


模型评分为什么需要“会思考”?
过去,模型的“评分”就像老师只给分数不写评语——比如你问“哪个回答更好”,它只会输出一个数字或简单结论,但说不出理由。
这种“黑箱打分”有两个问题:
-
不透明:用户不知道评分依据,难以信任; -
不灵活:遇到复杂问题(如伦理判断、多步骤推理)容易翻车。 
论文:RM-R1: Reward Modeling as Reasoning
链接:https://arxiv.org/pdf/2505.02387
而人类评分时会先列标准(比如“逻辑性”“安全性”),再逐条分析。论文团队从中获得灵感:像人类一样先思考再打分。

创新:让奖励模型学会“写评语”
论文提出ReasRM(推理奖励模型),核心是两阶段训练:
-
用高级模型(如Claude、GPT-4)生成的“标准答案评语”教小模型写分析; -
通过强化学习,让模型根据实际表现优化评分逻辑。
举个栗子:
-
传统模型:“选B,因为B得分更高。” -
ReasRM:
<评分标准>
1. 准确性(40%):回答是否符合医学事实;
2. 全面性(30%):是否覆盖关键症状;
...
<分析>
A回答提到“视力丧失”,但这是罕见症状,可能误导用户;
B回答解释了“疼痛原因”,更准确...
<最终结论>[[B]]
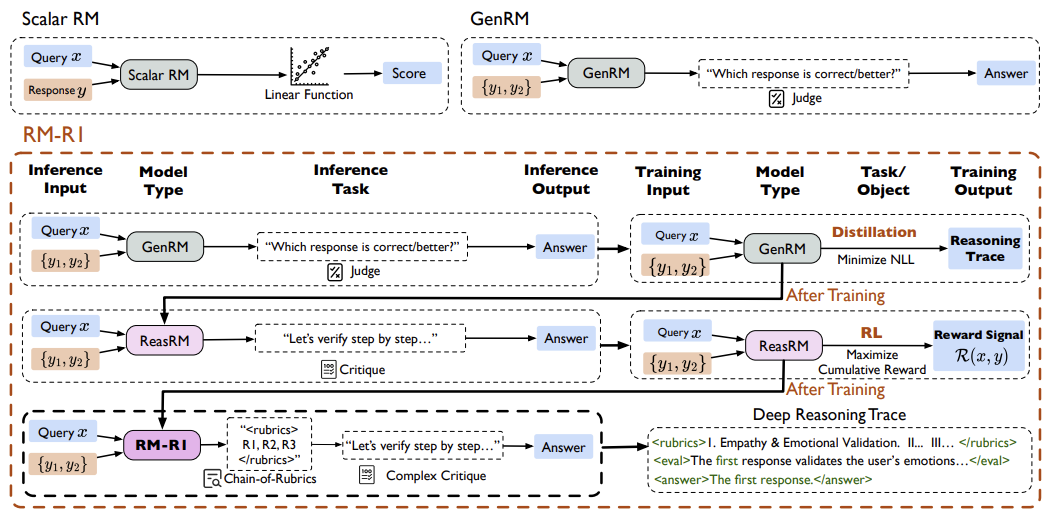
从“打分”到“推理”的跨越
任务分类
模型会先判断问题是闲聊型(如客服对话)还是推理型(如数学题),再针对性生成评分标准。
动态奖励
-
对数学题,模型会自己先解题,再对比答案; -
对伦理问题,模型会生成“安全准则”,按规则打分。
公式简化版:
奖励函数 = 判断正确 + 保持输出稳定性
判
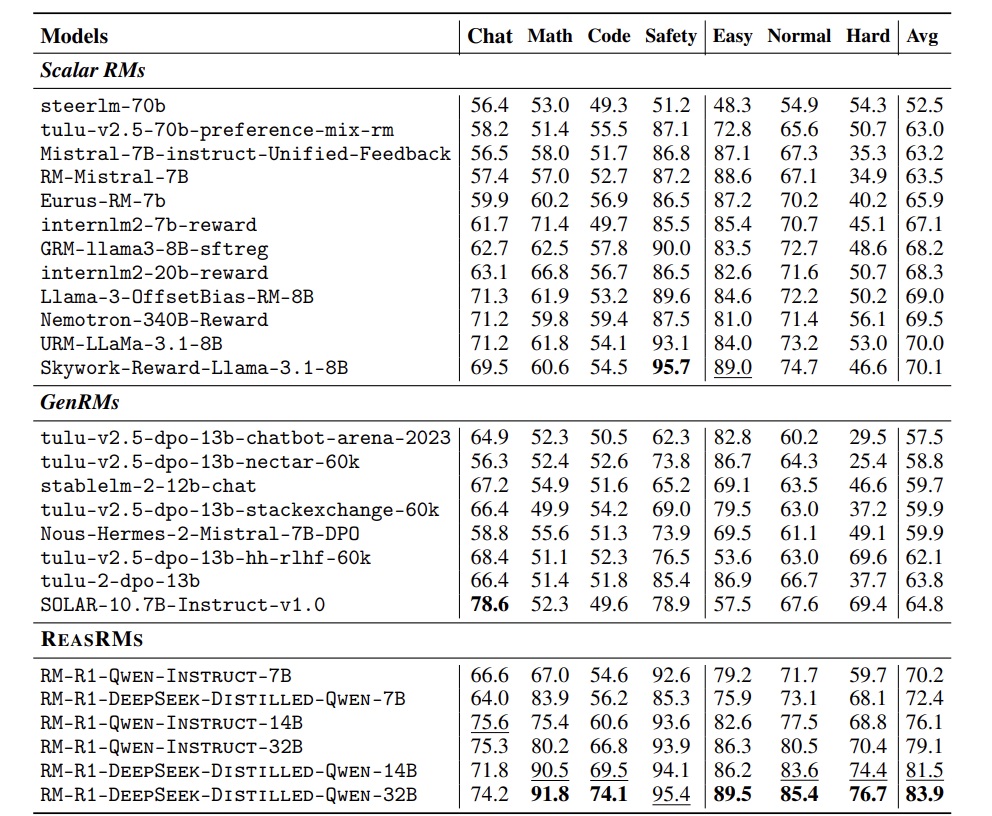
实验:碾压GPT-4,小模型逆袭大模型
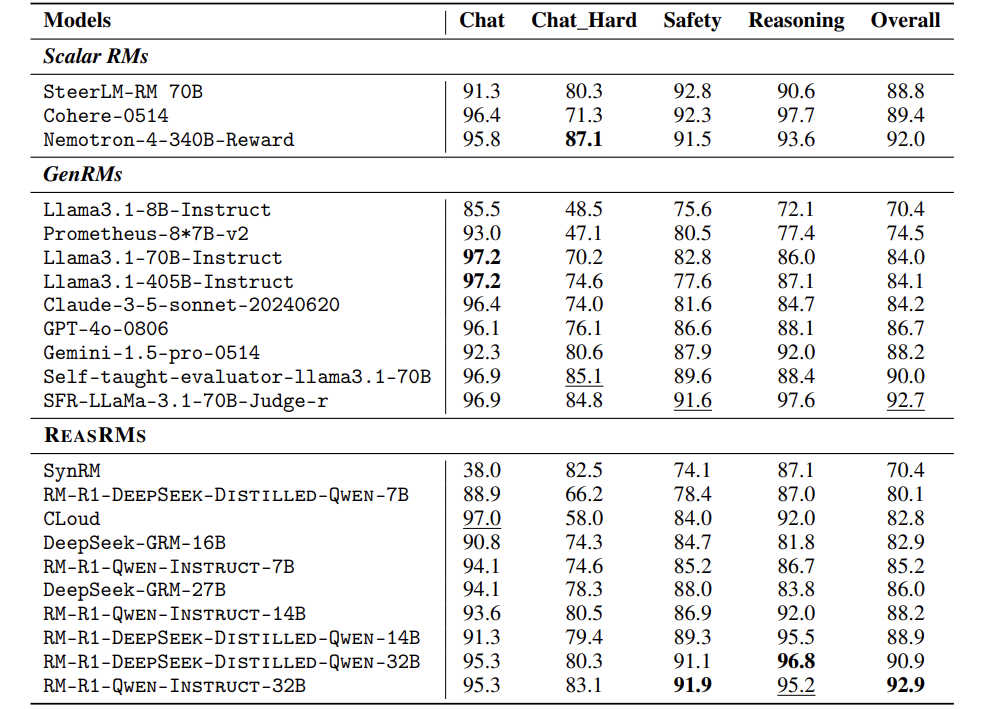
论文在三大测试集上验证效果:
-
RewardBench:综合评分超越GPT-4o 13.8%; -
RM-Bench:数学题准确率91.8%,代码题74.1%; -
RMB:接近GPT-4,但模型小得多。
反常识发现:
-
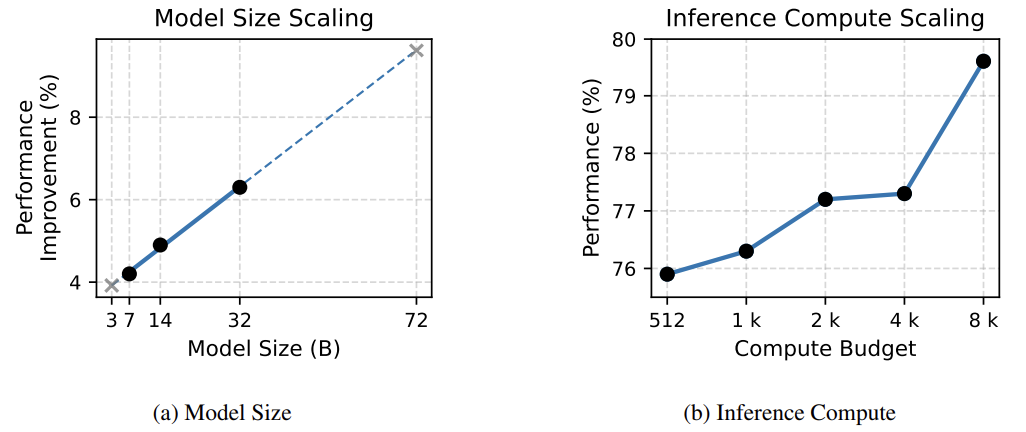
14B小模型吊打70B大模型; -
推理链越长,效果越好。
团队已开源6个模型,欢迎大家使用 🎉
(文:机器学习算法与自然语言处理)