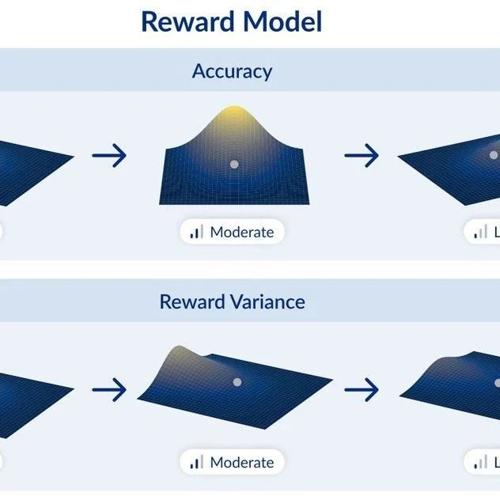
奖励模型

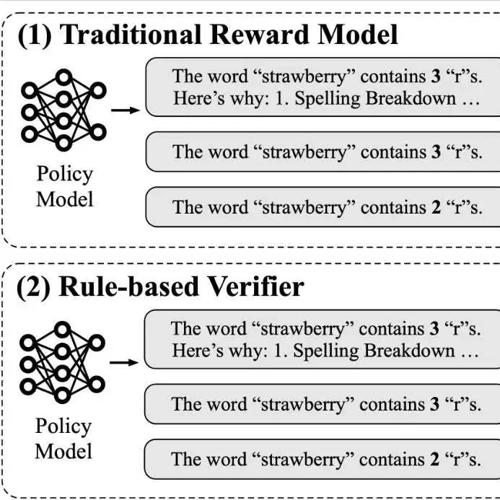



DanceGRPO:首个统一视觉生成的强化学习框架

本文介绍了一种名为 DanceGRPO 的强化学习框架,在视觉生成任务中实现了统一优化。该方法通过 GRPO 策略在 Diffusion 和 Rectified Flow 模型上进行了测试,并覆盖了文本到图像、视频等多种任务,展示了其在不同基础模型上的有效性及对多种奖励模型的适应性。
新SoTA方法RM-R1:让reward model对评分说出原因!超越GPT4o

MLNLP社区致力于促进国内外机器学习与自然语言处理的交流合作。近期发表论文提出推理奖励模型ReasRM,通过两阶段训练让小模型学会写评语,并在综合、数学题等测试集中优于GPT-4。该模型支持任务分类和动态奖励机制,已在多个领域展示优势。
DeepSeek前脚发新论文,奥特曼立马跟上:GPT-5就在几个月后啊

DeepSeek发布新论文提出SPCT方法解决通用RM推理时扩展问题,并计划先发布o3和o4-mini,GPT-5将在几个月后推出。