
强化学习推理现状 — 理解 GRPO 以及从推理模型论文中获得的新见解
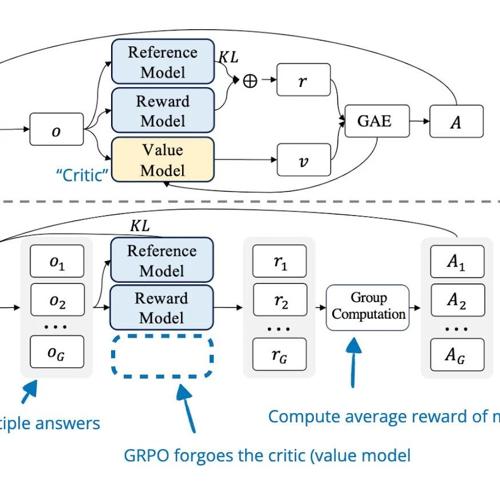
Sebastian Raschka 分享了关于强化学习推理现状的文章内容,包括理解推理模型、RLHF 基础知识、PPO 算法介绍及 GRPO 的应用等,并探讨了训练推理模型的经验和研究论文。
Sebastian Raschka 分享了关于强化学习推理现状的文章内容,包括理解推理模型、RLHF 基础知识、PPO 算法介绍及 GRPO 的应用等,并探讨了训练推理模型的经验和研究论文。
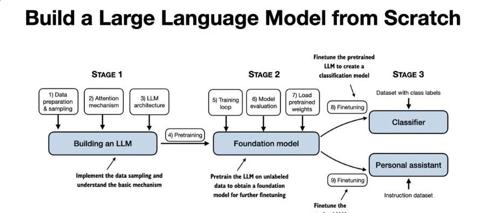
Sebastian Raschka 的《从零构建大模型》是一本帮助读者理解并实战大模型开发的书。通过直接、清晰的教学方式,本书涵盖了从数据准备到模型部署的全流程,适合Python基础和普通笔记本硬件条件的开发者。

2025 年以来,AI 大模型持续火热。从 DeepSeek、GPT-4 到 Gemini 2.0,各家模型参数动辄千亿级。《Build a Large Language Model (From Scratch)》通过 PyTorch 实现 LLM 架构,并涵盖 Transformer 细节与大规模预训练。