量化是一种新兴的低精度数值表示方法,通过将FP16或FP32降低到8位浮点数,可以显著减少模型的内存占用(相比FP32降低75%)和计算开销,同时提升推理速度和能效比。它提供E4M3和E5M2两种格式以平衡精度和范围,在保证模型性能的前提下,尤其适合大规模AI模型的训练和部署加速。不过要充分发挥FP8的优势,需要特定硬件支持,如NVIDIA Hopper架构GPU。
整体一览
从Deepseek V3的技术报告里写到,它在Embedding、Attention、gating(MoE路由)、Norm上是用的原始精度(BF16 or FP32,某些gating操作会上FP32吧)。也就是说会做FP8的位置基本就在MoE上的MLP和Attention前后的MLP。
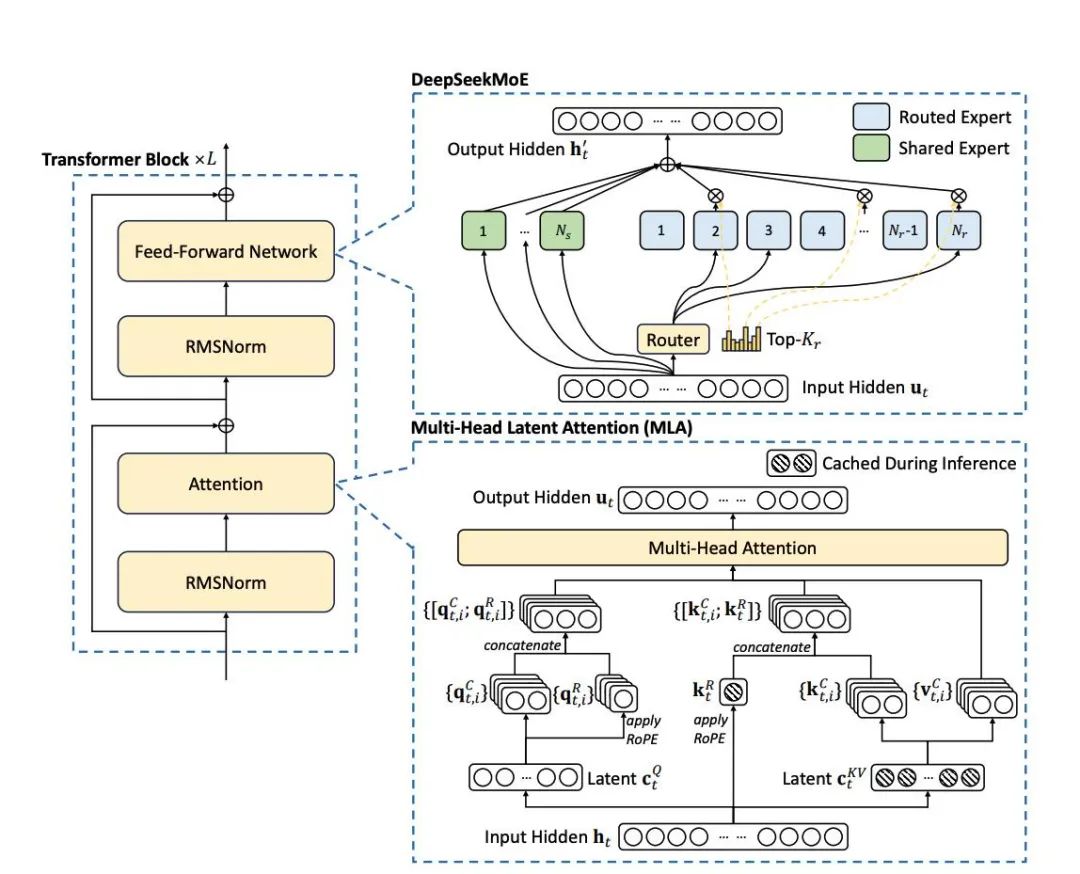
技术报告里讲到,会对FP8训练进行量化。这也是常规操作了,NV的一次OpenDay也讲了关于FP8训练时的量化。
NVIDIA英伟达 – FP8 训练的挑战及最佳实践:https://www.bilibili.com/video/BV1tM4m117eL/
主要的原因是,虽然fp8对scale不敏感。但是因为fp32/bf16 -> fp8的数据可能会落出fp8的可表示范围外,造成一定的溢出。所以需要给fp8量化带上一个scale。
量化方式
在做大模型推理时,常用的量化方式有per tensor量化、per token(逐行)量化、groupwise量化、tile wise量化这四种量化方式分别对应的是
-
per tensor:对一个tensor(二维)量化成低比特,并用一个scale表示。 -
per token:对一行/一列元素量化成低比特,并每一列都用一个scale表示。 -
group wise量化:对特定个元素为一组,每组元素用一个scale进行表示。 -
tile wise量化:对特定的一块区域进行量化,并对这块特定的位置取一个scale(比如128×128)
当然,可以理解。量化的成员越进行细分,它解量化恢复精度时的量化误差也会越接近。group wise对应的量化精度也是最高的。(想起了和前mentor探讨不同量化方式的区别时,他和我讲。你选择如何量化完全是一种自由,如果你想。可以用各种诡异的方式进行量化,完全取决于硬件特性是否能在你的量化算法上拿到收益。)
话说回来,对应tile wise的量化方法。最近Sage Attention V2的对attention的量化方式,就使用了分小块进行量化的方式。
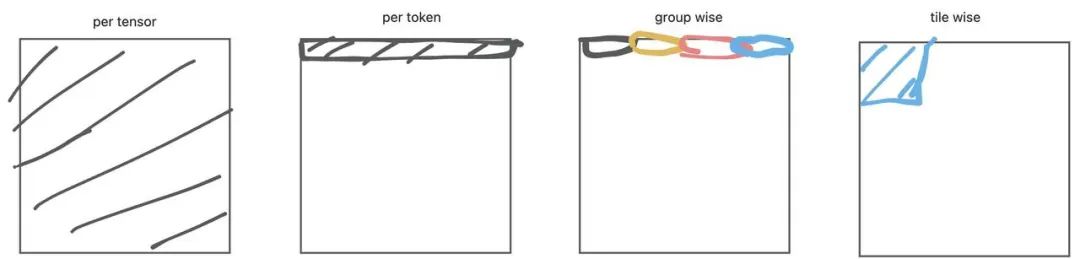
讲了推理用到的量化方式之后,对应Deepseek V3 FP8训练。作者在文章中提到使用了groupwise和 tilewise的方法进行量化。
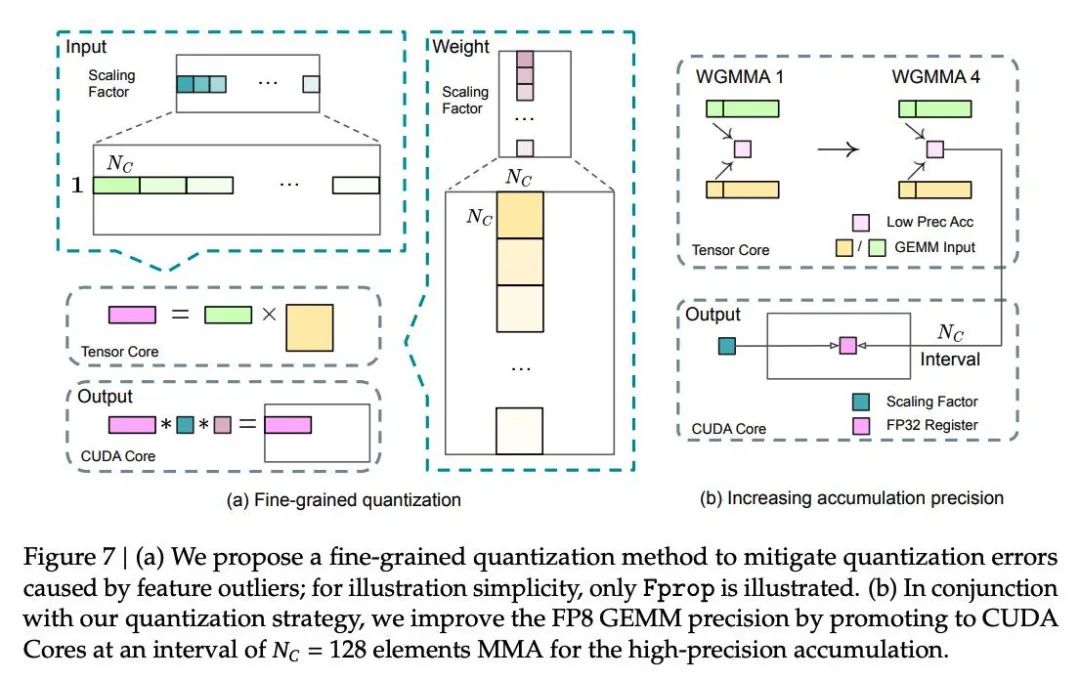
tr对输入的input按groupwise进行量化,权重按tilewise进行量化。分别拿到了输入和权重的scale,在tensorcore上对一条(1×128) 和 一块(128×128)进行fp8矩阵乘法之后。拿回到cudacore上并同时乘上scale进行解量化。之后的操作就是loop进行矩阵乘法。
在这里量化的部分或许会带来一些性能问题,这个也在后续对硬件的改进建议里Deepseek提到了。那就是在每一个块进行wgmma计算时,都会有scale的加载问题。也就是说在loop的过程中,会不断的加载input和weight的scale来进行解量化流程。当计算量变大时,不断的解量化(因为在tensorcore->cudacore上的搬移)带来的开销或许会抹平FP8拿到的量化收益。(NV也说在下一代tensorcore上会有更细粒度的量化方式,期待一下吧)
当然,我们也并不需要每次都是1×128 128×128 -> 1×128 这样之后再解量化。像下图里的方式也是可行的,这样也更方便利用tensorcore进行wgmma。
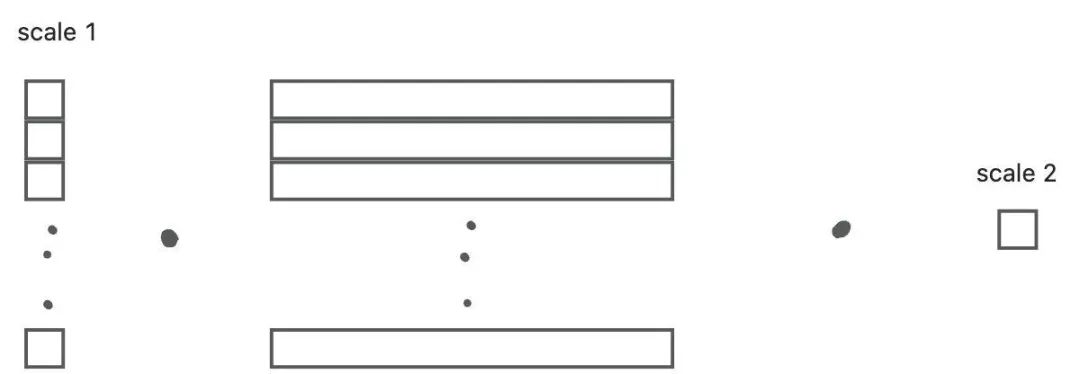
使用CUDA Core进行累加
WGMMA (Warpgroup MMA) 是 NVIDIA Hopper 架构中引入的一种新的指令集或技术,主要用于支持异步计算以及直接读取共享内存(SMEM)中的数据进行计算,从而提升 GPU 在特定任务中的性能表现
tr中发现NVIDIA H800 GPU上FP8 GEMM的累加精度仅能保持约14位,这明显低于FP32累加精度。并且默认在tensorcore上进行fp8累加是默认选项。deepseek的做法是,做一段wgmma之后,在CUDA Core中进行累加。文章中说开的wgmma数量为4之后进行累加
盲猜切分方法为:
// 使用.m64n128k32的情况
WGMMA_1: A[0:63][0:31] × B[0:31][0:127] // K维度第1段
WGMMA_2: A[0:63][32:63] × B[32:63][0:127] // K维度第2段
WGMMA_3: A[0:63][64:95] × B[64:95][0:127] // K维度第3段
WGMMA_4: A[0:63][96:127] × B[96:127][0:127] // K维度第4段
然后把上面这四段统一运进CUDA Core上进行累加,累加之后的结果再采用刚才所画的形式进行解码。
在H800架构上,通常有两个WGMMA同时存在。也就是说在一个group上进行矩阵乘法,另一个group上进行累加。这样可以保持张量核心的高利用率。
整体量化流程
看完了量化的方式之后,我们来看一看FP8的整体流程。
-
前向:在输入采用BF16,主权重采用FP32,量化到FP8。前向在累加之后是FP32的输出,cast到BF16. -
反向:wgrad累加之后天然为FP32的dtype,优化器状态采用BF16。weight以FP32进行更新。对于dgrad来说,FP8反向之后cast成BF16继续向前传播。
FP8 Dtype 选取
FP8支持两种Dtype,一种是e4m3。这种方式具有更精确的数值,但是较小的动态范围。一种方式是e5m2,这种方式有较大的范围。但是数值不如e4m3精确。在Deepseek的FP8训练里,它保持了较精确的数值。全程使用了e4m3。
attention out proj特殊精度
作者提到在attention的输出时,它的反向会对attention有较高的精度影响。作者把它提升到e5m6。(有一说一并不是很明白做一个奇怪的中间精度的意义,out proj公认的不好处理。转回bf16算不就好了嘛。。。前向的时候attention也要bf16,还不用量化。反向的时候就cast一下就好了)
量化选择
在per tensor的框架中采用了延迟量化,这种方法会保留先前若干次迭代中的最大绝对值历史数据,以推断当前值。也就是一种类似离线量化的手段,这里deepseek使用的是在线量化。也就是每次量化前统计量化范围里的max值并计算scale。
特殊tile wise量化为反向带来的问题
虽然我们的基于tile的细粒度量化有效地减轻了特征异常值带来的误差,但它在激活量化时需要不同的分组方式:前向传播时是1×128,反向传播时是128×1。激活梯度也需要类似的处理。一个直观的策略是像量化模型权重那样,对每个128×128的元素进行块级量化。这样,反向传播时只需要进行转置操作。
原因是在处理weight grad的时候:
那input就变成了之前transpose之后的样子,但是对于输入来说。我们统计scale还是需要按行进行统计的,所以反向算weight的时候需要统计一次不同的scale。增加了时间。
作者考虑到这个问题,考虑是否可以通过使用相同的scale避免这个问题。但是通过对比实验发现input对块级量化极为敏感,他们推测不同token之间的激活梯度非常不平衡,导致了与token相关的异常值。这些异常值无法通过块级量化方法得到有效处理。
Deepseek对硬件上的期待
有一说一,感觉这几个NV估计都做不到(不知道fp8训练这条路跑通之后,nv会不会做一些量化友好的特性上来。
Tensor Core中更高的FP8 GEMM累加精度:
在当前NVIDIA Hopper架构的Tensor Core实现中,FP8 GEMM(通用矩阵乘法)采用定点累加,在相加前基于最大指数对尾数乘积进行右移对齐。我们的实验表明,它在符号填充右移后只使用每个尾数乘积的最高14位,并截断超出此范围的位。然而,例如,要从32个FP8×FP8乘法的累加中获得精确的FP32结果,至少需要34位精度。因此,我们建议未来的芯片设计增加Tensor Core的累加精度以支持全精度累加,或根据训练和推理算法的精度要求选择适当的累加位宽。这种方法确保误差在可接受范围内,同时保持计算效率。
对Tile和Block量化的支持:
当前GPU仅支持per tensor量化,缺乏tile和block量化等细粒度量化的原生支持。在当前实现中,当达到NC(128)间隔时,部分结果将从Tensor Core复制到CUDA core,乘以缩放因子,并加到CUDA core上的FP32寄存器中。虽然结合我们的精确FP32累加策略显著减轻了反量化开销,但Tensor Core和CUDA core之间频繁的数据移动仍然限制了计算效率。因此建议未来的芯片通过使Tensor Core能够接收缩放因子并实现带分组缩放的MMA来支持细粒度量化。这样,整个部分和累加和反量化可以直接在Tensor Core内完成,直到生成最终结果,避免频繁的数据移动。
对在线量化的支持:
研究表明在线量化很有效,但当前实现难以有效支持它。在现有流程中,我们需要从HBM(高带宽内存)读取128个BF16激活值(前一次计算的输出)进行量化,然后将量化后的FP8值写回HBM,只是为了再次读取用于MMA。为解决这种低效问题,我们建议未来芯片将FP8转换和TMA(张量内存加速器)访问集成为单个融合操作,这样量化可以在激活从全局内存传输到共享内存期间完成,避免频繁的内存读写。我们还建议支持warp级别的转换指令以加速,这进一步促进了层归一化和FP8转换的更好融合。另外,可以采用近内存计算方法,将计算逻辑放置在HBM附近。在这种情况下,BF16元素可以在从HBM读入GPU时直接转换为FP8,将片外内存访问减少约50%。
对转置GEMM操作的支持:
当前架构使矩阵转置与GEMM操作的融合变得繁琐。在我们的工作流程中,前向传播期间的激活被量化为1×128 FP8 tile并存储。在反向传播期间,需要读出矩阵,反量化,转置,重新量化为128×1 tile,并存储在HBM中。为减少内存操作,我们建议未来芯片能够在MMA操作前直接从共享内存中转置读取矩阵,适用于训练和推理所需的那些精度。
总结
写到结束天也快亮了,deepseek也是所知的第一家能训出fp8 loss的厂,还记得前两年讨论int8和fp8优劣的时候(那会还没有H100,没有fp8 tensorcore)记得看到知乎有个老哥留言,如果fp8训练成功走通的话。无缝衔接fp8推理一定会很顺滑。那会还在想fp8训练遥遥无期。没想到一眨眼就有人能做到了。deepseek对训练fp8量化的观察和解决方法都很有启发,希望能看到fp8训练能继续大放异彩(这样我们搞量化的就能转业去fp8了吧。
(文:GiantPandaCV)