何恺明CVPR最新讲座PPT上线:走向端到端生成建模

何恺明在CVPR会议上分享了关于识别模型演进与生成模型未来方向的见解,他提出了一种名为MeanFlow的新方法用于实现单步生成任务,并介绍了多种研究方向和问题。
何恺明在CVPR会议上分享了关于识别模型演进与生成模型未来方向的见解,他提出了一种名为MeanFlow的新方法用于实现单步生成任务,并介绍了多种研究方向和问题。

本文介绍了一种名为 DanceGRPO 的强化学习框架,在视觉生成任务中实现了统一优化。该方法通过 GRPO 策略在 Diffusion 和 Rectified Flow 模型上进行了测试,并覆盖了文本到图像、视频等多种任务,展示了其在不同基础模型上的有效性及对多种奖励模型的适应性。
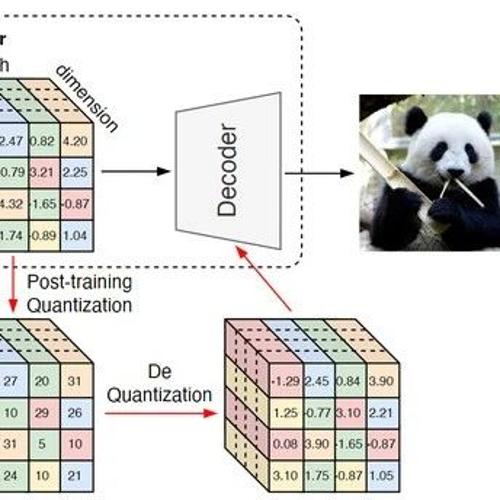
模简单的优点,又可以保持连续 token 的强表示能力。
>>
加入极市CV技术交流群,走在计算机视

本文由 NUS ShowLab 指导完成,首次系统性研究长上下文视频生成。提出帧自回归模型FAR,有效解决长视频训练计算挑战,显著提升长时序一致性。

之前思考更长时间而训练。
这些推理模型首次实现了自主调用并整合 ChatGPT 内的全量工具:包括网

解统一架构代表作 Janus 以及后续扩大版本 Janus-Pro。
>>加入极市CV技术交流群,走