



论文链接:
https://arxiv.org/pdf/2507.08371
标题:
The Curious Case of Factuality Finetuning: Models’ Internal Beliefs Can Improve Factuality
一句话理解:
本文研究如何通过后训练(post-training)减少大语言模型在长文本生成中的“幻觉”(hallucination)问题,即模型生成虚假或不准确信息的现象。结论是让模型更诚实的关键不是教它更多“真实”,而是让它更相信自己的“已知”。
核心发现:
模型“相信”的内容比“真实”更重要。
反直觉的结论:用模型自己生成的、它“相信”是真实的内容来微调,反而比用真实(gold)数据微调更能减少幻觉。
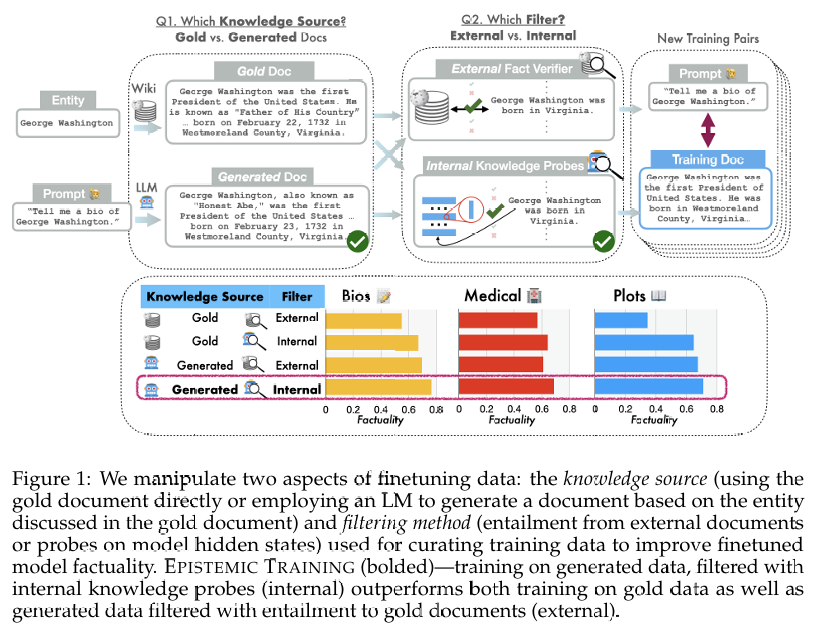
研究方法与实验设计
作者设计了一个名为 EPISTEMIC TRAINING 的训练方法,包含两个关键维度:
知识来源:
人类编写的“金标准”文档(gold)
模型自己生成的内容(generated)
过滤方式:
外部验证:用外部文档判断真假(external)
内部验证:用模型自身的置信信号(internal)
实验结果(跨三个领域:人物传记、剧情摘要、医学术语)
Generated + Internal(EPISTEMIC TRAINING): 幻觉最少,效果最好
Generated + External: 效果次好
Gold + Internal: 效果一般
Gold + External: 效果最差
无微调: 幻觉最多
关键洞察
“熟悉度”比“真实性”更重要:模型对不熟悉的真实内容反而更容易“编故事”,而对熟悉的内容即使不完全真实也更不容易出错。
内部知识探针有效:用模型内部的“置信信号”来过滤训练数据,比用外部文档验证更有效。
跨领域泛化能力强:在一个领域训练出的“事实性”能力可以迁移到其他领域,减少对金标准数据的依赖。
局限与未来方向
如果模型对某个领域一无所知,内部探针也无法帮助。
可能加剧对某些群体(如少数族裔)的“沉默”或偏见。
如何在不牺牲信息量的前提下提高事实性,仍是挑战。
(文:机器学习算法与自然语言处理)