
大模型刷数学题竟有害?CMU评估20+模型指出训练陷阱

CMU研究发现,仅用监督微调训练的大模型在其他通用任务上的表现有限甚至退步。强化学习微调的模型则能更好地将数学能力迁移到推理和非推理任务上,预示着强化学习可能是实现可迁移推理的关键方法。
CMU研究发现,仅用监督微调训练的大模型在其他通用任务上的表现有限甚至退步。强化学习微调的模型则能更好地将数学能力迁移到推理和非推理任务上,预示着强化学习可能是实现可迁移推理的关键方法。

MLNLP社区推出FineReason基准,评估大模型的审慎推理能力。通过逻辑谜题训练,提升模型在数学和通用推理任务上的表现,并揭示其反思与纠错能力的瓶颈。

Osmosis-Structure-0.6B 是一款小型语言模型,专注于结构化输出生成。通过强化学习和大量结构化数据训练,在数学推理任务中表现出色,并在多个领域如智能客服、数据分析和教育辅导中有广泛应用。

大模型在数学推理和解答题上表现参差不齐,多数模型在图像识别方面仍存在问题。总体来看,大模型在复杂推理、严谨论证及多步骤计算能力上有较大提升空间。

西湖大学研究团队提出SLOT方法,在推理时通过优化delta参数向量调整输出词汇概率分布,显著提升语言模型在复杂指令上的表现。

企业AI部署专题:OpenStation团队介绍DeepSeek-R1-0528新版本模型开源。它提供一站式的大模型部署管理平台,简化企业级AI部署流程。

中兴通讯星云大模型在推理榜单上荣获总分第一,并在数学、科学及代码生成等细分领域表现突出。它还通过了国家级权威安全认证,成为业内少数拥有双安全认证的大模型产品。
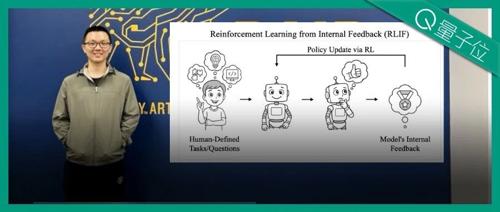
UC Berkeley团队提出的新方法Intuitor通过优化模型自身的置信程度来提升大模型的复杂推理能力,无需外部奖励信号或标准答案。与传统强化学习相比,Intuitor能有效减少无效响应并提高模型在数学和代码生成任务中的表现。

