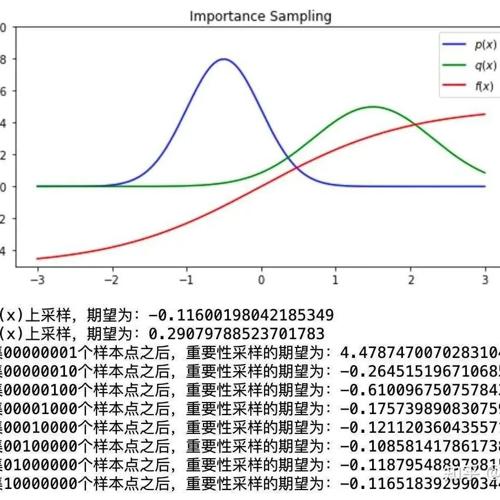
无直接数据可用,AI怎么学会「干活」?微软团队揭秘AI从语言到行动的进化之路 下午11时 2025/01/21 作者 机器之心 AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000
让7B千问模型超越o1,微软rStar-Math惊艳登场,网友盛赞 下午4时 2025/01/10 作者 机器之心 机器之心报道 机器之心编辑部 OpenAI o1 给大模型规模扩展 vs 性能的曲线带来了一次上翘。
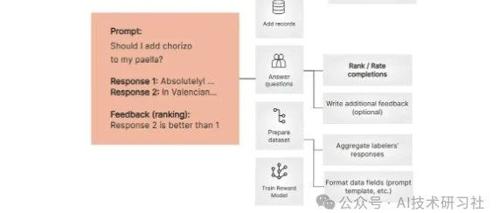
用Python实现RLHF奖励模型构建,全方位提升模型表现! 下午10时 2024/12/29 作者 AI技术研习社 从 0 到 1:用 RLHF 和 Python 构建奖励模型,全面提升语言模型能力!
让AI眼里有活主动干!清华&面壁等开源主动交互Agent新范式 下午8时 2024/11/28 作者 量子位 清华大学与面壁团队开源新一代主动Agent交互范式,使AI具备主动观察环境和提出任务的能力。相比传统被动式Agent,主动式Agent能够预判用户需求并自主帮助解决问题。