



监督微调是通过高质量的数据集来提升推理语言模型(RLMs)的关键方法之一。详细介绍了用于监督微调的数据集,包括数据收集、数据集细节和分析讨论:
1.1 数据收集与整理流程
-
数据来源:数据集通常从数学、科学、编程和谜题等多个领域收集问题,来源包括现有基准测试和网络爬取。
-
数据清洗:通过去重(例如基于嵌入相似性或n-gram)、拒绝采样和验证正确性等多轮过滤来提升数据质量。
-
难度和多样性:在选择过程中,许多数据集强调问题的难度和多样性,使用启发式方法或模型通过率来优先选择更难的问题。
-
验证方法:数学问题通过Math Verify验证,编程问题通过执行或单元测试验证,一般任务通过LLM判断验证。
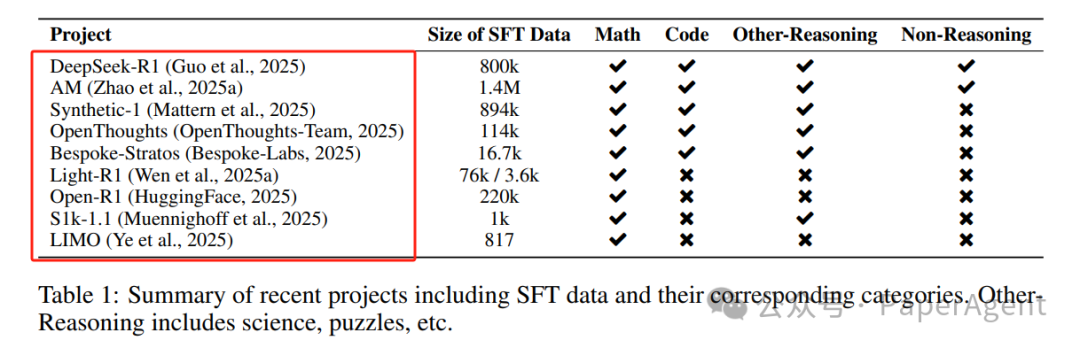
1.2 现有数据集细节
1.3 分析与讨论
-
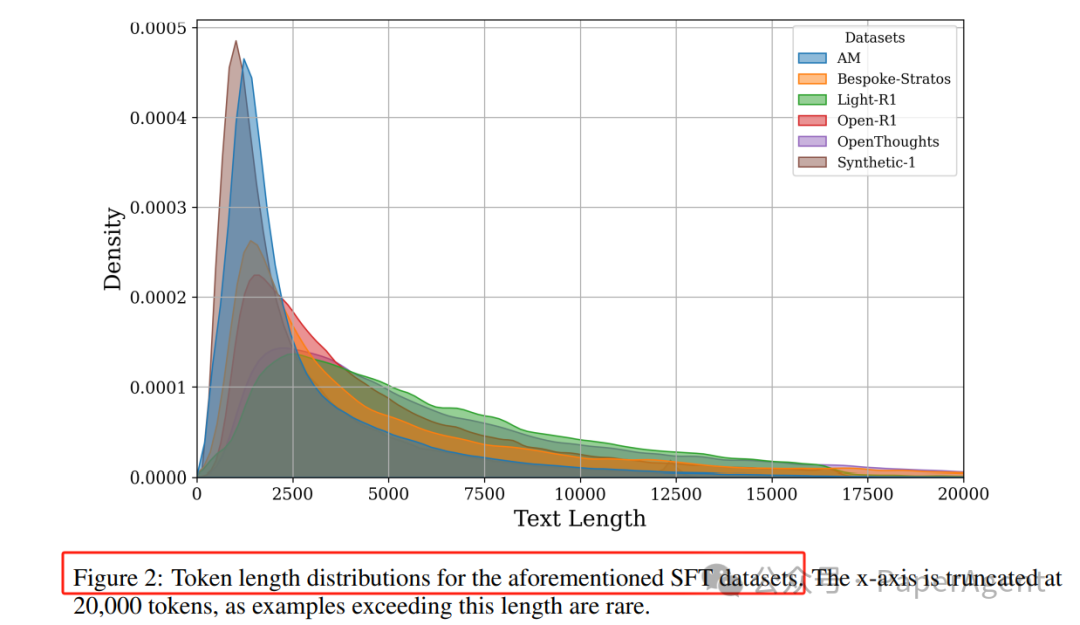
长度分布:不同数据集的CoTs长度分布存在差异,例如AM和Synthetic-1偏向较短序列,而Light-R1和Open-R1则有更长的尾部。
-
数据去重:Light-R1和LIMO明确提到在数据整理过程中进行数据去重,以防止数据泄露。
-
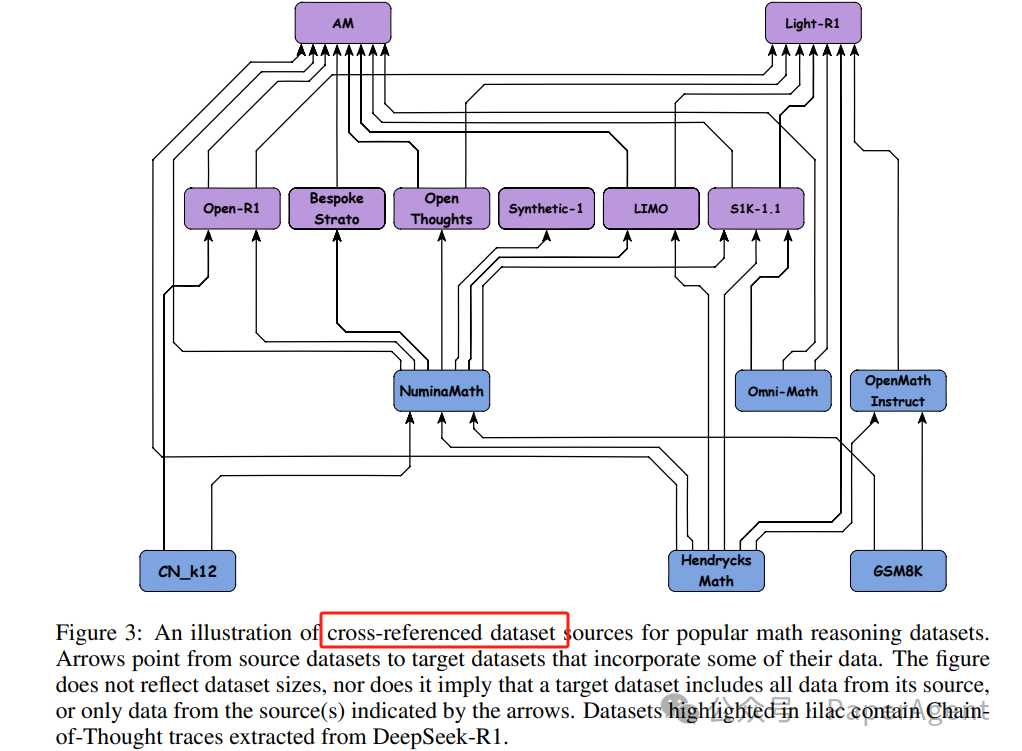
数据来源交叉引用:许多数学推理数据集并非独立创建,而是从现有数据集中收集或衍生而来。例如,多个数据集从NuminaMath获取问题。
1.4 训练与性能比较
-
监督微调形式化:通过最小化负对数似然损失来更新模型参数,使模型最大化参考完成的概率。
-
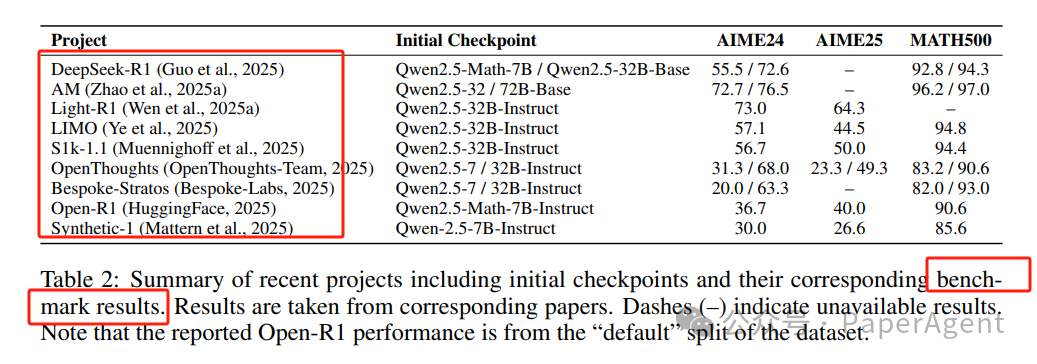
性能比较:表格展示了不同SFT方法在数学推理基准测试(如AIME24/25和MATH500)上的性能。LIMO和S1k-1.1展示了即使数据集较小,也可以通过精心策划的数据集取得强性能。
-
训练细节:对于长上下文任务(如复杂推理),通常会调整RoPE缩放因子和模型的最大上下文长度。常用的训练超参数包括学习率和批量大小。
2.1 RL 数据集
数据集主要涵盖数学和编程问题,并确保在训练过程中可以验证模型的输出。

-
数据集统计:表3展示了多个用于RLVR的数据集及其统计信息。这些数据集包括DeepScaleR、Skywork-OR1、Open-Reasoner-Zero等,涵盖了数学、编程和一般推理任务。
-
数据收集与验证:数据集的构建过程通常包括从多个来源收集问题,然后通过严格的验证过程确保数据的正确性和可验证性。例如,Skywork-OR1从数学竞赛和编程平台收集数据,并通过Math-Verify和单元测试验证每个问题的答案。
-
数据清洗与去重:为了确保数据质量,许多数据集在构建过程中进行了严格的清洗和去重操作,以避免数据泄露和重复样本。
2.2 RL 组件
详细讨论了强化学习的关键组件,包括算法设计、奖励系统和采样策略。
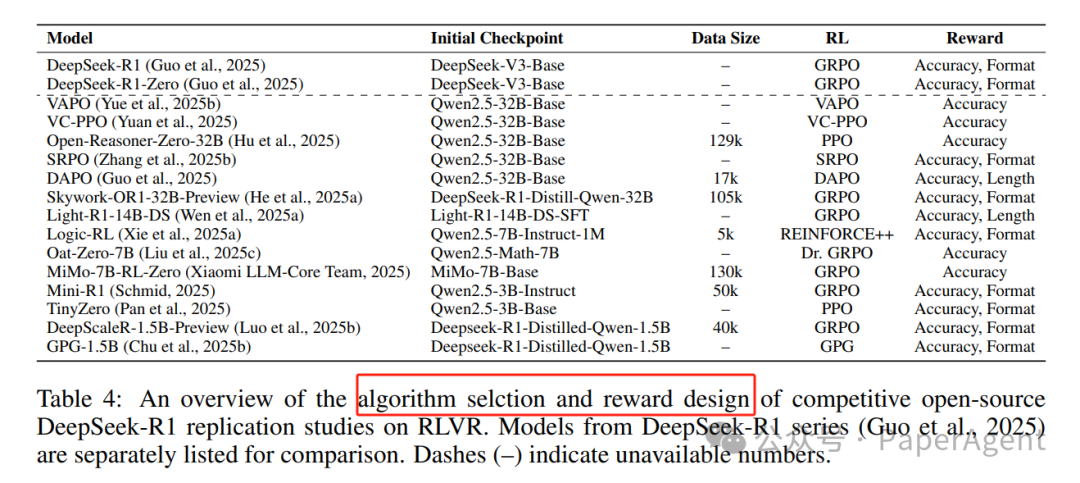
2.2.1 算法设计
-
PPO和GRPO:PPO(Proximal Policy Optimization)和GRPO(Group Relative Policy Optimization)是RLVR中最常用的算法。GRPO通过去除PPO中的批评家模型和GAE计算,提高了效率和内存使用。
-
算法变体:许多研究对PPO和GRPO进行了改进,例如DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization)通过动态采样和去耦剪辑提高了训练稳定性和效率。其他变体包括REINFORCE++、CPPO(Completions Pruning Policy Optimization)和GPG(Group Policy Gradient)。
-
训练目标:这些算法的目标是最大化模型在生成响应时的预期奖励,同时通过KL散度惩罚等方法约束策略的更新,以避免过度偏离初始策略。
2.2.2 奖励设计
-
准确性奖励:这是最基本的奖励类型,通常对正确答案赋予1分,错误答案赋予0分或-1分。
-
格式奖励:鼓励模型生成符合特定格式的响应,例如在数学问题中要求逐步推理。
-
长度奖励:通过奖励或惩罚响应的长度来控制模型的输出长度,例如对过长的响应施加线性惩罚。
2.2.3 采样策略
-
课程学习:通过逐步增加任务难度来提高模型的训练效率。例如,Open-Reasoner-Zero在训练过程中逐步引入更具挑战性的样本。
-
拒绝采样:通过过滤掉不正确的样本或低质量的响应来提高训练效率。例如,DAPO和Skywork-OR1通过动态采样策略过滤掉零优势样本组。
-
历史重采样:通过重新采样上一轮训练中未正确预测的样本,集中训练模型的弱点。
2.3 分析与讨论
总结了基于可验证奖励的强化学习在训练推理语言模型时的关键发现:
2.3.1 训练数据配方
-
数据量和多样性:大量多样化的数据对于训练有效的推理模型至关重要。例如,Skywork-OR1和Seed-Thinking-v1.5等项目通过从多个领域收集数据来提高模型的泛化能力。
-
数据难度:选择难度适中的数据对于模型训练至关重要。例如,Light-R1和Skywork-OR1通过筛选出模型通过率适中的样本,确保模型在训练过程中能够学习到有价值的推理过程。
-
数据清洗:严格的数据清洗过程可以减少噪声,提高模型的训练效率。例如,BigMath和DAPO通过去除不可验证的问题和错误答案,确保数据集的质量。
2.3.2 RL 算法设计
-
算法选择:PPO、GRPO及其变体在训练推理语言模型时表现出不同的性能。例如,Open-Reasoner-Zero发现PPO在某些情况下比GRPO更稳定。
-
算法改进:许多研究对现有算法进行了改进,以提高训练效率和稳定性。例如,DAPO通过动态采样和去耦剪辑提高了训练过程的稳定性。
2.3.3 模型大小和类型
-
模型大小:从1.5B到32B的模型在RLVR训练中均表现出良好的性能。例如,DeepScaleR通过扩展1.5B模型的RL训练,超越了OpenAI的o1-preview模型。
-
模型类型:RLVR不仅适用于基础模型,还适用于经过蒸馏的长推理链模型(如R1-distilled模型)。
2.3.4 上下文长度
-
最大响应长度:允许的响应长度对模型的推理能力有重要影响。例如,Light-R1将最大响应长度设置为24k,而Skywork-OR1则逐步增加最大响应长度至32k。
-
课程学习:通过逐步增加最大响应长度,可以提高模型在长推理任务中的性能。
2.3.5 奖励建模
-
准确性奖励:简单的准确性奖励通常是最有效的,但其他类型的奖励(如格式奖励和长度奖励)也可以在某些情况下提高模型性能。
-
奖励设计:奖励设计需要在准确性和多样性之间取得平衡,以避免奖励黑客攻击和过拟合。
2.3.6 KL 损失
-
KL损失的作用:KL损失用于约束在线策略与参考策略之间的差异,但某些研究发现,在大规模RL训练中,KL损失可能不是必需的,甚至可能限制响应长度的增加。

https://arxiv.org/pdf/2505.00551100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models
(文:PaperAgent)