

当前,大语言模型(LLMs)已在数学推理、代码等任务中展现出强大的能力。然而,现有提升推理性能的主流范式,往往依赖监督微调(SFT)与强化学习(RL)的结合,依赖于人工标注的推理路径、标准答案或额外的奖励模型。这不仅成本高昂,也限制了方法的通用性与可扩展性。
针对这一痛点,本文(2025 年 4 月 8 日首次放出)提出 Entropy Minimized Policy Optimization(EMPO)方法,开创性地探索完全无监督条件下实现 R1-Zero-like 范式的大模型推理能力提升策略。

论文标题:
Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization
论文地址:
https://arxiv.org/pdf/2504.05812
Github 地址:
https://github.com/QingyangZhang/EMPO
完全无监督:EMPO 直接从 base 模型进行强化学习训练,不需要 SFT 启动和指令微调, 不依赖人工标注的问题答案;
任务通用性:每轮迭代中,从当前策略模型中采样生成多个回答,通过语义等价性构建聚类,用语义簇概率作为奖励信号驱动学习,可适用于数学外的通用推理任务。在语义层面持续最小化回答的不确定性(熵),突破格式固定答案的限制。
为实现语义熵最小化,EMPO 通过最大化下述策略:
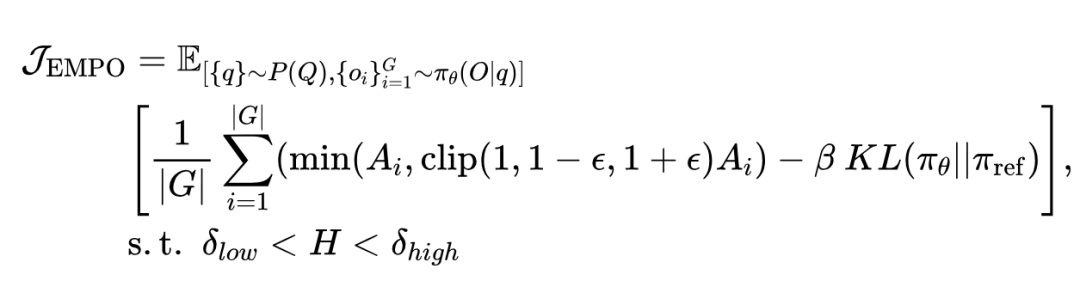
需要指出的是,相较于 GRPO 几乎没有 reward hacking 空间的基于回答正确性的奖励,无监督的熵目标在优化过程中可能存在被“投机取巧”利用的风险。例如,模型可能会倾向于过度拟合那些具有高置信度的常见回复模式(例如总是简单的回复 “I don’t know”),以获取更高的奖励,而不真正进行深入推理。
为应对这一问题,文章提出了一种简单的熵阈值控制策略:通过设置双阈值(即 和 ),仅对不确定性处于适中范围的提示进行优化,从而避免模型对于过简单过困难问题的优化。
未来若能设计出更有效的无监督代理目标,将有望进一步提升模型的推理能力,同时降低奖励欺骗的风险。
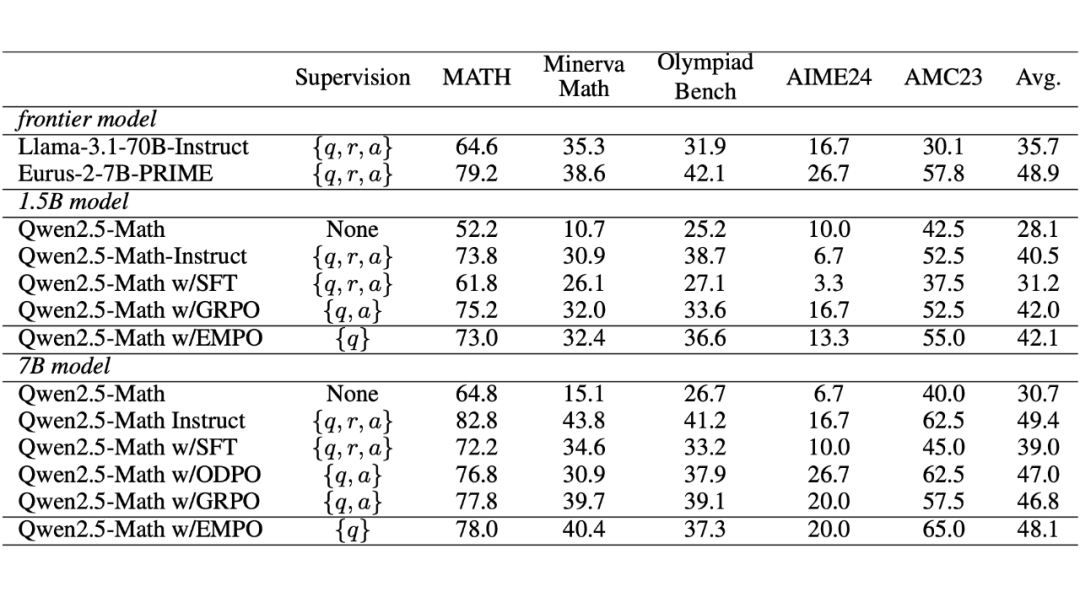
相比依赖有监督信号的 GRPO,EMPO 仅以问题本身作为唯一监督信号,在无需标注答案或推理轨迹的条件下,仅通过 20K 条推理数据微调,便在数学推理任务中展现出显著性能提升:
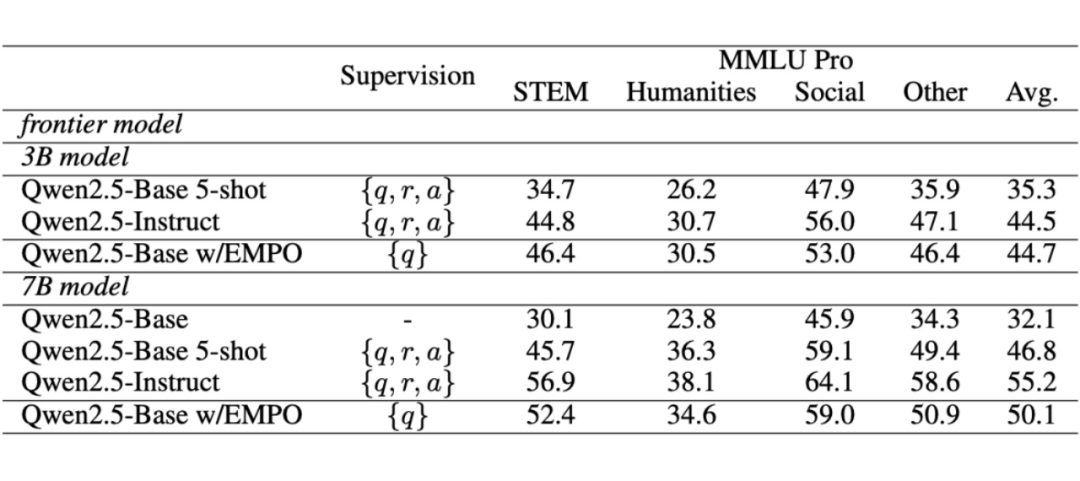
EMPO 可适用的推理任务不只包括数学,还包括其他通用推理任务,如物理、化学、生物、法律、医学等通用推理任务。这些问题答案形式自由,正确答案不唯一。
针对更一般的 free-form 的推理任务,EMPO 首先使用蕴含模型(bert-like 的小模型、或参数量 ≤ 1B 的语言模型)对不同回复根据语义相似性进行聚类,计算语义层面的概率作为奖励信号,克服了传统的 GRPO 无法计算开放问答奖励的局限性,通过无监督 RL 微调,模型的通用推理任务能力得到进一步提升:
文章进一步对 EMPO 起作用的原因进行了解释。在经典机器学习中,熵最小化是常用的无监督优化目标。EMPO 可以看作经典熵最小化学习目标在 LLM 推理领域的拓展,即:在语义空间最小化预测的熵进行无监督学习。
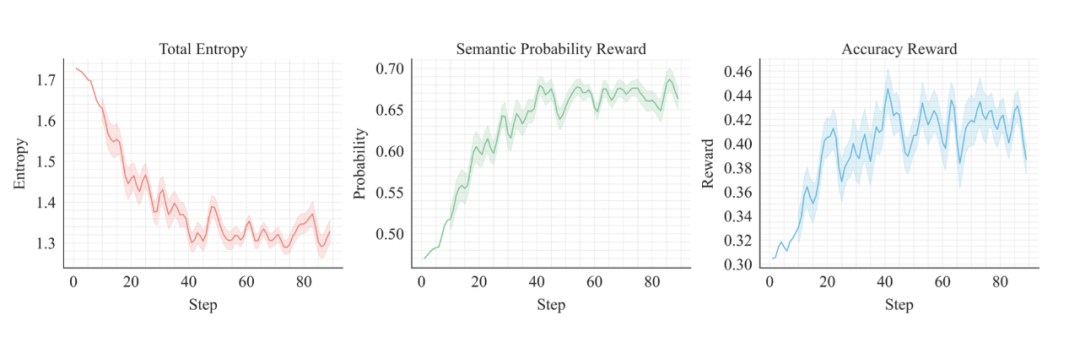
对 Qwen2.5-Math-7B Base 模型在上应用 EMPO 进行微调,训练过程的可视化如下:
-
左图展示了语义熵的滑动平均变化,稳定下降;
-
中图显示了无监督奖励信号的上升趋势;
-
右图呈现了模型在训练数据上的准确率提升轨迹。
文章进一步对 EMPO 起作用的原因进行了解释。在经典机器学习中,熵最小化是常用的无监督优化目标。EMPO 可以看作经典熵最小化学习目标在 LLM 推理领域的拓展,即:在语义空间最小化预测的熵进行无监督学习。
对 Qwen2.5-Math-7B Base 模型在上应用 EMPO 进行微调,训练过程的可视化如下:
-
左图展示了语义熵的滑动平均变化,稳定下降;
-
中图显示了无监督奖励信号的上升趋势;
-
右图呈现了模型在训练数据上的准确率提升轨迹。
上述结果表明,EMPO 能够降低模型在无标注数据上的语义熵,进而无监督提升了模型的性能。
为什么 EMPO 能够起作用?
EMPO 是经典机器学习中熵最小化在大语言模型推理任务上的拓展,语义熵(semantic entropy)是经典的香农熵在大语言模型上的自然拓展,而前者已被广泛验证与大模型的错误(幻觉)输出有强的负相关性,因此语义熵最小化能够作为代理优化目标提升模型性能。
与基于多数投票或模型自我评估的 self-training 相比,语义熵具有更完备的理论支撑,进一步结合熵阈值过滤机制后,能够提供更精细、可靠的细粒度监督信号。
EMPO 起作用说明了什么?
在文章 7B 模型的实验中,EMPO 的表现与 GRPO 和 Online-DPO 等有监督方法相当,而它本身却完全不依赖外部监督。
这一不寻常的观测结果促使文章提出了一些可能的解释:预训练阶段已经赋予了 Base 模型的全部能力,而微调更像是对输出风格的迁移,使模型定位到合适的输出空间。
基于这一假设,文章认为 EMPO 的出色表现归功于 Qwen Base 模型强大的预训练过程。文章猜测 Qwen Base 在预训练过程中已经见过许多推理语料,而激发模型本身已有的推理能力并不需要非常密集的监督信号。这一猜测也能够和同期的其他工作相互印证 [3]。

(文:PaperWeekly)