


新智元报道
新智元报道
【新智元导读】微软一口气推出了Phi-4推理模型系列:Phi-4-reasoning、Phi-4-reasoning-plus和Phi-4-mini-reasoning。参数最多只有14B,能在本地高性能笔记本电脑上流畅运行。而3.8B的Phi-4-mini-reasoning甚至超越8B参数的DeepSeek-R1蒸馏模型,释放了小模型的推理能力!
现在AI流行推理模型。
可惜,4月没有等来DeepSeek的第二代推理模型DeepSeek-R2。
但微软,最近上新了Phi-4的推理模型,包括Phi-4-mini-reasoning,Phi-4-reasoning和Phi-4-reasoning-plus。
项目链接:https://huggingface.co/collections/microsoft/phi-4-677e9380e514feb5577a40e4
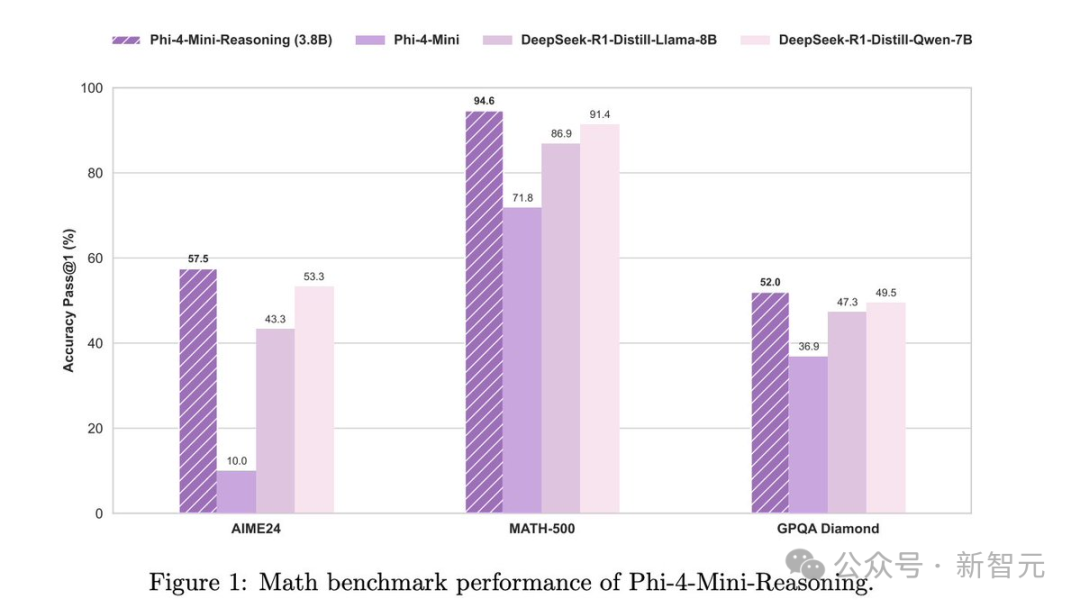
在数学推理上性能超越DeepSeek-R1蒸馏模型,但Phi-4-Mini-Reasoning参数规模更小。
微软AI Frontiers实验室的合作研究经理(Partner Research Manager)Ahmed Awadallah介绍了Phi-4-reasoning,总结了新模型的特点。

这个模型结合了监督微调(使用精心挑选的推理示例数据集)和强化学习进行训练。
-
在推理类基准测试中表现出色,可媲美DeepSeek R1等更大规模的顶级模型
-
在新测试上依然表现强劲(如AIME 2025、HMMT)
-
推理能力具有很强的迁移性/泛化能力,即便只经过监督微调,也能适应全新任务(如k-SAT、数学方程求解、日程规划等)
-
保留并大幅提升通用能力(例如指令理解与执行)
他表示Phi-4还有不少方面需要改进,特别是在上下文长度、编码能力和工具集成方面。
除了模型本身,微软还分享了一份详尽的技术报告,深入解析模型的训练与评估过程。

论文链接:https://www.microsoft.com/en-us/research/wp-content/uploads/2025/04/phi_4_reasoning.pdf
在X上,微软研究院AI Frontiers实验室的主任研究员(Principal Researcher),兼威斯康星大学副教授Dimitris Papailiopoulos介绍了关于Phi-4推理模型更多情况。
他认为Phi-4-reasoning完全达到了研究生水平,而且可以在本地PC上运行。
这超出他对AI发展的预期。

新模型参数虽少,性能却强,是个「小怪兽」。

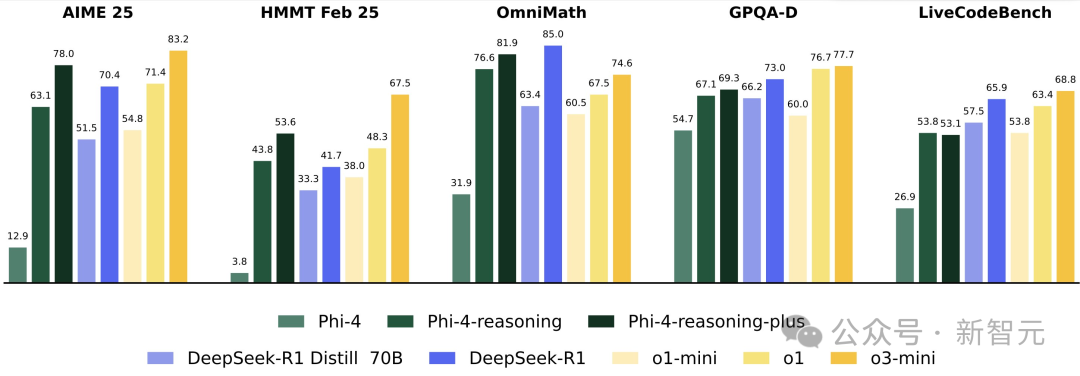
尽管它的参数规模不大,但在诸如AIME、HMMT和OmniMath等数学基准测试中,它的表现优于或媲美更大规模的开放权重模型(如QwQ-32B、R1-70B、R1)及封闭模型(如o1-mini、sonnet 3.7)。
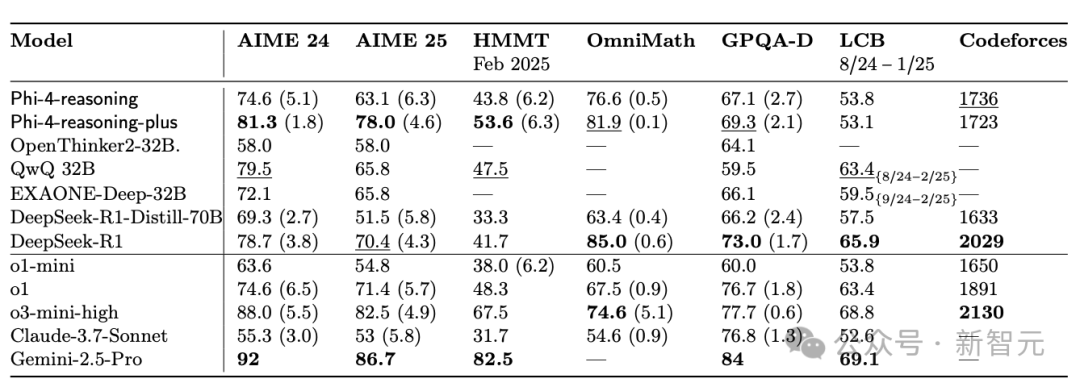
先来聊聊它的「整体得分」: 这个模型的规模精巧,适合在高性能笔记本电脑上流畅运行。
但同时能力出众,能破解许多谜题——这些谜题连更大型的非推理模型,甚至某些推理模型都束手无策。
它还顺利通过了DimitrisEval测试!

令人惊讶的是,推理似乎是一种真正可迁移的「元技能」,甚至只通过 监督微调SFT就能学会!
证据一:即使没有在非推理类任务上进行专门训练,研究者在IFEval、FlenQA以及内部的PhiBench 上依然观察到了显著的性能提升(提升超过10分!)。
另外,在SFT阶段,编码相关的数据也非常少(RL阶段则完全没有涉及),但模型在这方面依然表现不俗,例如在 LCB和Codeforces上的得分大致与o1-mini相当。
此外,Dimitris Papailiopoulos透露,编程是后续版本的重点方向。
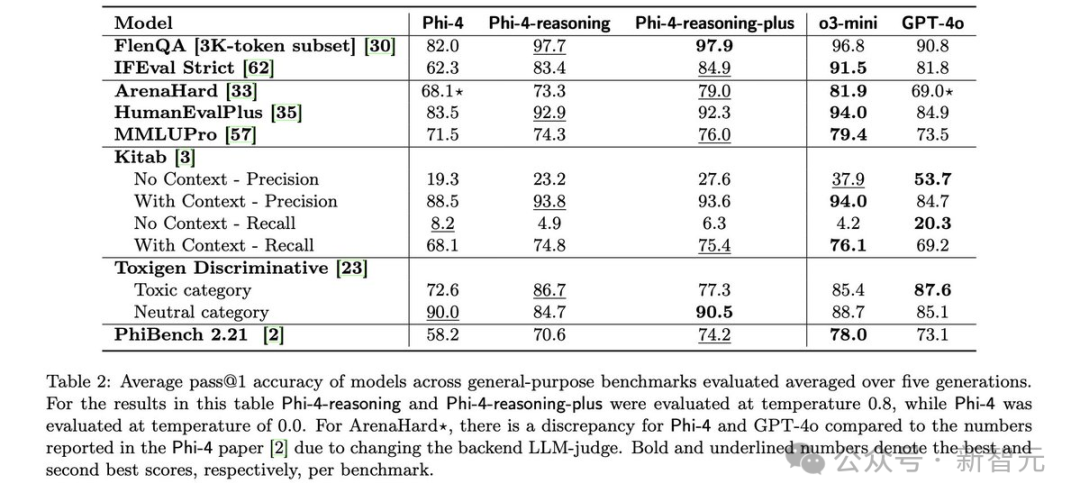
证据二:在完全没有对一些特定问题进行明确训练(无论是SFT还是RL阶段)的情况下,比如旅行商问题、迷宫求解、k-SAT、受限规划等,模型在这些任务上的表现依然非常出色!

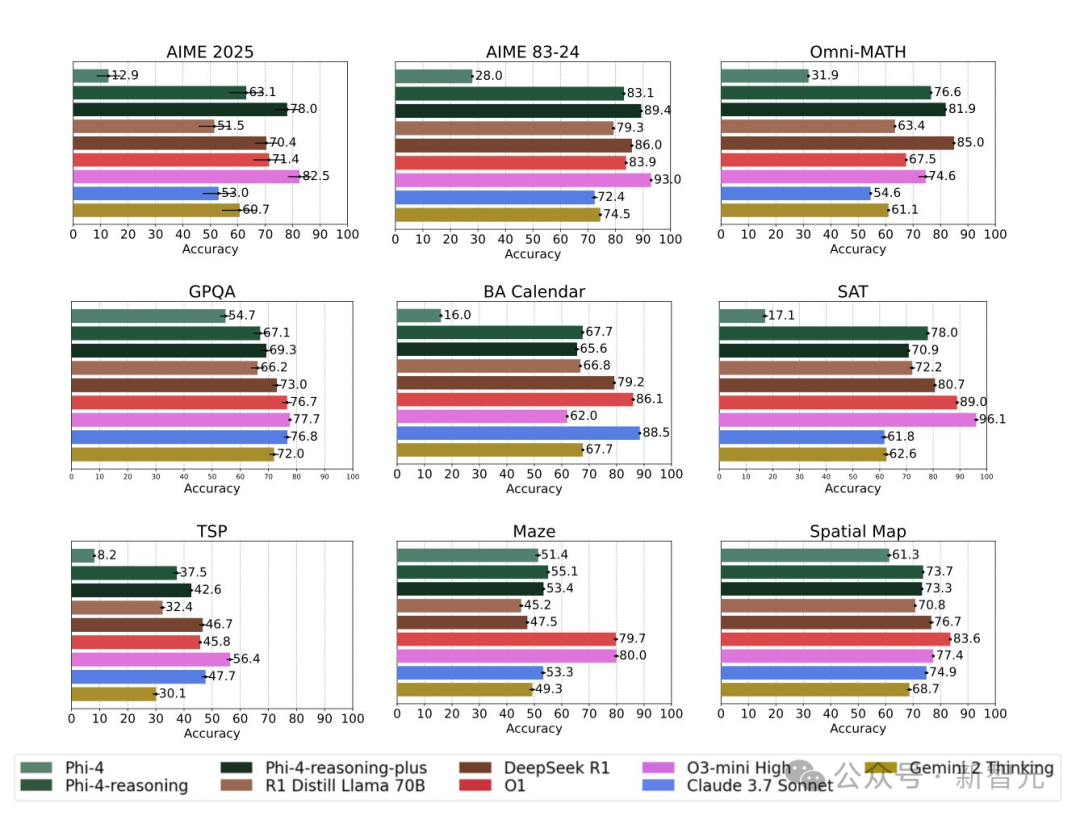
而Phi-4(甚至GPT-4)在这些任务上都无法做到这一点。
这充分说明了推理能力确实可以作为一种技能迁移!
仅仅经过一轮很短的强化学习(只用了6000个样本,相比之下SFT用了140万个示例),模型的推理机制就像是被「锁定」了一样。
这让Dimitris Papailiopoulos特别震撼。
他感觉这就好像强化学习让模型学会了用「自己的语言」去推理,在AIME和HMMT上的准确率提高了约 10%,而在难题中的平均回答长度也增加了 50%。
强化学习真的有效!!
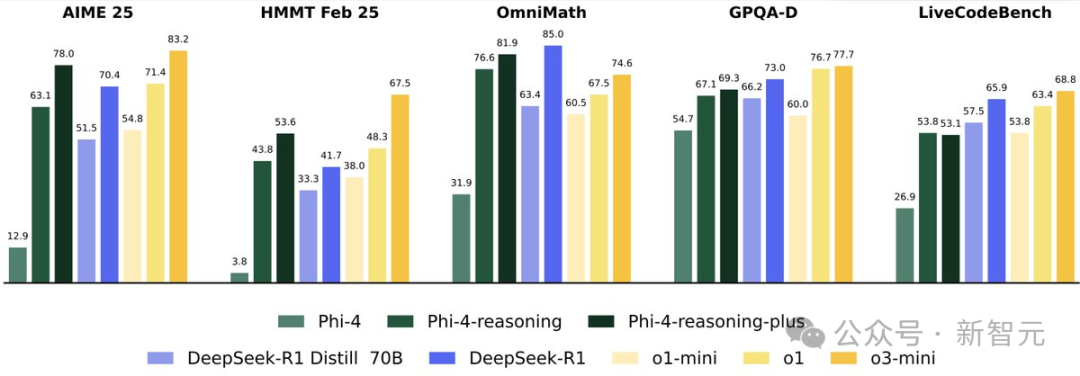
这次发现这种推理机制被「锁定」的现象,通常会让模型的输出分布更加集中,准确率也更高。
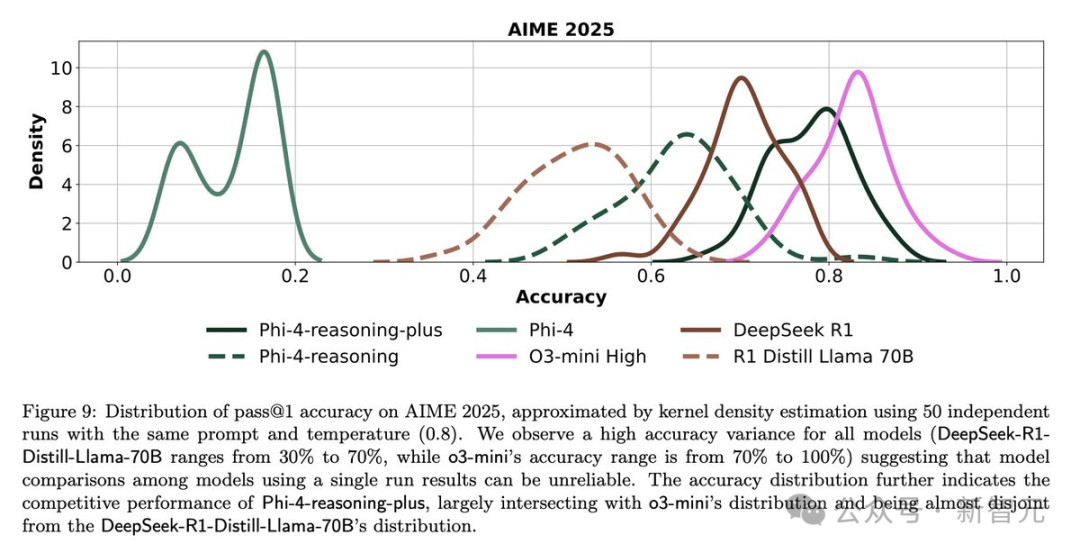
强化学习能够显著提升模型的能力,这一点也在微软以前的研究中也有所体现。

论文链接:https://arxiv.org/abs/2412.01951
在强化学习阶段,新模型甚至没有对数据进行特别优化:6000个问题只是从一个更大的精选数据集中随机抽取的。
那么,为什么微软没有进行更多的强化学习训练?
因为模型生成了超出32k 上下文长度(模型未训练过的长度)的问题答案,他们只能对其进行截断。
另外,借助并行推理计算(比如 Maj@N),新的推理模型几乎已经在AIME 2025上达到了性能上限,甚至超越了它的老师模型(o3-mini)的 pass@1表现。
而且在2025年2月之前完成了所有数据的收集,HMMT也是如此。
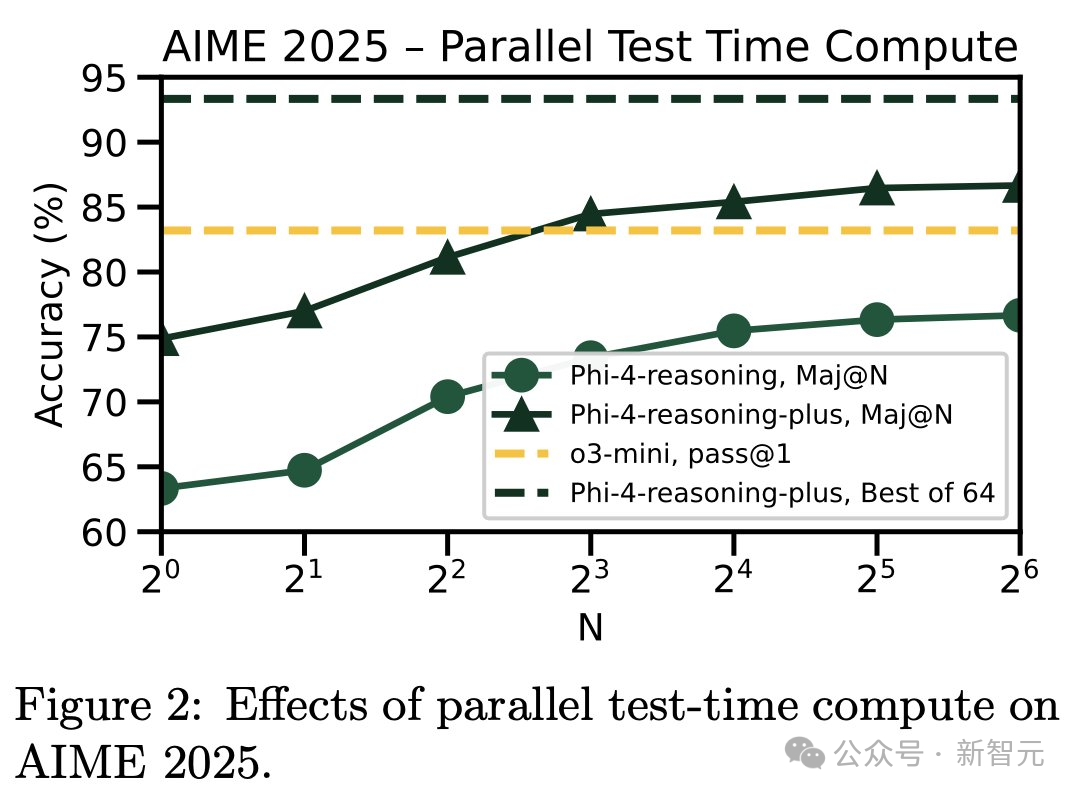
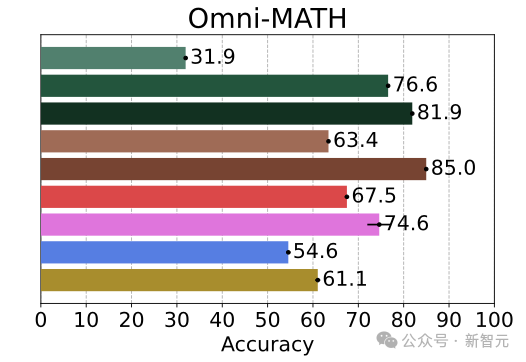
在其他任务中,研究者也观察到了「青出于蓝」的现象,比如OmniMath和日程规划(Calendar Planning)任务。
SFT阶段的提示词设计,加上后续的强化学习流程,似乎让模型具备了「自我提升」的能力,超出了教师模型提供的知识范围。
下图中洋红色代表o3-mini,绿色代表Phi。
 |
 |
一个有趣的现象是:响应长度处于前25%的长文本,往往与错误答案强相关!
但另一方面,在大多数评估中,整体的平均回答长度越长,准确率反而越高。
也就是说,测试时加大计算资源确实有帮助,但模型在「卡住」时也容易「啰嗦」。

关于模型的局限性,也有一些需要注意的地方:
-
目前还没有对超过32k上下文长度的处理能力进行充分扩展或测试。
-
模型在处理简单问题时容易「想太多」,而在自我评估上可能显得过于冗长。
-
对多轮对话的能力还没有进行广泛测试。
当然还有更多「盲区」有待发现,但整体来看,研究团队感觉自己正走在正确的道路上!

微软研究院的主任研究经理(Principal Research Manager)Suriya Gunasekar,隶属于负责开发Phi系列模型的「AGI物理学」团队,则重点介绍了工作的核心原理。

这次微软的Phi团队将精力集中在后训练阶段,推出了Phi-4-reasoning(只用了SFT)和Phi-4-reasoning-plus(SFT+少量RL)。
这两款都是14B的模型,在推理和通用任务基准测试上都展现了强大的实力,虽体量小但威力不减。
这项工作的核心在于提示选择和针对可迁移、自我提升推理技能的实验探索。
训练过程中有两大惊喜发现:
其一,只要少数领域训练长链式推理(CoT)轨迹,Phi-4 就在日程规划、迷宫求解(无需视觉输入)、IFEva、FlenQA、KITAB(基于查找的问答)及内部 PhiBench 等多项任务中,性能实现大幅提升;
其二,即使只用6000个数学示例做最小程度的RL训练,模型在部分基准测试中的表现也显著提高,最高提升幅度达10%(不过token使用量增加了约 1.5 倍),同时在RL阶段也观察到技能的跨领域迁移现象。
也就是说,与OpenAI和Google等主要竞争对手相比,微软Phi-4推理系列展示了新的可能性:利用高质量数据和精细的训练策略,小模型可以在特定任务中媲美甚至超越大型模型。
推理模型Phi-4-reasoning,拥有 140 亿参数,在复杂推理任务中表现强劲。
该模型基于 Phi-4 进行监督微调训练,使用的是一组精心挑选的「可传授」(teachable)提示词,这些提示兼具适当的复杂度与多样性;训练过程中使用 o3-mini 生成的推理示例作为参考。
Phi-4-reasoning能够生成详细的推理链,充分利用推理过程中的计算资源。
在此基础上,微软进一步开发了Phi-4-reasoning-plus。
它在原模型的基础上通过一小阶段基于结果的强化学习进行了增强,生成的推理链更长,性能也更强。
研究表明,精心设计的SFT数据集对于推理语言模型的效果有显著提升作用,而强化学习(RL)则能在此基础上进一步放大这种提升。
在SFT实验中,即使是在这种相对简单的生成设置下,对种子问题的精挑细选与严格过滤依然是模型取得成功的关键。
他们将整套训练数据都经过了严格去污染处理流程,确保不包含与广泛使用的推理或通用基准测试题高度重合的数据,包括一些未在本报告中提到的基准。
被去污染处理的完整基准测试列表如下:
-
数学与推理类:AIME-2024、MATH、GPQA、OmniMATH、GSM8k
-
编程类:LiveCodeBench、Codeforces、HumanEval、MBPP
-
问答与通识类:SimpleQA、DROP、AGIEval、ARC-Challenge、ARC-Easy、CommonsenseQA、OpenBookQA、PIQA、WinoGrande
-
其他评估任务:SWE-Bench Verified、ArenaHard、MT-Bench、PhiBench
通过对拥有140 亿参数的Phi-4 模型进行监督微调 (Supervised Finetuning, SFT),研究人员得到了Phi-4-reasoning,在此之前没有进行任何强化学习。
SFT目标是提炼基础模型中蕴含的结构化推理能力。
Phi-4-reasoning 的架构与Phi-4模型相同,但有两个关键的修改:
-
推理token (Reasoning tokens):基础模型中的两个占位符token被重新用作
<think>和</think>token,分别用于token一段推理(「思考」)过程的开始和结束。 -
增加的token长度 (Increased Token Length):基础模型 (Phi-4) 最初支持的最大token长度为16K。为了容纳额外的推理token,RoPE的基础频率增加了一倍,并且模型在最大32Ktoken长度下进行了训练。
他们使用了合成方法生成的大量思维链 (chain-of-thought) 推理过程示例。
使用的SFT数据集包含超过140万个提示-回复对,总计83亿个独特的token,涵盖了数学、编程等推理领域,以及用于安全和负责任 AI 的对齐数据 (alignment data)。
图4a展示了关键指标在整个SFT迭代过程中的变化。
在训练的早期,模型就开始使用显式的「思考」token,这表明模型很快就学会了这种浅层的结构化格式。
然而,如图4a所示,思维链模块的有效性和模型的推理能力在整个训练过程中都在提高,这表明模型不仅仅是在复制格式,而是在实际学习推理这项技能。
有趣的是,与强化学习不同,在SFT过程中,研究人员没有看到回复长度的增加。
事实上,如图4b所示,平均回复长度略有下降。
这表明随着训练的进行,模型正在学习更有效地利用其token预算。
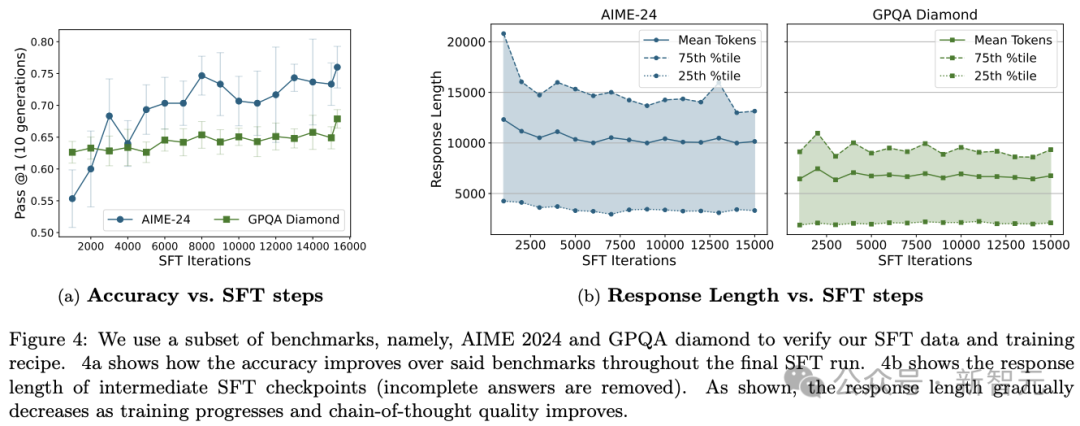
为了系统地评估不同的训练策略,他们使用了固定的基准测试——AIME 2024 和 GPQA diamond——作为进展指标。
总的来说,实验方法可以分为两个阶段:探索 (exploration) 和扩展 (scaling)。
在探索阶段,研究人员使用较短的训练周期和有限的数据源和领域来快速迭代并提取稳健的训练方法。
在随后的扩展阶段,研究人员汇总了早期风险降低实验的结果,并最终确定了SFT设置。
图5总结了这一进展,重点展示了几个关键设计选择的消融实验 (ablations)。
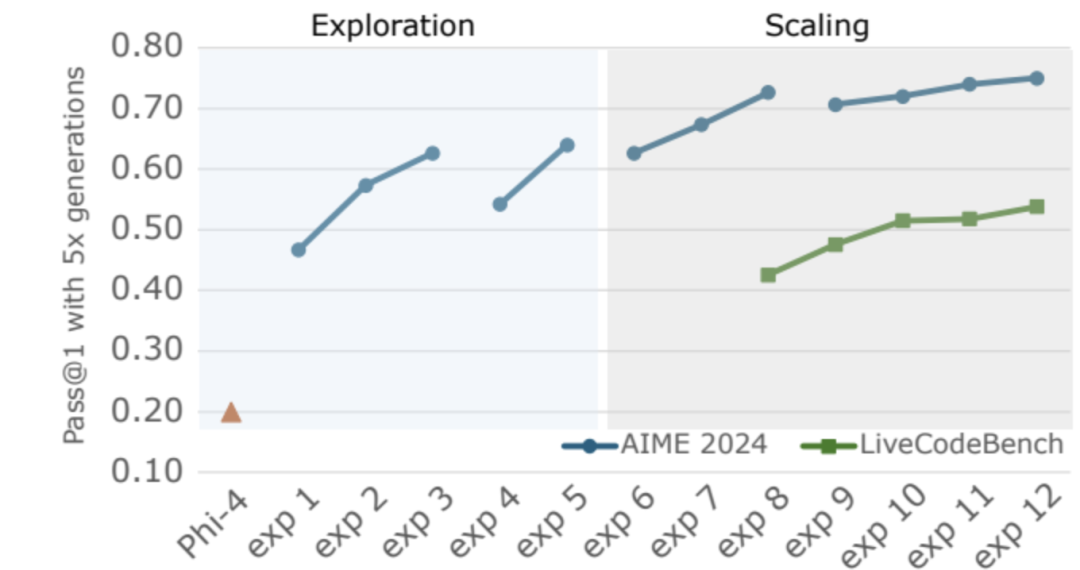
图5:Phi-4-reasoning SFT实验周期的高层次概述
图5展示了Phi-4-reasoning监督微调(SFT)实验周期的高层次概述,包括探索和扩展阶段,使用了一部分示例实验来表示。每个点簇代表一种特定训练设计选择的实验结果。
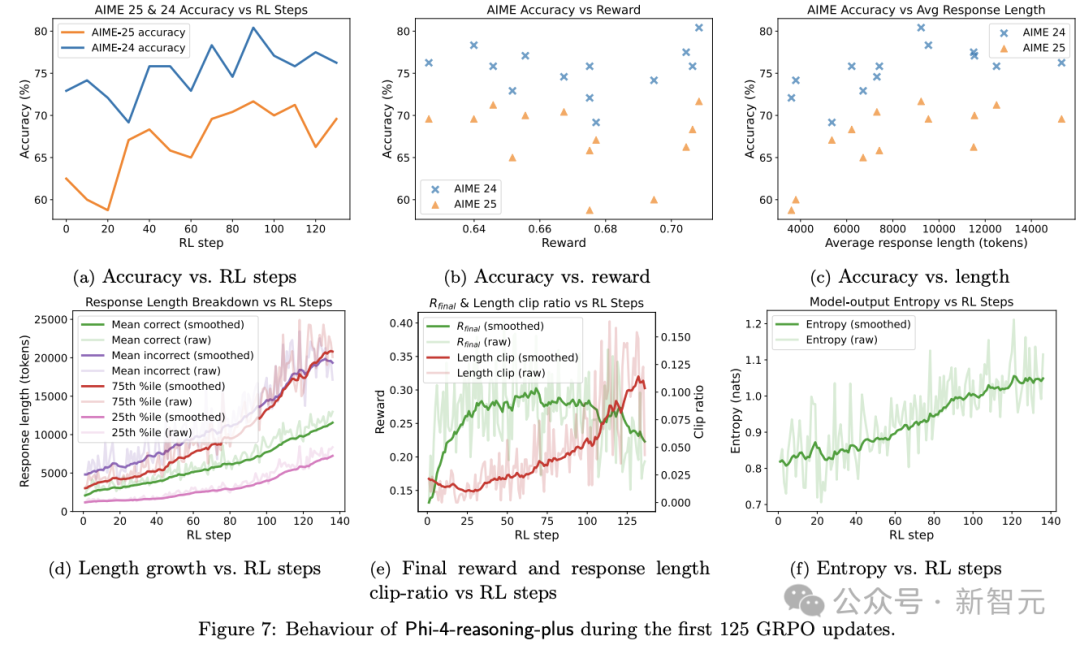
图7展示了Phi-4-reasoning-plus模型在GRPO训练过程中的关键发现。
从监督微调(SFT)基础模型Phi-4-reasoning出发,仅进行90步GRPO训练就将AIME性能提升超10%(图7a)。
继续增加训练步数并未带来额外收益,这表明强SFT模型的潜力已接近性能天花板。需注意的是,GRPO训练中输出被限制在31k token以内,这客观上制约了GRPO的优化空间。
如图7c所示,响应时长与AIME表现呈强相关性,而奖励分数与AIME得分的关联较弱。这种响应长度增长效应正是GRPO训练的预期效果——模型通过增加「思考时长」来提升推理能力。
图7d进一步揭示:由于奖励模型的设计,错误答案的生成长度增速显著高于正确答案(当模型当前回答错误时,系统会激励其进行更长时间的思考)。
事实上,仅基于响应长度(尤其是显著超过中位数的长响应)进行拒绝采样就可能进一步提升GRPO效果。
如图7d所示,训练过程中较短响应(长度位于底部25%分位)的增长趋势与正确答案平均长度相似,而错误答案长度更接近总体响应长度的75%分位。
这种分化现象表明,基于长度的拒绝采样可通过抑制过长的错误输出来提升模型效率。
(文:新智元)