QwenLong-L1:迈向具备长上下文推理能力的大型语言模型的强化学习方法
本文提出了一种强化学习框架QwenLong-L1,旨在提升大语言模型在长上下文中的泛化能力,并通过逐步扩展上下文长度、混合奖励函数等方法实现这一目标。
本文提出了一种强化学习框架QwenLong-L1,旨在提升大语言模型在长上下文中的泛化能力,并通过逐步扩展上下文长度、混合奖励函数等方法实现这一目标。
Unsloth 发布了GRPO的新互动教程,用户可以轻松微调Qwen3-Base并开启其思考模式,实现几乎无监督学习。

RLMs的最新发展及其复现研究总结,强调监督微调和基于可验证奖励的强化学习方法的重要性,并讨论了数据构建、训练策略和奖励设计的关键要素。
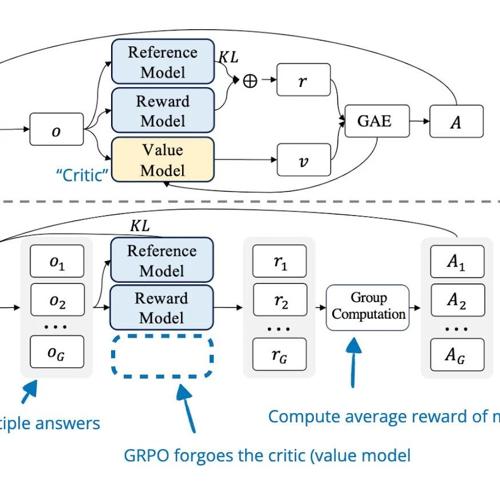
Sebastian Raschka 分享了关于强化学习推理现状的文章内容,包括理解推理模型、RLHF 基础知识、PPO 算法介绍及 GRPO 的应用等,并探讨了训练推理模型的经验和研究论文。