

极市导读
上海交通大学、腾讯优图、浙江大学联合推出 IAR 方法,通过码本重排策略和面向簇的交叉熵损失,提升自回归视觉生成模型训练效率高达 42%,生成质量更优,且能适配多种模型,为自回归视觉生成开辟新路径。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://openaccess.thecvf.com/content/CVPR2025/papers/Hu_Improving_Autoregressive_Visual_Generation_with_Cluster-Oriented_Token_Prediction_CVPR_2025_paper.pdf
项目链接:https://sjtuplayer.github.io/projects/IAR/
Git链接:https://github.com/sjtuplayer/IAR
单位:上海交通大学、腾讯优图、浙江大学
1.引言
使用自回归进行视觉生成最近已成为一个研究重点。然而,现有的方法主要是将自回归架构转移到视觉生成中,但很少研究语言和视觉之间的根本差异。这种疏忽可能导致自回归框架内视觉生成能力的次优利用。在本文中,作者探讨了自回归框架下视觉特征空间的特点,发现视觉编码之间的相关性可以帮助实现更稳定和更鲁棒的生成结果。为此,上海交通大学数字媒体与计算机视觉实验室,联合腾讯优图和浙江大学,提出了IAR,一种改进的自回归视觉生成方法,提高了基于自回归的视觉生成模型的训练效率和生成质量。
(1) Codebook重排策略,该策略使用平衡的k-means聚类算法将视觉码本重新排列成簇,确保每个簇内视觉特征之间的高度相似性。
(2) 面向簇的交叉熵损失,引导模型正确预测目标Token所在的簇。结合Codebook重排列,可以确保即使模型预测错误的Token索引,预测的错误Token位于正确的簇中的概率也很高,从而保证生成图像与目标图像的相似性。
IAR显著提高了生成质量和稳健性。IAR可以直接应用到现有的自回归视觉生成框架中,在LLamaGen和VAR上,能够稳定提升训练效率和效果,最大提升42%的训练效率。
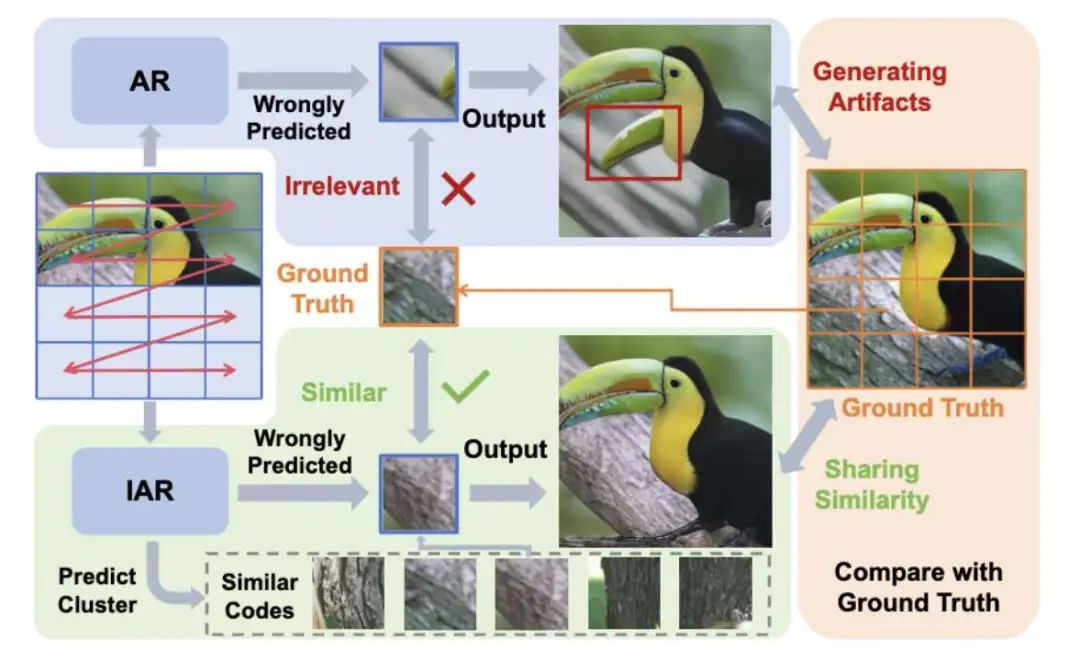
2.图像与自然语言之间的连续性差异
近年来,生成模型在图像和视频生成领域取得了显著突破,随着多模态研究的兴起,图像与文本的融合成为了一个重要方向。研究人员希望开发一种统一的多模态模型,能够同时理解和生成图像与文本内容。基于此,将图像生成技术与大型语言模型(LLM)结合逐渐成为热点。
传统图像生成方法如 GAN 和扩散模型,主要在连续空间中建模图像分布,而自回归方法则选择先将图像离散化为Token,再通过语言模型的方式进行预测。这些方法借鉴了自然语言处理中的经验,比如自回归模型采用 GPT 的“Next-Token预测”策略。
然而,图像与文本在本质上存在重要区别:文本是离散的,可以直接通过查找表将词语映射到索引;而图像是连续的,需要通过编码器将其转化为离散的Token,再通过码本(codebook)检索对应的编码,最终解码为图像。这种差异启发了图像生成可以考虑利用视觉特征空间中的连续性和相关性,而不仅仅是预测单一的Token索引。
由于图像编码位于连续的特征空间中,相似的编码通常对应于内容相近的图像。这是否意味着,即使模型预测的Token略有偏差,只要其对应的编码足够相似,生成的图像质量也不会受到太大影响。
3.图像编码的相似性
作者发现,在码本(codebook)中相近距离的编码表示相似的图像信息。当距离(code distance)较小时,解码出的图像与目标图像在感知质量上几乎一致。作者在VQGAN上验证了这一想法。
具体而言,作者使用图像编码器 (VQGAN)提取特征,获得大小为 的特征图,其维度为 ,表示为:
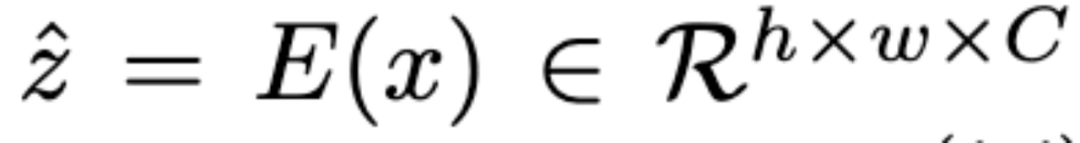
将 中每个位置 的特征查找码本中最近的索引 :
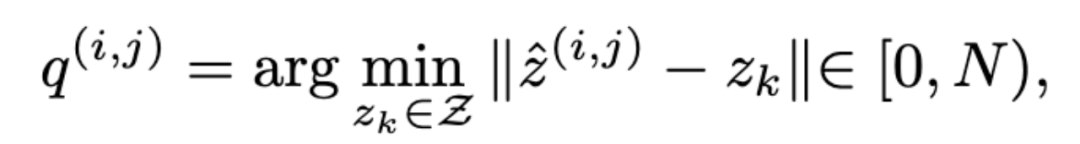
根据索引 ,即可得到量化的特征 .
为了测量码本中两个编码 之间的距离,定义了Code Distance ,即 是 在码本中第近的编码:
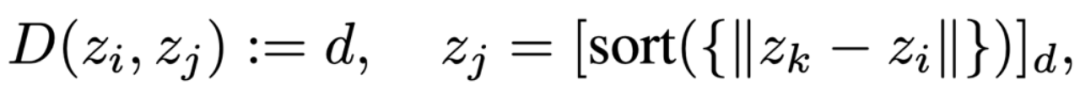
使用 MSE 距离和 LPIPS测量与不同Code Distance的编码对应图像相似性,其中值越低表示图像相似性越高。结果表明,当Code Distance增加时,图像距离也随之增加,说明相似的编码(Code Distance小),在视觉上具有更相近的表现。
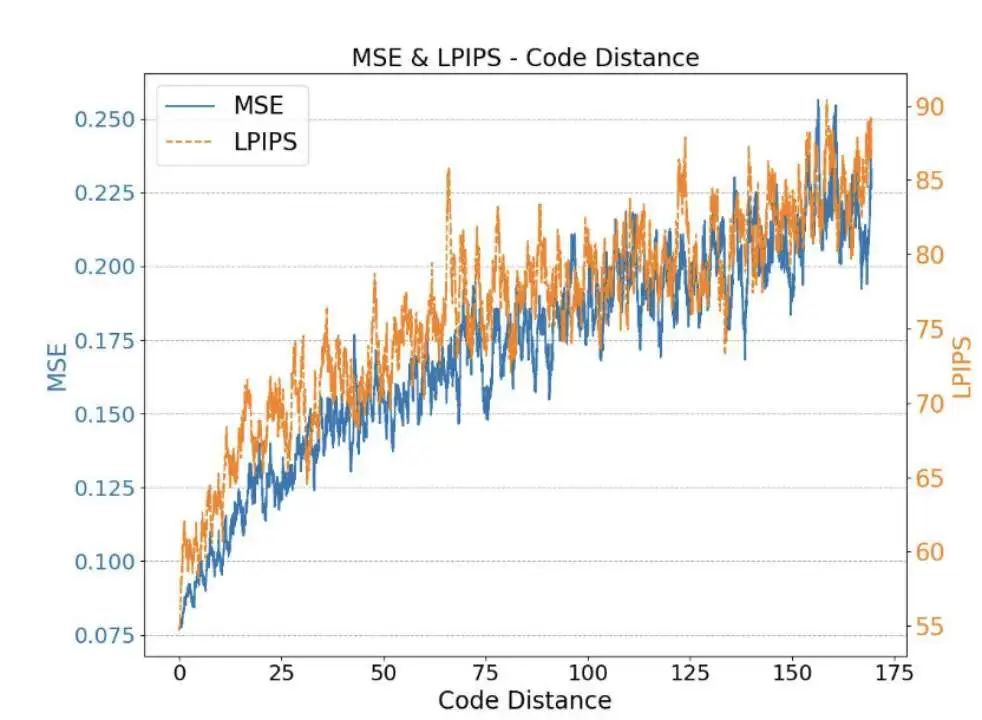
同时,作者进一步可视化了不同Code Distance解码出的图像,当Code Distance较低(例如,小于 12)时,解码出的图像与源图像几乎相同,且具有良好的视觉质量。这表明,即使预测的 token 索引不是准确的目标索引,只要相应编码之间的Code Distance处于一定范围内,解码出的图像仍然与目标图像相似,且具有良好的视觉质量。

4.方法
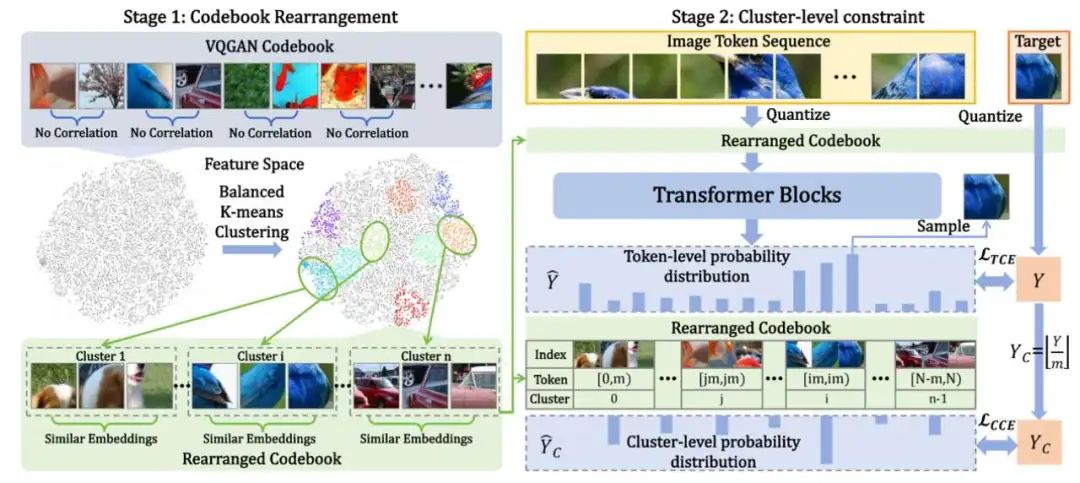
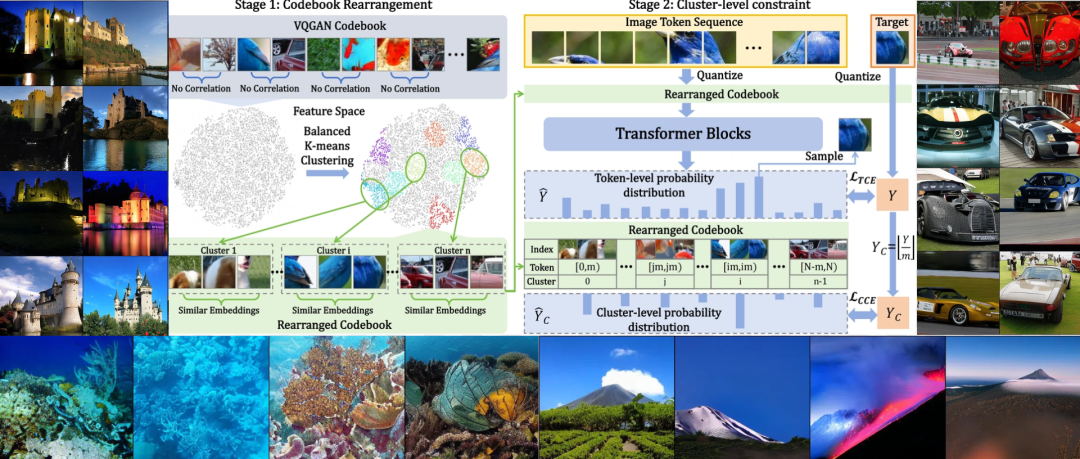
4.1 Codebook重排
作者通过重新排序码本,使相邻编码之间的相似性最大化,从而确保每个编码的周围编码具有高相似性。具体而言,设码本为 ,那么目标是找到一个映射 ,满足:
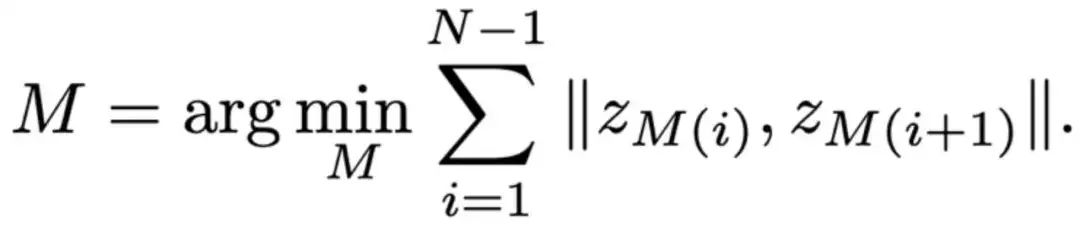
由于这一优化问题属于 NP-Hard问题,因此作者进行了松弛约束,将码本划分为 个簇,每个簇 包含个相似的编码,并将同簇编码排列在一起,使簇 的索引范围为 并设计了一种平衡 K-means 聚类方法对码本编码进行聚类,通过这一算法,可以得到重排后的码本,保证每个簇中的编码都相似。

4.2 面向簇的视觉生成:
在现有的自回归模型中,都是面向Token设计交叉熵损失:
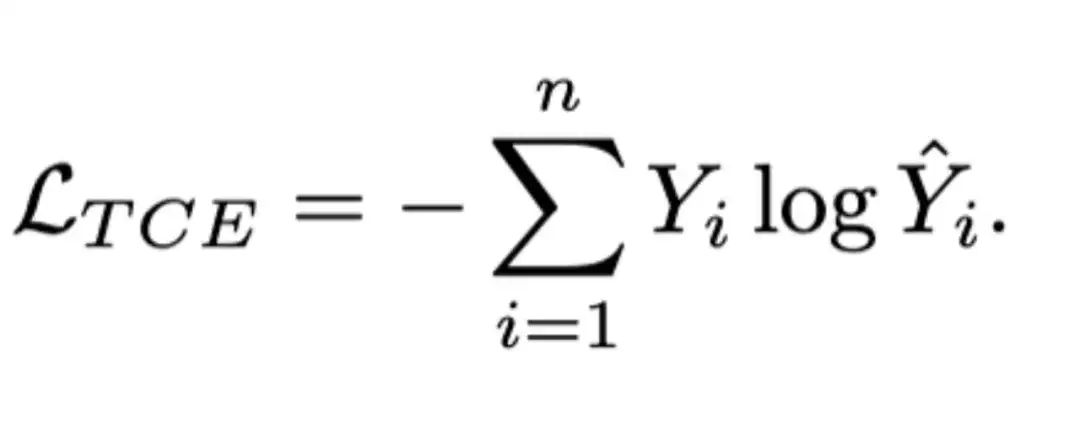
IAR进一步提出面向簇的交叉嫡损失,首先从Token-level的类别标签 y 中通过公式 得到真实簇标签 (其中 是每个簇中的 token 数量);然后,IAR使用以下公式实现从预测的token概率到簇概率的转化,使得在同一簇内,概率较大的token对簇概率的贡献更大:
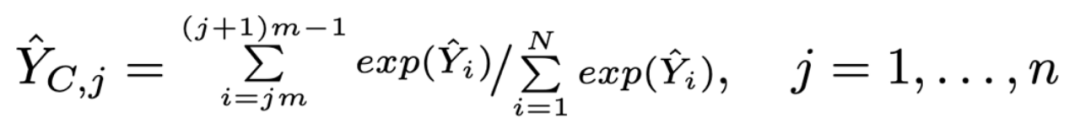
其中 代表生成的token属于簇的概率。
通过真实簇标签 和预测的簇分布概率 ,IAR定义了面相簇的交叉嫡损失 :
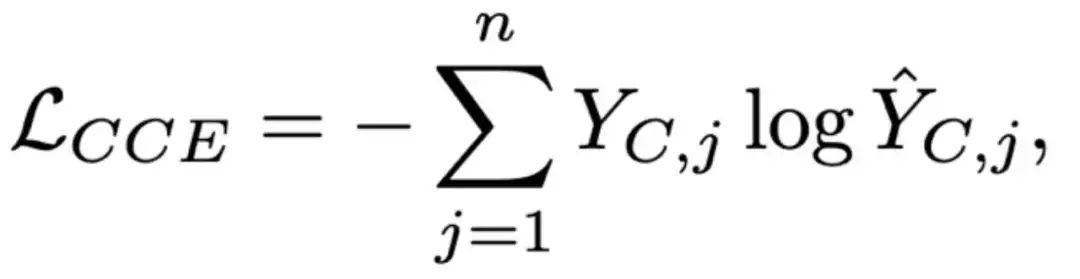
最终的损失函数由基于token的交叉嫡损失 和基于簇的损失 组合而成:
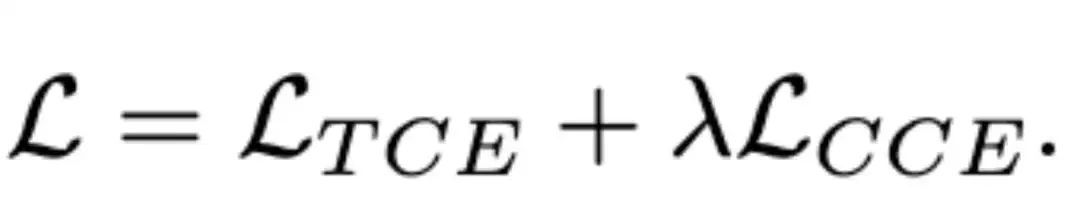
由于簇的数量少,预测簇比直接预测token更简单,同时,只要预测正确了簇的索引,即可保证生成图像不会偏离目标图像,从而极大地促进模型的鲁棒性与生成质量的稳定性。
5.实验结果
5.1 生成质量比较
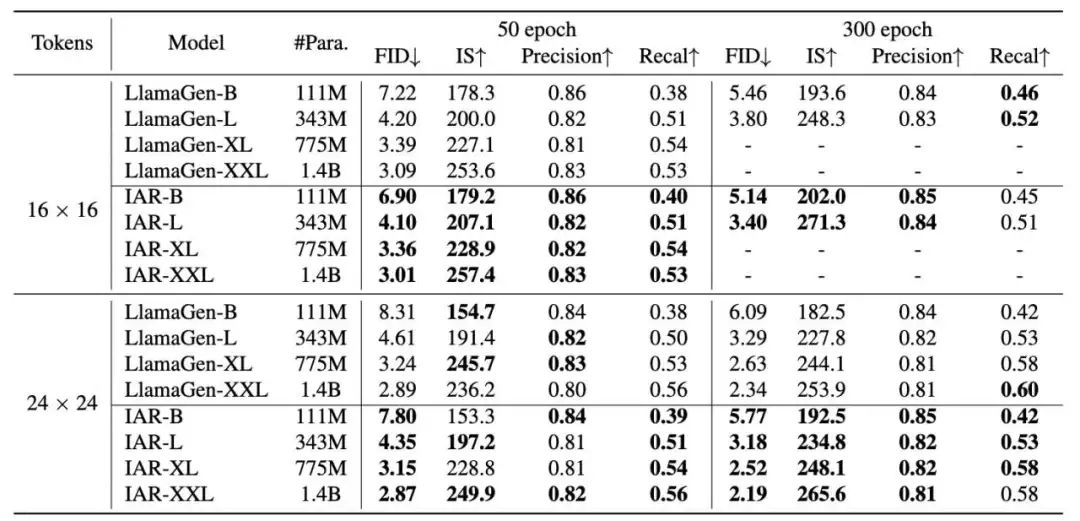
为了评估图片质量,IAR选择 LlamaGen作为基模型,并保持超参数与LlamaGe一致。实验在 ImageNet数据集上进行。实验生成了 50,000 张随机标签的图像,并计算生成数据的FID、IS、精度(Precision)和召回率(Recall)。作者首先比较了不同类型图像生成模型在这些参数上的表现:
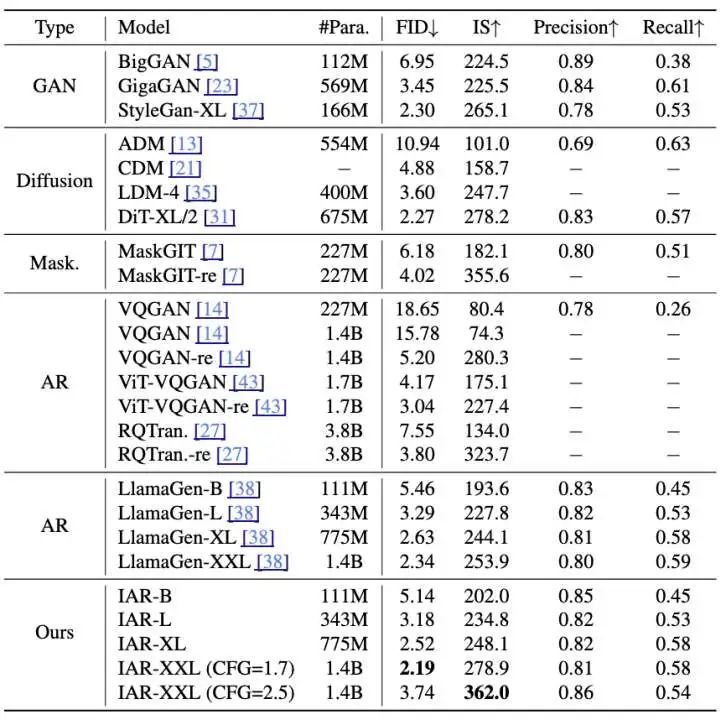
实验结果表明,与 GAN、扩散模型、掩码预测方法和自回归方法等相比,IAR达到了最优的 FID(2.19)和 IS(362.0),并且在不同的参数量下(100M到1.4B),IAR都取得了优于LLamaGen的表现。
5.2 与 LlamaGen 的更多比较:
效果对比:在不同模型参数规模(111M 至 1.4B),图像分辨率(16×16 和 24×24 图像块),训练轮次(50 和 300 轮)条件下,IAR均有着更好的FID和IS,优于基线模型 LLamaGen;
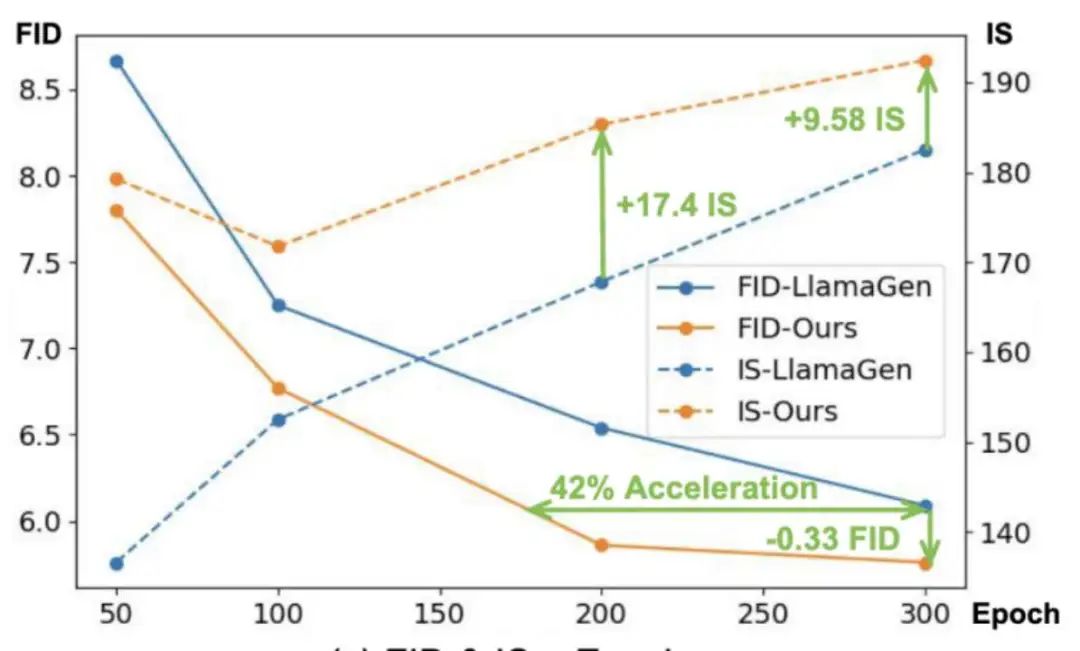
训练效率:在175个epoch时,IAR 模型的FID与 LlamaGen 300个epoch的相当,训练速度提升约 42%。此外,在 300 个 epoch 的训练下,IAR 模型进一步提升了生成质量。
5.3 VAR+IAR
IAR可以用于现有任意的自回归模型中,为了验证在不同自回归模型上的有效性,实验选取了VAR作为基础模型,并进一步将IAR应用于VAR中,实验表明,IAR同样能够有效促进VAR的效果,验证了IAR在不同自回归模型中的有效性。

6.总结
IAR分析了基于 LLM 的视觉生成中自然语言与图像的差异,发现码本中相似的图像编码可生成相似图像。据此提出 IAR,有效提升了训练效率和生成质量。本文通过平衡 K-means 聚类对码本重排,使簇内的编码相似,并引入面向簇的交叉熵损失,引导模型学习目标簇的拟合,从而保证即使预测错误图像 Token ,也能生成高质量图像。实验证明 IAR 可稳定提升 LlamaGen的性能,并适配多种 LLM 视觉生成模型(如VAR等),为该自回归视觉生成提供新方向。
参考文献
[1]. Hu T, Zhang J, Yi R, et al. Improving Autoregressive Visual Generation with Cluster-Oriented Token Prediction[C]//Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
(文:极市干货)