
Sebastian Raschka(《从零构建大模型》作者)刚发的长篇博文:强化学习推理现状 — 理解 GRPO 以及从推理模型论文中获得的新见解。具体内容包括:
-
理解推理模型 -
RLHF 基础知识:一切从何开始 -
PPO 简介:RL 的主力算法 -
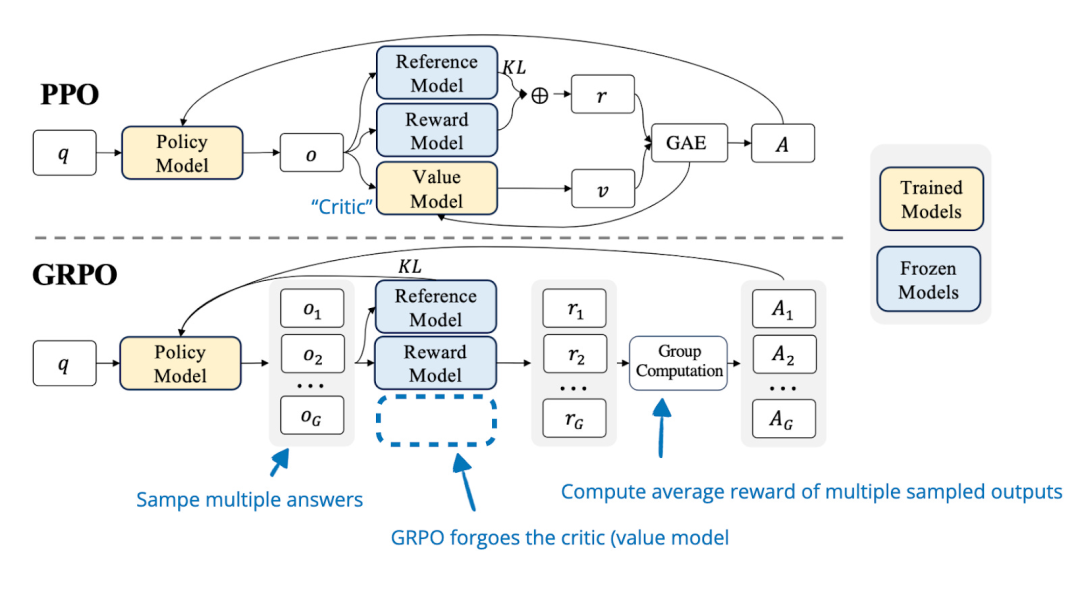
强化学习算法:从 PPO 到 GRPO -
RL 奖励建模:从 RLHF 到 RLVR -
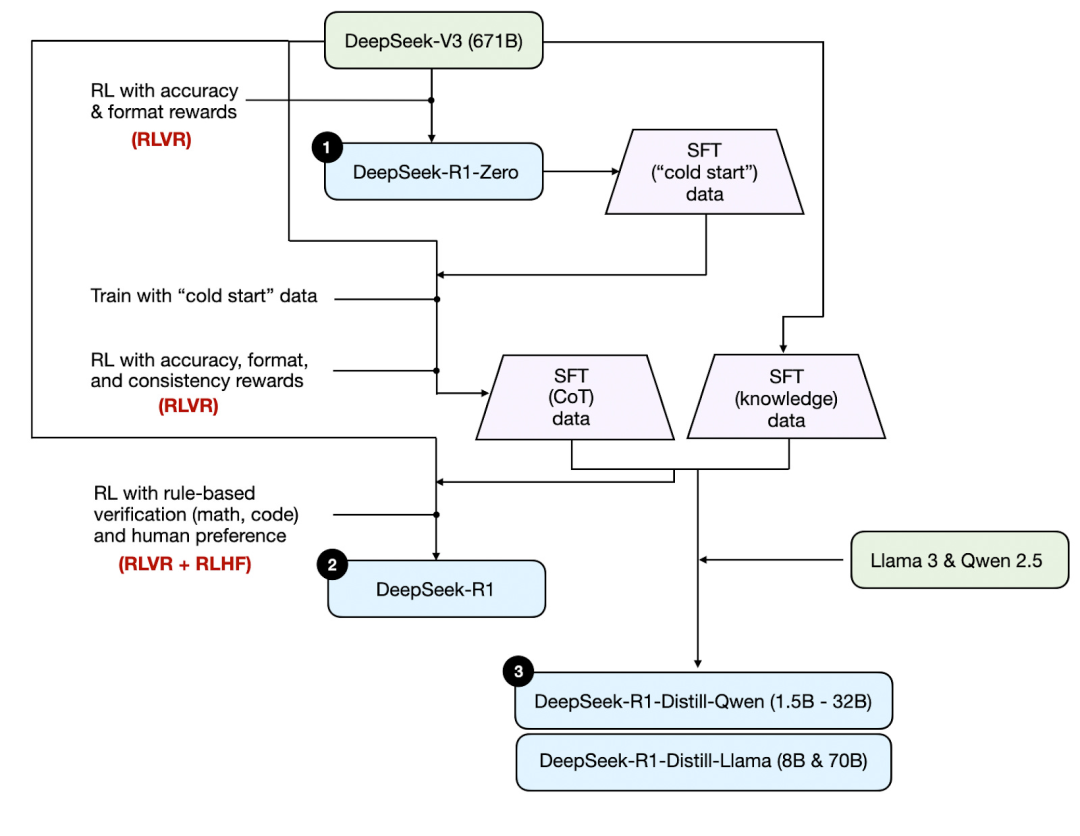
DeepSeek-R1 推理模型的训练方式 -
近期强化学习论文中关于训练推理模型的经验教训 -
关于训练推理模型的值得关注的研究论文
参考文献:
[1] https://magazine.sebastianraschka.com/p/the-state-of-llm-reasoning-model-training
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍|报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)