


在多模态大模型的性能竞赛中,Post-training 正逐渐成为真正拉开差距的关键阶段。架构趋同之下,MiMo-VL 与 Seed-VL 两大系统在后训练链条上的策略博弈,展现了当前业界对指令对齐、强化学习与奖励建模的多种探索路径。
本文围绕 SFT、RLHF、奖励模型范式等核心模块,系统对比两者在数据构造、训练目标、优化技巧等方面的具体实现,梳理其在构建大规模多模态能力过程中各自的技术落点与思路差异,助你洞察下一代多模态模型的后训练演进趋势。

模型架构
基本主流的框架在架构上基本没有太大差别,ViT+MLP adater+LLM,主要的差别集中在两点:
1. 要不要使用自己训练的 ViT,MiMo-VL 使用了 Qwen2.5-ViT,而 Seed 使用了自己的 Seed-ViT。
2. adapter 之后要不要 pooling 或者 pixel shuffle,Qwen2 及之后的工作基本没有考虑 pooling,InternVL 一系列的工作 pixel shuffle 居多。
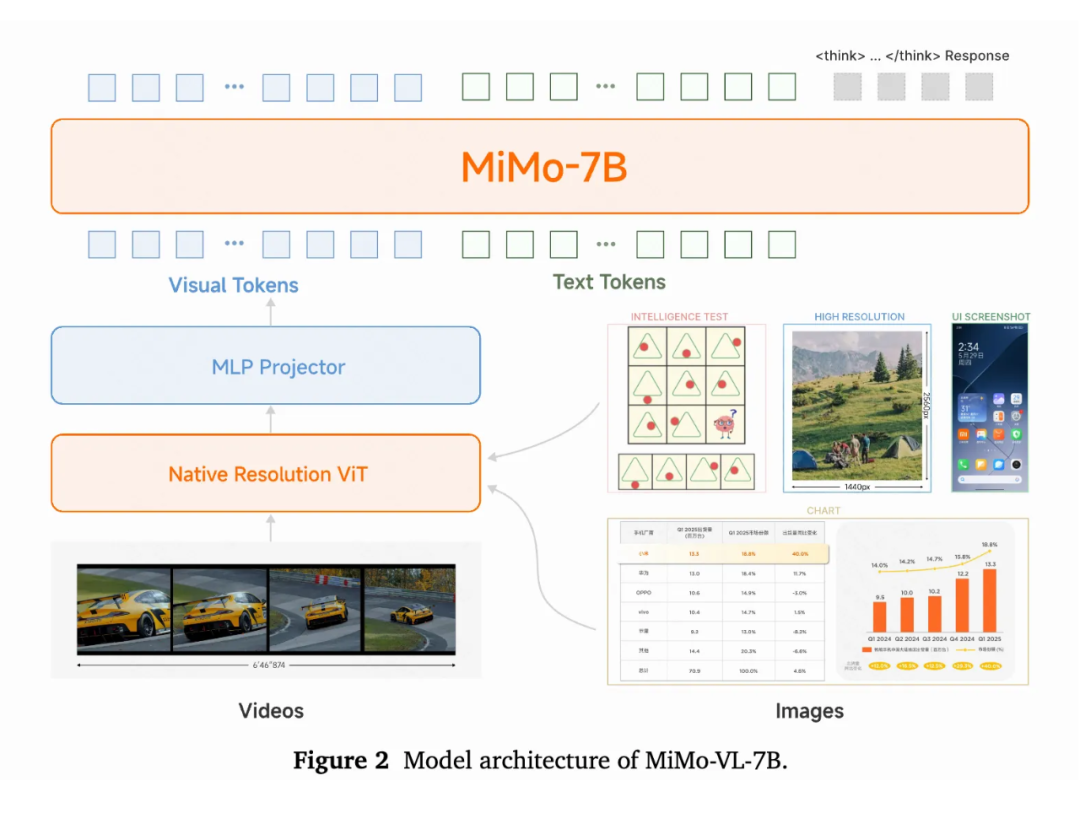
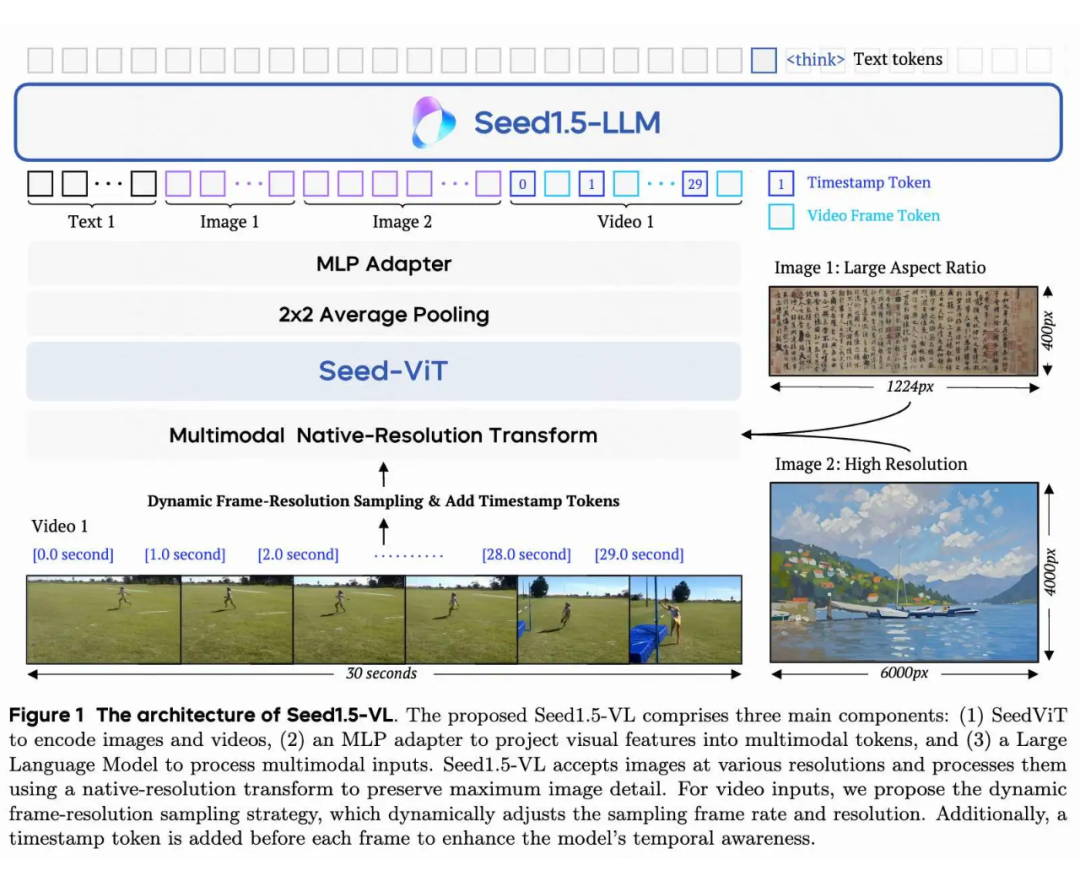

数据和训练策略
数据和策略的差别各家都很大:
Pretrain 阶段,M 使用了 2.4 trillion,分成四个阶段,涉及到的过滤 trick 可以拿出一页单讲。
## 图像数据
使用感知哈希技术去重,筛选高质量图像,通过专门模型重新生成描述,并构建中英双语元数据以优化描述分布。
## 图文交错数据
对文本、视频及其相关性进行综合评估和过滤。
## 视频数据
添加精确时间戳实现时间定位,平衡事件时长分布用于时间定位预训练,策划分析性段落增强模型对视频的深入理解。
## OCR数据
包含多样化文本内容,增加手写和变形文本提高识别难度,添加边界框标注使模型能同时预测文本位置。
## 定位数据
使用复杂对象表达式提升模型理解能力,采用绝对坐标表示确保定位准确性。
## GUI数据
收集各平台开源GUI数据,设计合成数据引擎弥补局限,分别收集元素定位和指令定位数据,统一不同平台的动作空间。
## 合成推理数据
策划多种问答任务的开源问题,实施多阶段质量控制,通过高保真数据集增强模型在多模态环境中的推理能力。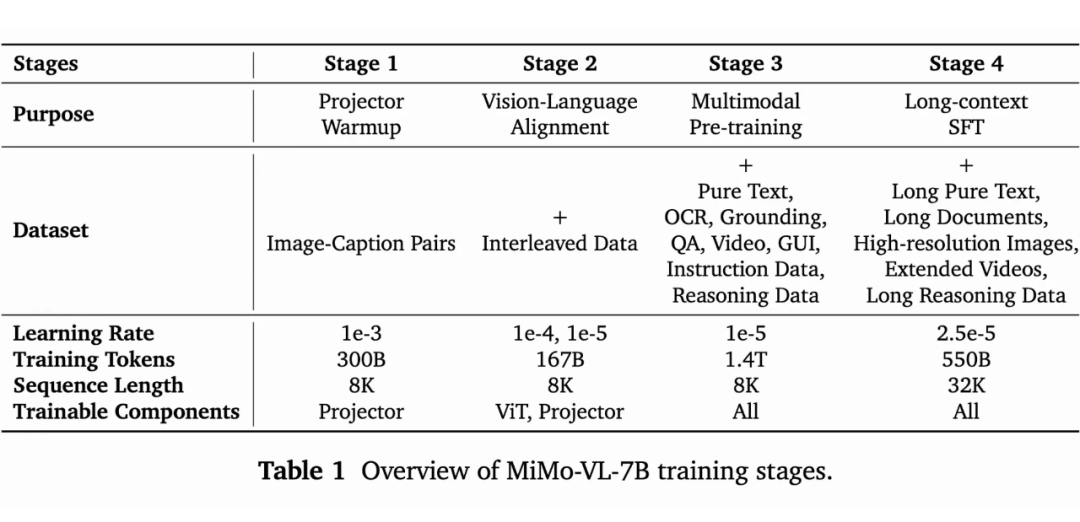
Seed 的 corpus 达到了 3 trillion,涉及到的 trick 更多,相比于 M 而言,点计数,3D 任务,科学工程似乎有着不错的占比,更加全面。训练策略有些微的差别,除了第一个 stafe 开放 MLP,剩下的 stage 全开。
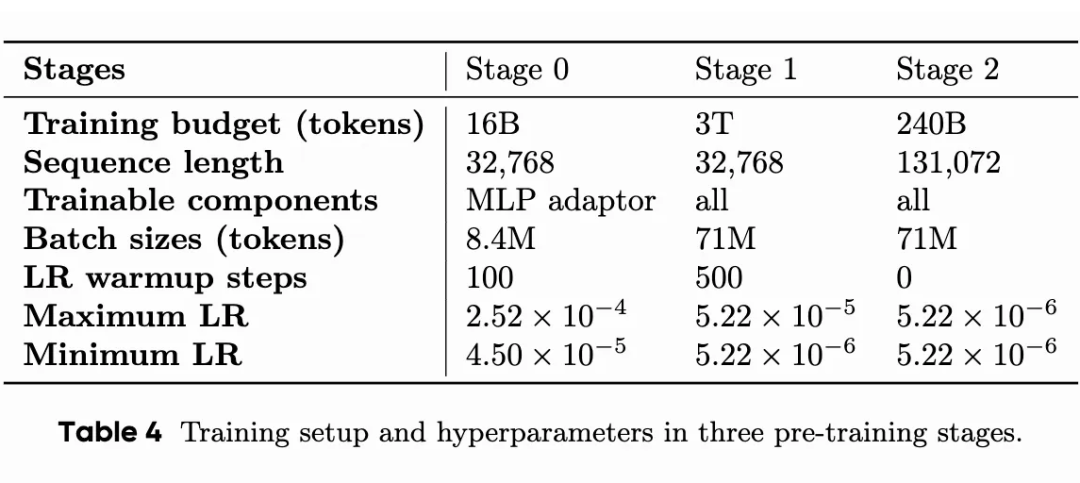
### 通用图文对与知识数据
通用图文对数据规模巨大但存在噪声和类别不平衡问题,为此采用了多种过滤技术,包括相似度评分、图像/文本标准过滤和去重。针对长尾分布问题,通过实验发现限制常见物种样本数量能显著提升稀有物种识别性能。最终,通过使用VLM自动标注语义领域和命名实体,并对低频领域进行数据复制,实现了视觉概念的平衡分布,以增强视觉知识的学习。
### OCR 数据
构建了包含文档、场景文本、表格和流程图的亿级内部OCR训练数据集。该数据集通过收集真实页面、合成文本密集图像(包含多种字体和形变)、以及利用LLM生成合成图表和表格图像来丰富。此外,还构建了VQA数据集,通过VLM生成问答对并进行过滤,以增强模型对图像中文本信息的理解。
### 视觉定位与计数
视觉定位与计数能力主要通过边界框、点注释和计数数据进行训练。边界框数据来源于过滤后的开源数据集和大规模自动标注的web图像,涵盖了通用2D定位、空间关系问答和视觉提示问答等任务。点数据在现有基础上通过Molmo和CountGD流水线扩充,尤其擅长密集场景中的对象注释。计数数据则从边界框和点数据中采样生成。所有坐标值都进行了归一化处理,以确保模型在不同分辨率下的预测准确性。
### 3D空间理解
构建了针对相对深度排序、绝对深度估计和3D定位三类任务的数据。相对深度排序数据通过DepthAnything V2从互联网图像中推断得到;绝对深度估计数据来源于公共数据集,通过语义掩码确定实体绝对深度;3D定位数据则将公共数据集重构为提问对象3D位置的问答对,共同训练模型对3D空间的感知和理解。
### 视频数据
主要包括通用视频理解数据(视频字幕、问答、动作识别和定位)、视频时间定位与时刻检索数据(提升时间感知),以及视频流数据。视频流数据进一步细分为交错式字幕/问答数据(实时理解)、主动推理数据(持续监控和主动响应),以及实时评论数据(细粒度交错和实时更新),共同为视频训练打下全面基础。
### 科学、技术、工程和数学 (STEM) 数据
STEM数据通过抓取和手动标注方式收集,并分为图像理解数据和问题解决数据两大部分。图像理解数据包含教育定位样本、结构化表格、化学结构图和坐标系图,以及K12教育图像的人工和机器生成字幕、VQA对等。问题解决数据则涵盖了K12级别的习题、中文成人教育问题和英文图像相关问题。这些数据采用混合获取策略,确保了多模态覆盖和高质量。
### 图形用户界面 (GUI) 数据
GUI数据主要来自UI-TARS,旨在支持模型对GUI的鲁棒感知、定位和推理。数据集包含来自web、应用和桌面环境的屏幕截图,并配有结构化元数据(元素类型、边界框、文本和深度)。训练任务包括元素描述、密集字幕和状态转换字幕,以识别UI组件、理解布局和检测视觉变化。定位任务训练模型根据文本描述预测元素坐标。推理任务则收集多步骤任务轨迹,包括观察、中间思考和动作,使模型能够学习分步规划和反思。

Post-training 训练数据
大概可以分为 RLHF(奖励模型训练)以及 RL 两个阶段。
M 在两个阶段的数据源和数据量都不清楚,不过提到了平衡了中文和英文查询的比例,以及针对有用性和无害性的查询比例。
奖励模型的训练数据是每个 query 用 MiMo-VL-7B 和其他多个 MLLM 生成 response,然后使用另一个 MLLM 来进行排序打分,最终形成了一个 pairwise 的数据集用于奖励模型的训练。
这种多样性和数据集构造过程与我们的前期工作 mm-rlhf 类似,但是显然 M 团队选择了更容易 scale up 的 pipeline。RL阶段将混合的 reasoning,perception,定位,文本很多领域的数据一起扔进去。
S 的内容更丰富一些,RLHF 阶段基本采用了跟我们 MM—RLHF 数据 pipeline 一样的流程,单个 query 采样多个 response,5 级评分系统人工标注,不过他们会用 reward model 预打分提高效率,可以降低 scaling up 的成本。
除此之外还有一组合成数据,带有明确的 ground truth,知识考虑如何生成负样本,这种操作在 mllm alignment 也很常见了(mpo,rlaif-v 等都是),ranking 非常明确,快速扩充数据量。
RL 的数据是从偏好数据拿出来的,同样的,观察到了 prompt 分布的覆盖范围对 RL 性能有关键影响,为了让训练数据更 balance,S 又来了一个小 trick:
1. 训练一个标签模型为 query 打标签;
2. 通过分层抽样确保不同能力类别之间的平衡;
3. 使用最先进的内部模型生成 K 个回答,根据 reward 的方差应用过滤标准:如果K个回答的最大奖励和平均奖励之间的差异低于预定义的阈值,则排除这些提示。这一步确保了保留那些奖励模型具有显著区分能力的 query;
4. 在 RL 训练的初期,对那些奖励和 KL 散度同时快速增加(表明任务难度较低)的 query 进行了降采样。

Post-training 奖励模型
M 采用了两个奖励模型,都是传统奖励模型,分别处理文本和多模态。
S 的奖励模型选择了 generative reward model(经过了相应的 sft)。输入问题,response 1,response 2,直接给出排序,核心观察是这种方法比传统的 Bradley-Terry 奖励建模更稳健、更优越,因为它直接处理 token 概率和回答比较。这个思路和 R1-reward 非常类似,因此我可以有一些扩展的猜测:
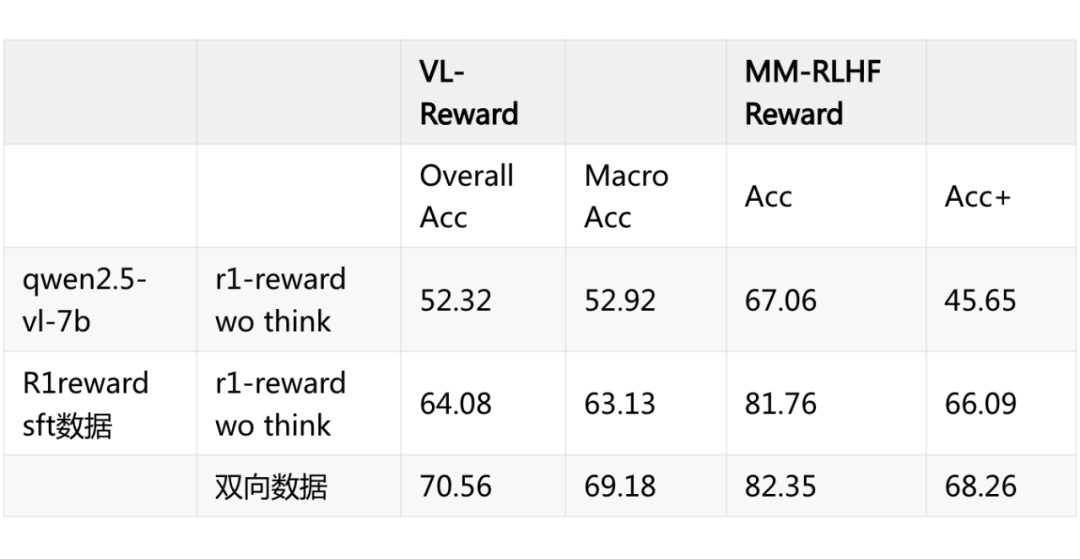
1. 首先 SFT 非常重要,为了验证这个 facotr 我做了一组小实验, 第一行直接用 qwen2.5 vl 写个 prompt 完成上述功能,第二行用 r1-reward 的训练数据(类似 seed 这种格式,从 mm-rlhf 等多个数据集构造的)sft 一轮,效果提升非常显著。
从而引发的还有一个 小 trick,我把每组数据 chosen rejected 换个方向作为输入,效果还能再次提升。70.56 已经基本上接近目前的 sota r1-reward 的效果了。
2. 很容易想到的,这种范式非常适合做强化学习训练进一步提升,也就是先 think 再给出 answer,r1-reward 的性能增益也许就来自这方面,但是二者之间的差距看起来并没有那么大,而且会引入额外的计算开销。

Post-training 训练目标
M 的训练目标直接使用了 GRPO 没有其他改进,但,在训练过程中提出了 Reward-as-a-Service 的概念,让一个 router 根据任务类型自己判断选择哪个 reward function,不过不知道具体是怎么实现的。
类似于 M,S 也采用了 rule base+reward model base 混合训练的策略:
1. STEM(科学、技术、工程和数学)主要使用 rule based reward,其实主要也是数学问题。不过有两个 tric,移除 choice 防止模型随机猜测,然后每个问题生成 16 个回答,丢弃那些 SFT 模型准确率为 0% 或超过 75% 的问题。这种过滤隔离了适合 RLVR 探索的具有挑战性的 query;
2. 除此之外,还混了一些定位,指令遵循,迷宫,互动游戏的样本。
混合强化学习的目标,PPO 的变体(很难评,因为不知道他是说混合 reward 还是训练目标本身变了),奖励函数分为了 format,hybrid reward(RM 忽略了 CoT thought 只关注 solution),critic model 还是存在(看来没用 grpo)。
同时还加入一个小 trick,每个 query 的 rollouts 数量不同,较难的 query 需要更全面的探索。对于由奖励模型奖励的每个提示,仅采样一次,而对于由验证器奖励的提示采样 4-8 次。
那么随之而来的我们会发现,他没有经过 long-cot 的 sft,所以 S 采取了另一个策略来弥补这个阶段能带来的性能增益,毕竟更强的冷启动 SFT 自然会导致 LongCoT RL 后的模型更强。 简单说经过了四轮 SFT+RL,对每轮产出的 RL model
1. 每一轮通过他们的数据生成 pipeline 收集额外的 query;
2. 通过拒绝采样将能够正确回答的样本(为啥是正确而不像上面一样给个难度的 threshold 比如 passk 尚未可知);
3. 人工去除 overthinking,repetition,以及语言上的缺陷。
然后 sft,rl 不断迭代。

结语
从长期来看,基于规则(rule-based)的训练策略在多模态场景下难以单独支撑复杂任务的泛化能力,奖励模型的设计与应用正逐步成为后训练阶段的核心关键。只有构建出足够稳健且可扩展的奖励建模机制,才能真正支撑多模态模型对多样化问题类型的适配与耦合(ORM coupling)。
目前来看,Post-training 阶段仍存在大量值得深入探索的问题——如何进行合理的数据配比?多轮 RL 的最优调度如何实现?哪些训练策略能够在性能与效率间取得更优折中?这些问题都需要通过大规模验证与系统性对比来不断迭代。
Seed-VL 的实践引入了大量 human expert 的参与,并在流程设计上融合了多层次的优化思路,这也为未来的框架设计提供了可借鉴的方向。
(文:PaperWeekly)