
性能提升


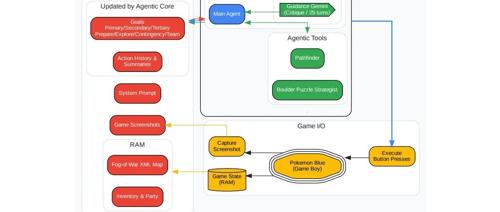


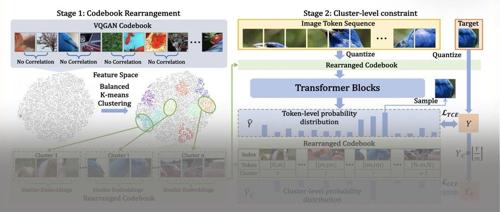
字节Seed新作:模型合并如何改变大模型预训练范式

字节跳动提出预训练模型平均(PMA)技术,在不增加计算成本的情况下显著提升大模型性能。通过合并稳定期检查点,PMA能预测衰减阶段表现,节省资源并加速训练进程。
推理时间减少70%!前馈3DGS「压缩神器」来了,浙大Monash联合出品

ZIP Lab和Monash团队提出ZPressor模块,通过信息瓶颈原理解决了前馈3D高斯泼溅模型的信息过载问题。该方法显著提升了实时渲染能力、推理时间和显存占用,并在多种基准数据集上提高了模型的鲁棒性和性能表现。

