
R1-Zero的无监督版本来了!SFT不再是必须,EMPO重新定义大模型推理微调

本文提出Entropy Minimized Policy Optimization (EMPO)方法,旨在实现完全无监督条件下大模型推理能力的提升。该方法不需要监督微调或人工标注的答案,仅通过强化学习训练从基模型中获得策略,并利用语义相似性聚类生成的多个回答作为奖励信号,从而在数学及其他通用推理任务上取得显著性能提升。
本文提出Entropy Minimized Policy Optimization (EMPO)方法,旨在实现完全无监督条件下大模型推理能力的提升。该方法不需要监督微调或人工标注的答案,仅通过强化学习训练从基模型中获得策略,并利用语义相似性聚类生成的多个回答作为奖励信号,从而在数学及其他通用推理任务上取得显著性能提升。

阿里-高德团队提出组策略梯度优化GPG方法,仅需优化原始目标,解决已有方法偏差,提高训练效率。在实验中,GPG性能全面超越现有方法,有望成为下一代基础模型训练的关键方法。

通过SRPO方案,快手Kwaipilot团队在处理数学与代码混合数据时实现了效率和效果的双赢。SRPO结合了两阶段训练范式和历史重采样技术,仅用10%的训练步数,在AIME24和LiveCodeBench基准测试中超越了现有模型的表现。

MegaMath 是一个包含3710亿tokens的开源数学推理预训练数据集,覆盖网页、代码和高质量合成数据三大领域。它首次在规模上超越了DeepSeek-Math Corpus(120B),代表从‘只靠网页’到‘面向推理’的重大跨越。

阿里通义千问和DeepSeek分别开源了Qwen2.5-VL-32B-Instruct和DeepSeek-V3-0324两个模型,前者主要提升了数学推理、细粒度图像理解与推理能力,并且调整输出样式以提供更符合人类偏好的答案;后者则强调编程能力和前端开发功能。
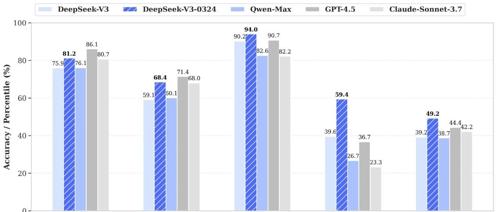
DeepSeek-V3-0324 在数学推理和前端开发方面表现优于 Claude 3.5 和 Claude 3.7 Sonnet,这是 DeepSeek 最佳非推理模型。



