


阿里巴巴达摩院的研究团队发布了名为“灵枢”(Lingshu)的医疗多模态大模型,旨在系统性地应对通用AI在临床应用中的挑战。其核心技术贡献与特点如下:
-
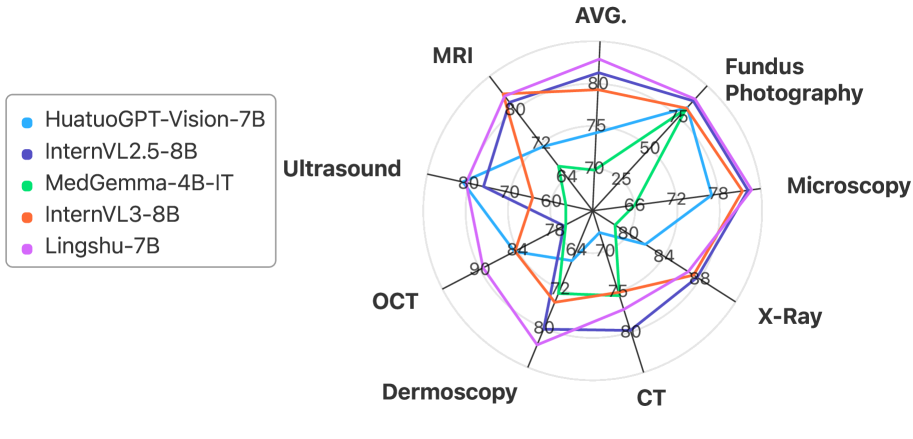
1. 模型性能: 在多项公开的医疗视觉问答(VQA)和报告生成基准测试中,Lingshu的7B和32B模型在同尺寸开源模型中表现出领先性能。值得注意的是,Lingshu-32B在多个多模态VQA和报告生成任务上,其评测结果超过了如GPT-4.1和Claude Sonnet 4等闭源模型。 -
2. 精细化数据工程: 构建了一个大规模、多来源的训练数据集,该数据集由375万开源样本和130万合成样本构成。其核心是一个全面的数据策划流程,包括严格的数据清洗(如使用感知哈希和min-hash LSH去重)和高质量的数据合成。例如,通过一个模拟临床专家报告的五阶段流程,生成了超过10万条详尽的医学长文本描述。 -
3. 多阶段训练范式: 采用一个从“浅层对齐”到“深层对齐”再到“指令微调”的渐进式训练策略,系统性地将医学知识注入模型。训练过程中的学习率、批次大小等超参数针对不同阶段和模块进行了精细调优。此外,初步探索了强化学习(RLVR)在医疗推理任务上的应用。 -
4. 标准化的评测框架: 发布了开源评测框架MedEvalKit,整合了16个主流医学评测基准,涵盖了从基础医学知识(如MMLU-Medical)到专业执业资格考试(如MedQA-USMLE)的多个难度层级。 -
5. 广泛的模态支持与临床应用分析: 模型支持超过12种医疗影像模态。案例研究通过具体的模型输出,展示了其在医学诊断、放射学报告生成、分子生物学知识解释等多个模拟临床场景中的推理过程和能力。
AI在临床实践中的核心挑战
近年来,多模态大语言模型(MLLM)在通用视觉语言任务上取得了显著进展。然而,将这些模型直接应用于临床实践面临着独特的挑战。医疗数据,如放射影像和病理切片,具有极高的复杂性,其特征包括:细微的病理特征、高度的个体间差异、以及诊断决策对上下文信息(如病史、其他检查结果)的强依赖性。直接应用通用模型,可能因无法准确捕捉这些细微差别而导致错误的理解或产生具有潜在风险的信息幻觉。
现有专用的医疗MLLM在一定程度上缓解了这些问题,但仍普遍存在几个瓶颈:
-
• 知识覆盖范围有限: 多数模型主要依赖影像-文本对进行训练,这好比一位只通过阅片学习的放射科医生,缺乏对药理学、遗传学、临床指南等更广泛医学知识体系的整合。 -
• 数据质量与幻觉风险: 数据构建过程,特别是依赖大模型蒸馏生成样本时,若缺乏有效的质量控制,易引入噪声和事实性错误,直接影响模型的临床可靠性。 -
• 复杂临床推理能力不足: 真实的临床决策并非简单的模式识别,而是一个涉及鉴别诊断、多步骤推理和不确定性管理的复杂过程,现有模型在此方面能力尚显不足。
为系统性地应对上述挑战,“灵枢”(Lingshu)模型被提出,其设计哲学贯穿了数据构建、模型训练和评估的全过程。
核心方法论:临床导向的数据工程
“灵枢”的性能根基在于一套精细且全面的数据工程体系。该体系的核心思想是:一个强大的医疗AI不仅需要专业的医学知识,还需要稳固的通用世界知识作为支撑,以理解复杂的图表、文本和指令。
构建跨领域的知识库
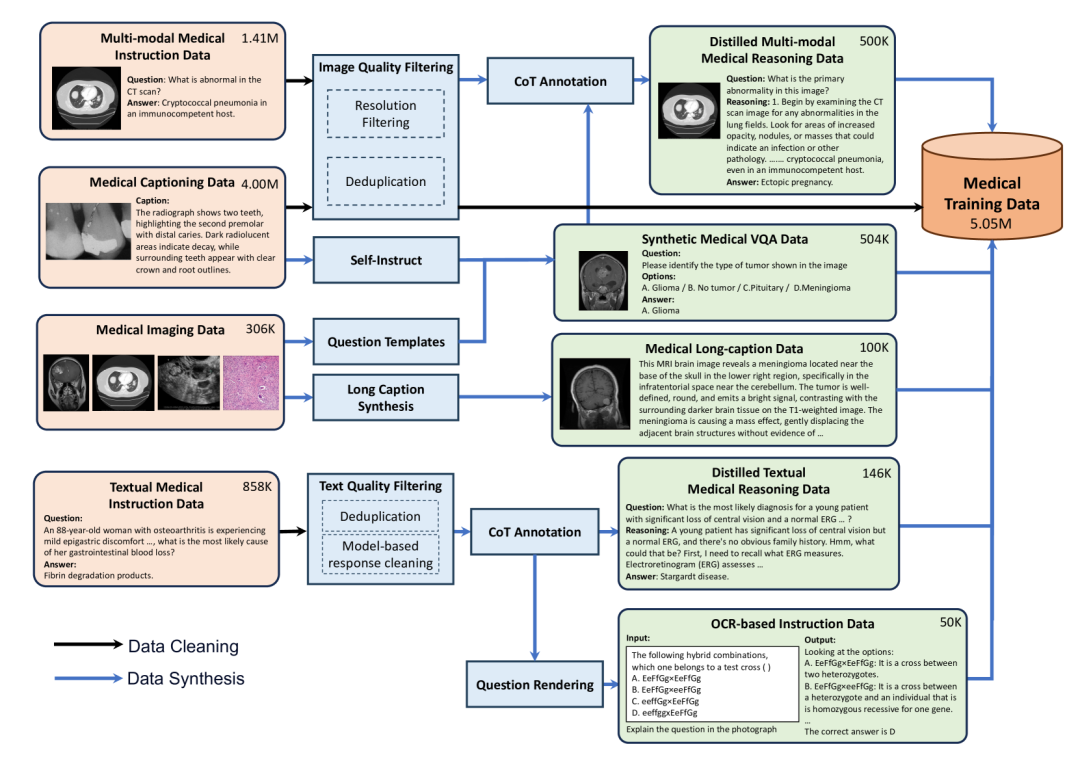
“灵枢”的训练数据由三部分构成,总计包含375万经过处理的开源样本和130万合成样本。
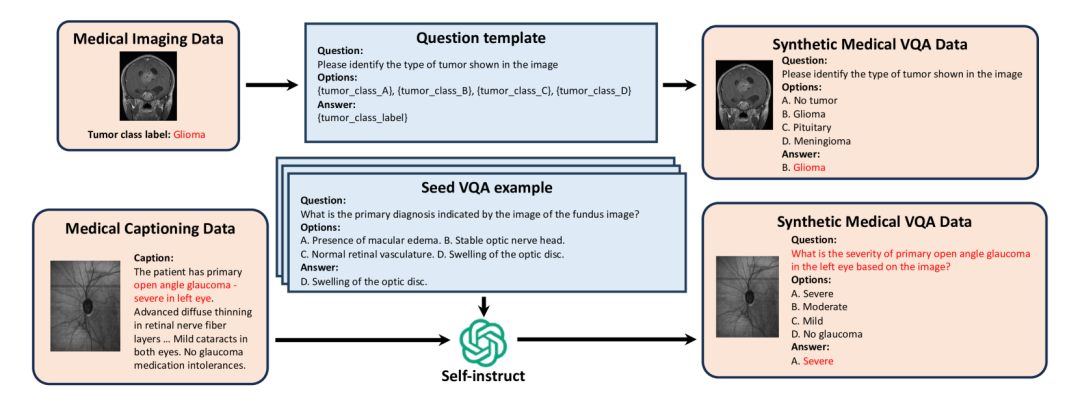
在数据收集阶段,团队广泛整合了医学多模态数据(如MIMIC-CXR、PathVQA等)、医学单模态数据(如MedQA考试题库和覆盖超过12种模态的纯医学影像)以及通用领域数据(如LLaVA-1.5、OpenHermes-2.5)。这种跨界融合的策略,旨在让模型既能深耕医学专业,又能理解现代医学报告中常见的统计图和化验单。
为确保数据质量,团队实施了严格的清洗流程。对图像,应用感知哈希算法以汉明距离为0的严格标准进行精确去重;对文本,则使用LLaMA-3.1-70B模型自动化移除隐私信息和不合规建议,并采用min-hash LSH(局部敏感哈希)进行跨数据集去重。
模拟临床专家的“教材”编写
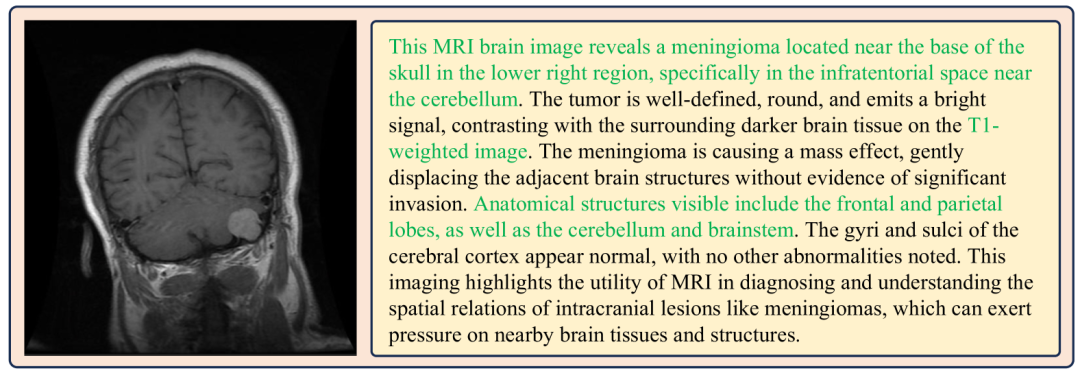
针对现有开源数据描述简短、任务单一的问题,“灵枢”设计了多种数据合成策略。其中最核心的是一个模拟临床专家报告撰写的五阶段长文本描述合成流程:
-
1. 元数据准备: 提取图像自带的元数据,并结合外部知识库的医学知识。 -
2. 兴趣区域(RoI)识别: 利用分割掩码或检测框在图像上标出病灶区域。 -
3. 事实知识标注: 基于元数据和RoI,由GPT-4o生成对客观发现的描述。 -
4. 医生偏好标注: 依据咨询医学专家的意见(例如,在MRI分析中关注T1/T2加权像的信号差异),指导GPT-4o生成符合临床思维的描述。 -
5. 摘要生成: 再次使用GPT-4o融合前序描述,生成最终的、结构化且专业的长文本描述。此流程共计生成约10万份高质量样本。
此外,团队还通过渲染生物化学试题、利用GPT-4o生成思维链(CoT)等方式,合成了大量用于提升OCR、VQA和临床逻辑推理能力的数据。
模型架构与多阶段训练范式
“灵枢”基于Qwen2.5-VL-Instruct(7B和32B两种规模)进行构建,其架构包含一个大语言模型(LLM)、一个视觉编码器和一个基于MLP的投影器。训练过程被设计成一个模拟医学教育的“渐进式”范式,从基础认知到临床实践。
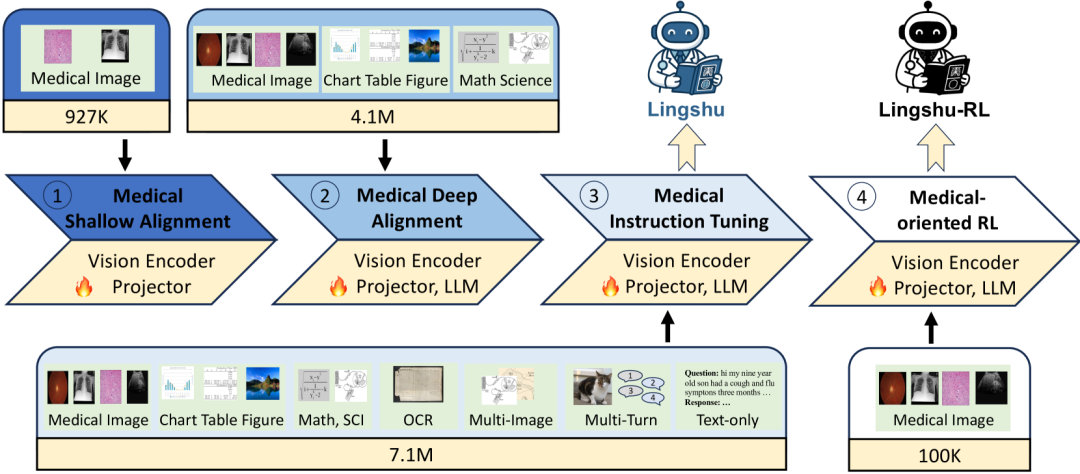
模拟医学教育的渐进式训练
-
• 第一阶段:医学浅层对齐 (基础解剖学)
此阶段目标是建立视觉编码器对医疗影像的基础理解。LLM被冻结,仅微调视觉编码器和投影器,训练1个epoch。学习率精细设置为:视觉编码器2e-6,投影器1e-5。 -
• 第二阶段:医学深层对齐 (临床见习)
此阶段旨在将丰富的医学知识与通用视觉知识深度融入整个模型。所有模型参数均被解冻,进行端到端微调,训练1个epoch,LLM学习率为1e-5。 -
• 第三阶段:医学指令微调 (住院医师培训)
此阶段目标是提升模型遵循复杂指令和解决多样化临床任务的能力。继续进行全参数微调,训练2个epoch,数据源扩展为大规模、混合模态的指令数据,模拟复杂的临床病例。 -
• 第四阶段:医学导向的强化学习 (专科进修探索)
这是一个探索性阶段,旨在检验强化学习在提升医疗推理能力上的应用。团队基于Lingshu-7B,使用GRPO算法进行探索。超参数设置为:最大序列长度4096,学习率1e-6,KL散度损失系数1e-3,每个提示采样16个响应。
MedEvalKit:构建标准化的医疗AI评测体系
为解决医疗AI领域评测标准不一的问题,“灵枢”项目同步推出了开源、统一的评测框架——MedEvalKit。它整合了16个广为认可的医学评测基准,如VQA-RAD (放射学), SLAKE (多语言、多模态), PathVQA (病理学), MedQA-USMLE (美国执业医师资格考试), MIMIC-CXR (胸片报告)等。
在评估方面,MedEvalKit针对不同任务采用不同策略:对开放式问答,使用GPT-4.1作为裁判进行评估;对报告生成任务,则采用多维度指标,包括更具临床意义的SembScore(基于CheXbert提取的14种胸部病理征象的向量相似度)和RadGraph-F1(量化临床实体和关系的重叠度)。

实验结果与临床案例分析
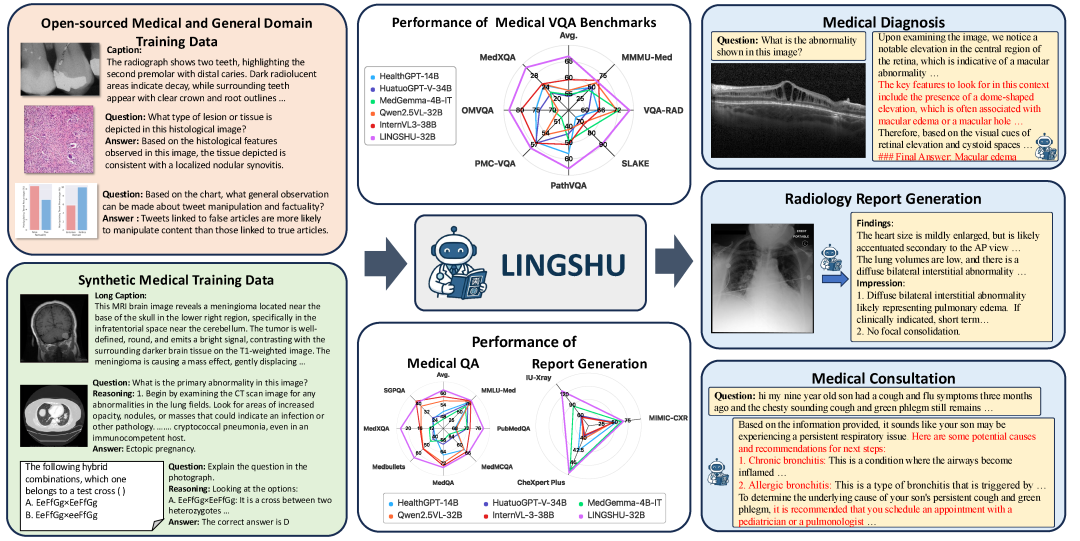
在MedEvalKit的严格评估下,Lingshu-32B在7个多模态VQA基准上的平均准确率达到66.6%,高于所有对比的开源模型及部分闭源模型。然而,评测指标只是故事的一部分,模型在模拟临床场景中的具体表现,更能揭示其真正的潜力。
眼科OCT图像的鉴别诊断
-
• 临床场景: 一张眼底OCT图像显示黄斑区异常。 -
• 模型输出与医学解读: Lingshu准确识别出“穹顶状视网膜隆起”、“视网膜内囊样间隙”(intraretinal cystic spaces)和“视网膜下积液”(subretinal fluid)。这些是黄斑囊样水肿(cystoid macular edema)的典型影像学表现。模型进一步排除了黄斑裂孔(macular hole),后者表现为视网膜神经上皮层的全层缺失。这个过程展示了模型进行临床鉴别诊断的潜力。

胸部X光报告的生成与解读
-
• 临床场景: 一张正位胸片。 -
• 模型输出与医学解读: 模型生成的报告在“Findings”(影像所见)部分指出了“心脏轮廓增大”(enlarged cardiac silhouette,提示心脏扩大/cardiomegaly)和“肺间质纹理增多”(increased interstitial markings,提示肺血管充血/pulmonary vascular congestion)。在“Impression”(诊断印象)部分,它综合这些发现,并给出了“建议利尿剂治疗后复查X光片”的临床建议。这一系列输出高度模拟了放射科医生的工作流程:从影像学征象到临床诊断(通常与充血性心力衰竭相关),再到提出符合治疗逻辑的下一步措施。

分子生物学知识的解释
-
• 场景: 一张展示神经突触传递过程的示意图。 -
• 模型输出与医学解读: Lingshu不仅描述了神经递质从囊泡中释放、穿过突触间隙并与受体结合的基本过程,还基于图中递质的化学结构,准确地将其识别为“去甲肾上腺素能突触”。这表明模型具备了在亚细胞、分子层面理解和分类生物学过程的能力。

模拟初级诊疗(Triage)
-
• 场景: 患者通过文本主诉“胃部不适”。 -
• 模型输出与医学解读: 模型能够理解患者的自然语言描述,提出“胃炎”或“消化性溃疡”等可能的鉴别诊断,建议就诊于“消化内科”,并推荐进行“胃镜”等相关检查。这模拟了初级保健医生或分诊护士的临床决策过程。

结论与未来展望
“灵枢”项目通过一套系统性的方法,在数据构建、模型训练和标准化评测方面进行了深入的探索和实践,成功地构建了一个在多个医疗任务上表现出色的通用基础模型。
研究团队同样指出了模型的局限性,包括对更高质量数据的需求、在某些超复杂推理任务上与顶级闭源模型的差距,以及强化学习应用的初步性。未来的工作将围绕以下方向展开:
-
1. 模型扩展: 探索原生支持3D影像(对放射科的容积分析至关重要)和全切片病理(WSI)的模型架构。 -
2. 后训练技术: 深入研究更适用于医疗知识驱动型推理的后训练技术,例如,开发能够评估临床决策路径合理性的奖励模型。 -
3. 智能体应用: 基于“灵枢”开发能够与电子病历(EHR)系统、医学知识库等外部工具交互的任务导向型智能体系统。
推荐阅读
-
• 论文原文: https://arxiv.org/pdf/2506.07044 -
• 项目主页与模型下载: https://alibaba-damo-academy.github.io/lingshu/ -
• 评测框架: https://github.com/alibaba-damo-academy/MedEvalKit
(文:子非AI)