

之前给大家推荐过OmniGen v1,最近几天刚升级了OmniGen2。
OmniGen2针对文本和图像模态分别构建了独立的解码路径,运用未共享参数,搭配解耦的图像分词器。
说人话,
-
OmniGen2的架构升级让文本与图像在生成过程中能更高效、精准地被处理,文本解码路径可依据文本提示,精细把控图像内容走向,图像解码路径则专注于图像特征,保障生成图像的质量与风格。
-
新架构避免了参数相互干扰,显著提升模型对复杂任务的处理能力,在图像编辑、主题驱动生成等任务上表现更出色 。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
OmniGen2 是一个强大的开源统一多模态图像生成模型。它能实现文本到图像生成,依文本提示产出高保真图像;支持指令引导图像编辑,精准完成复杂图像修改;还可处理多种输入,生成新颖连贯视觉输出。相比 OmniGen v1,架构升级,设独立解码路径与未共享参数。在图像编辑等方面表现出色,显著提升用户图像创作体验 。
DEMO
图像编辑功能
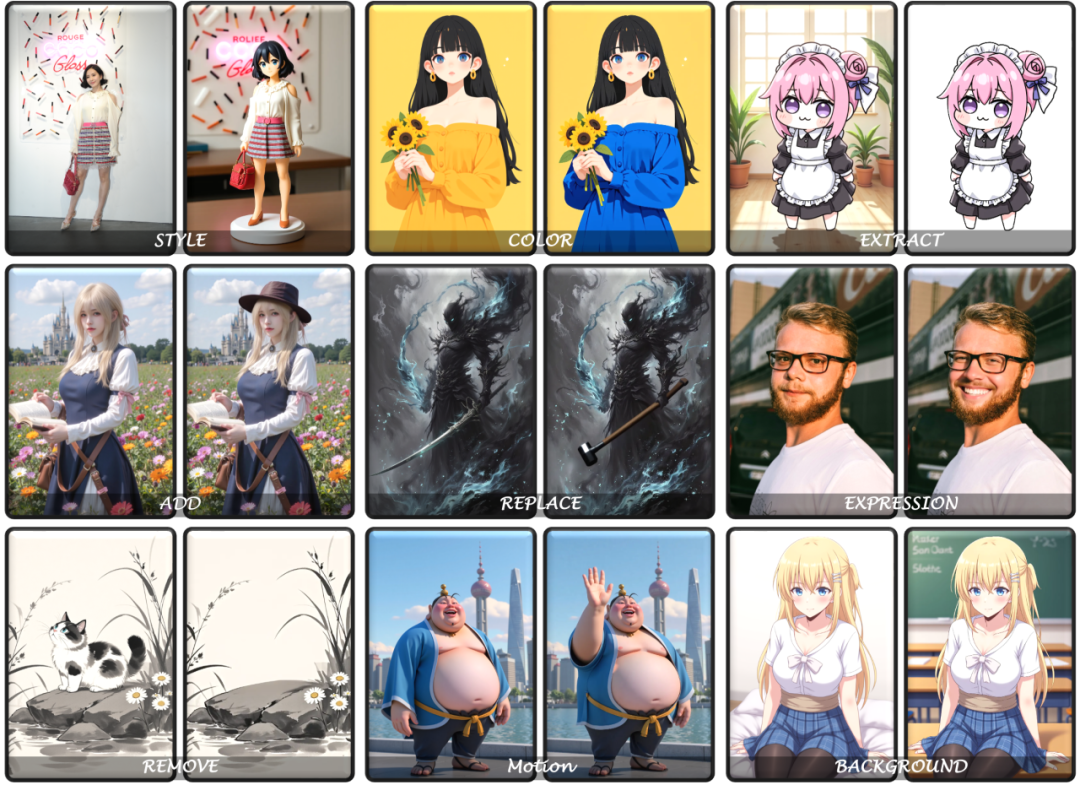
上下文生成功能

整体生成功能演示

技术特点
任务统一性:可实现文本到图像生成,还支持图像编辑、主题驱动生成、视觉条件生成等多种下游任务,能通过指令端到端完成复杂任务,无需额外中间步骤。
多模态输入:支持文本和图像的自由形式交错输入,通过 VAE 将图像转换为嵌入向量,与文本标记共同作为条件指导生成。
知识迁移能力:通过统一格式训练,可在不同任务和领域间有效迁移知识,处理未见过的任务并展现新能力。
推理加速:利用 kv-cache 存储输入条件的键值状态,避免冗余计算,加速推理过程,类似 LLM 的高效生成。
统一数据集 X2I:构建了首个大规模多任务图像生成数据集,覆盖文本到图像、多模态生成、计算机视觉等任务,统一为交错文本 – 图像序列格式。
加权损失训练:在图像编辑任务中,通过放大修改区域的损失权重,避免模型直接复制输入图像,引导聚焦修改区域。
渐进式分辨率训练:训练过程中逐步提高图像分辨率。
项目链接
https://github.com/VectorSpaceLab/OmniGen2
关注「开源AI项目落地」公众号
(文:开源AI项目落地)