
将Phi-4-mini扩展到了200064 tokens。
采用 Microsoft 的新型 SambaY 解码器-混合-解码器架构构建,支持 64K token上下文长度,提供可靠的逻辑密集型性能部署,并且在长上下文任务中的运行速度比其前代产品快 10×。
Phi-4-mini-flash-reasoning 架构
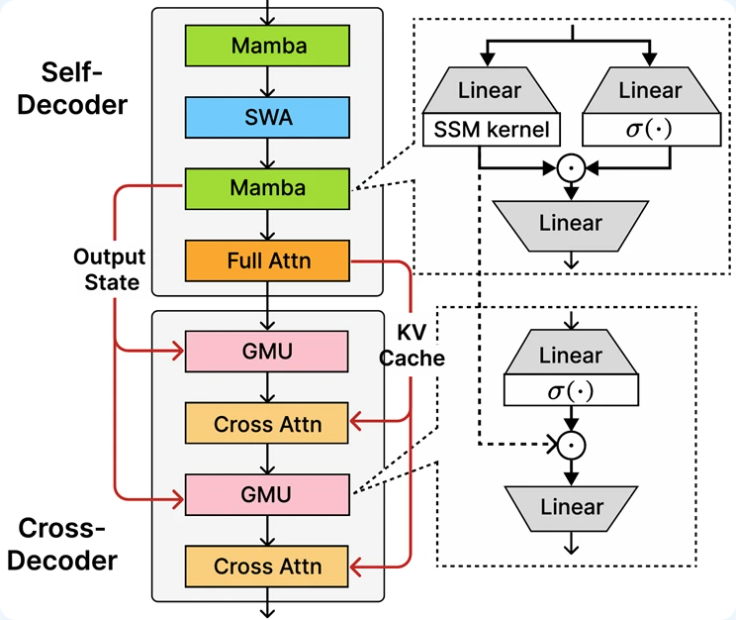
Phi-4-mini-flash-reasoning 的核心:新引入的解码器-混合-解码器架构 SambaY。
-
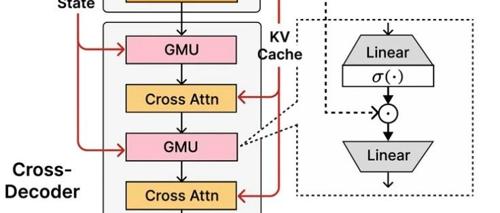
SambaY核心创新是门控内存单元 (GMU),是一种简单而有效的机制,用于在层之间共享表示。
-
该架构包括一个自解码器,它结合了 Mamba(一种状态空间模型)和滑动窗口注意力 (SWA),以及一个完整的注意力单层。
-
还涉及一个交叉解码器,该解码器将昂贵的交叉注意力层与新的高效 GMU 交错。这种带有 GMU 模块的新架构大大提高了解码效率,提高了长上下文检索性能,并使该架构能够在各种任务中提供卓越的性能。
SambaY 架构的主要优点包括:
-
提高解码效率 -
保持线性的预归档时间复杂度 -
提高了可扩展性并增强了长上下文性能 -
吞吐量提高多达 10 倍
-
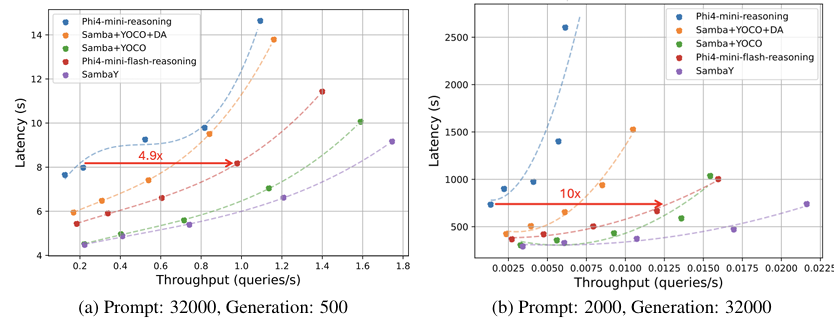
这张图展示了SambaY架构在长上下文情况下,有非常强的低延时性能。长输入、段短输出;短输出入、长输都表现出了优秀的低延迟性能。
-
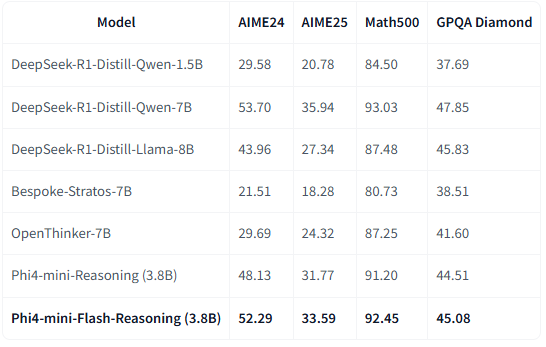
Phi-4-mini-Flash-Reasoning 3B模型快要逼近 DeepSeek-R1-Distill-Qwen-7B了
https://huggingface.co/microsoft/Phi-4-mini-flash-reasoning
https://arxiv.org/pdf/2507.06607
(文:PaperAgent)