
PPO


verl-pipeline:为大规模语言模型(LLM)的强化学习训练提供高效、灵活的解决方案
Agentica-project/verl-pipeline 提供高效灵活的解决方案支持高达70B参数模型和数百个GPU训练,集成多种主流LLM框架及强化学习算法。
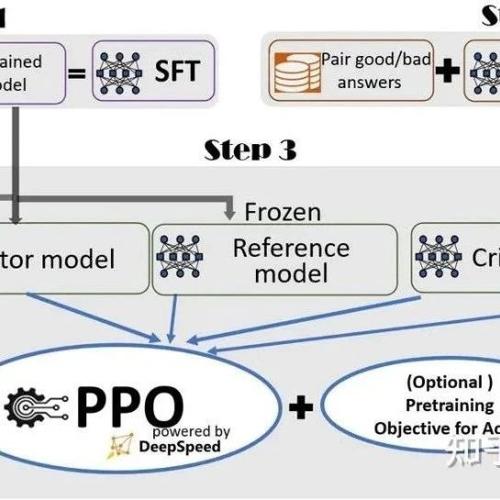

DeepSeek-R1发布100天后:全面复盘推理大模型复现研究及未来!

RLMs的最新发展及其复现研究总结,强调监督微调和基于可验证奖励的强化学习方法的重要性,并讨论了数据构建、训练策略和奖励设计的关键要素。
强化学习推理现状 — 理解 GRPO 以及从推理模型论文中获得的新见解
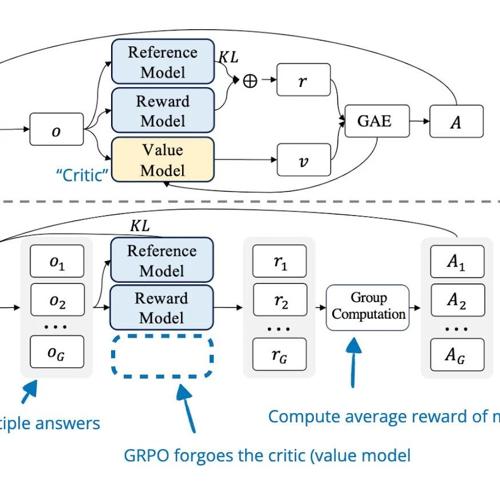
Sebastian Raschka 分享了关于强化学习推理现状的文章内容,包括理解推理模型、RLHF 基础知识、PPO 算法介绍及 GRPO 的应用等,并探讨了训练推理模型的经验和研究论文。

MLNLP社区发布《动画中学强化学习笔记》项目!

MLNLP社区推出了一门通过动画展示强化学习的课程,帮助初学者快速入门这一复杂领域。项目内容包括基础概念介绍和常见算法演示,通过简洁的笔记和动画演示来解释强化学习的核心原理。
