
FP8


ICLR 2025 英伟达提出FP8训练新范式:减少40%显存占用,训练加速1.43倍

近期伯克利等机构提出COAT方法,通过动态范围扩展和混合粒度FP8精度流技术,在保持模型精度的同时显著减少FP8量化误差及激活值占用,实现了端到端内存占用减少1.54倍、训练速度提高1.43倍。
FP8训练新范式:减少40%显存占用,训练速度提高1.4倍

近期研究提出COAT方法利用FP8量化技术,通过动态范围扩展和混合粒度精度流优化大型模型训练中的内存占用和加速速度,保持模型精度的同时显著减少显存使用并提升训练效率。
DeepSeek开源周Day 3:DeepGEMM——300行代码性能飙升2.7倍,比英伟达更懂如何优化英伟达?

DeepSeek开源的DeepGEMM库在Hopper GPU上实现FP8 GEMM,最高可达1350+ FP8 TFLOPS。它仅约300行代码,设计简洁,性能表现与专家调优的复杂库相当甚至更好,在各种矩阵形状和模型类型上均保持优势。

DeepSeek开源第三弹!极致榨干GPU,FP8训推秘籍公开
DeepGEMM是DeepSeek开源的一款支持FP8 GEMM的库,为V3/R1训练和推理提供动力,在Hopper GPU上性能高达1350+ FP8 TFLOPS。该库采用JIT即时编译技术,核心逻辑约为300行,仅支持英伟达Hopper Tensor Core架构,设计简单高效,且在某些形状上的表现优异。
刚刚,高效部署DeepSeek R1的秘密被DeepSeek公开了~

DeepSeek的开源周Day2发布了DeepEP库,这是一个为MoE模型训练和推理定制的通信库,支持高吞吐量、低延迟的All-to-All GPU内核,并提供针对非对称域带宽转发优化的内核。
榨干每一块 GPU!DeepSeek 开源第二天,送上降本增效神器
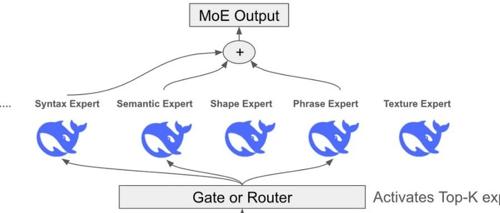
DeepSeek 开源周第二天,带来了 DeepEP 通信库,旨在优化混合专家系统和专家并行模型的高效通信。其亮点包括高效的全员协作通道、专为训练和推理预填充设计的核心以及灵活调控GPU资源的能力,显著提升MoE模型的性能和效率。
DeepSeek满血微调秘籍开源了

DeepSeek-R1开源满血版工具链,Colossal-AI团队将6710亿参数的大模型驯化为开发者私有化模型,降低硬件需求和成本,标志着AI竞争正式进入’场景深水区’。