
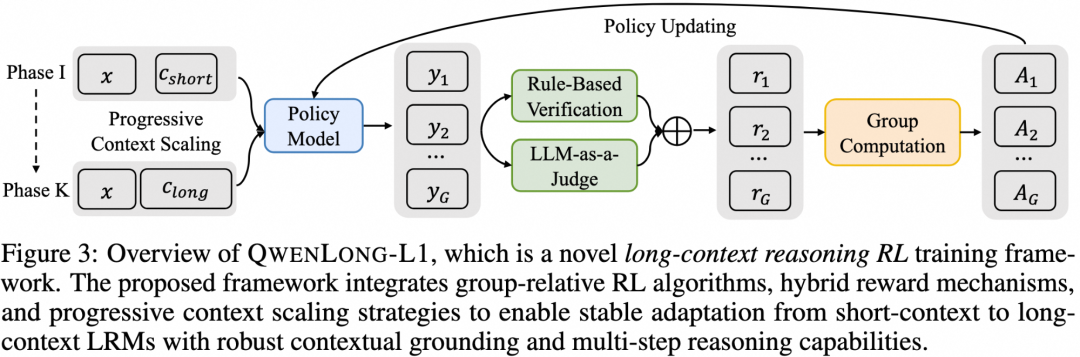
在本研究中,我们提出了 QwenLong-L1,这是一种新颖的强化学习(RL)框架,旨在促进大语言模型(LRMs)从短上下文任务的熟练应对向强健的长上下文泛化能力的转变。在初步实验中,我们展示了短上下文推理与长上下文推理在强化学习训练动态上的差异。

该框架通过 逐步扩展上下文长度 的方式,在强化学习训练中增强短上下文大语言模型的能力。框架由三个核心组件构成:
-
热身阶段的有监督微调(SFT),用于初始化一个鲁棒的策略 -
课程引导的强化学习阶段,帮助模型稳定地从短上下文过渡到长上下文 -
基于难度的回顾采样机制,动态调整训练难度,以激励策略探索
在训练中,我们结合了最新的强化学习算法(如 GRPO 和 DAPO),并集成了 混合奖励函数,将基于规则的奖励与基于模型的二元结果奖励相结合,从而在精确率与召回率之间取得平衡。通过策略优化过程中的 相对优势分组策略,该框架有效引导语言模型学习适用于长上下文的推理模式,从而实现更加稳健的上下文对齐能力和更强的推理能力。
参考文献:
[1] https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B
[2] https://www.arxiv.org/abs/2505.17667
[3] https://help.aliyun.com/zh/model-studio/long-context-qwen-long
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)