

字节跳动 Seed 团队近期在 arXiv 上发表的论文得到了 ViT 作者,前 Google Brain 最近跳去 OpenAI 的 Lucas Beyer 的亲自解读,Lucas 直言:「这是一篇简洁的论文,不知怎的让我回忆起美好的在 Google Brain 的旧时光。(This is a neat paper that somehow made me reminisce good old Brain times. )」
Seed 团队在这篇论文提出的预训练模型平均(PMA)技术,通过合并训练过程中的检查点(Checkpoint),不仅实现了模型性能的显著提升,还能精准预测学习率衰减阶段的性能表现。这一成果被视为大模型训练领域的重要突破,甚至可能改变未来大模型开发的范式。


-
论文标题:Model Merging in Pre-training of Large Language Models
-
论文地址:https://arxiv.org/pdf/2505.12082
模型合并:从「后训练」到「预训练」的跨越
后训练合并:任务能力的「拼图游戏」
模型合并并非全新概念,此前主要应用于后训练阶段,即通过合并多个领域微调模型的权重,构建一个多任务能力更强的统一模型。例如,DARE 方法将 WizardLM(通用对话模型)与 WizardMath(数学推理模型)合并后,在 GSM8K 数学推理基准上的得分从 2.2 跃升至 66.3,展现了任务能力融合的强大潜力。
相比之下,预训练阶段的模型合并研究仍较为匮乏。此类预训练合并通常涉及合并单一训练轨迹中的检查点,如 LAWA 中通过模型合并加速 LLM 训练的探索。然而,随着模型规模和数据量的急剧增长,社区研究者难以评估模型合并对大规模模型的影响,主要原因在于难以获取大规模预训练过程中的中间检查点。尽管 DeepSeek 和 LLaMA 均表明其在模型开发中使用了模型合并技术,但这些技术的详细信息尚未公开披露。
预训练合并:训练效率的「时光机」
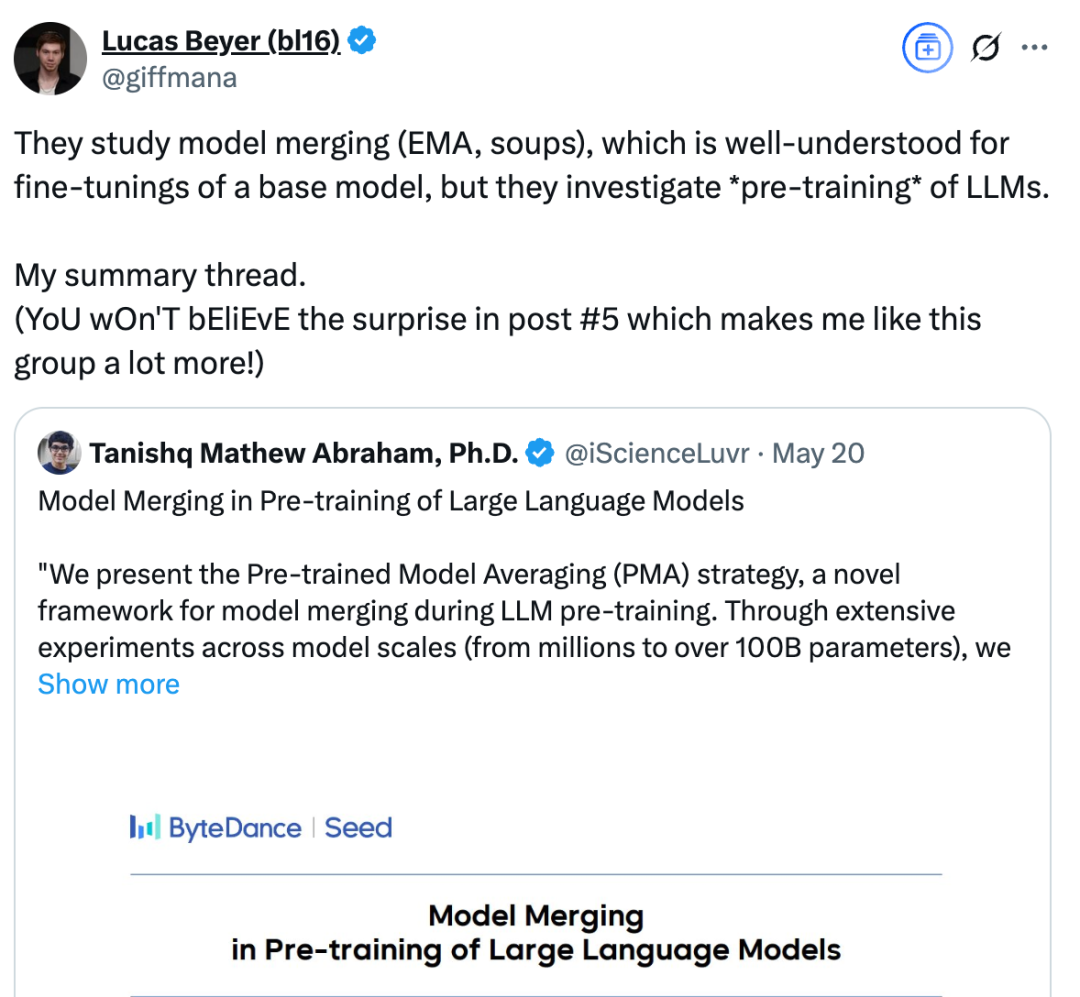
字节跳动的研究将模型合并引入预训练阶段,提出了Pre-trained Model Averaging(PMA)框架。简单来说,PMA 就是在预训练过程中,定期将不同训练阶段的模型权重进行平均,生成一个「合并模型」。这是因为:预训练后期的模型权重往往在参数空间中探索了不同的局部最优解,通过平均化可以抵消单个模型的偏差,逼近更优的全局解。例如,在稳定训练阶段(Constant LR Phase)合并 10 个检查点后,Seed-MoE-10B/100B 模型在 HumanEval 代码生成任务上的得分从 54.3 提升至 61.6,涨幅超过 13%。
PMA 技术的三大核心发现
合并时机:稳定期合并效果最佳
研究团队通过实验发现,在学习率稳定阶段(Warmup-Stable-Decay 中的 Stable Phase)进行模型合并效果最佳。此时模型处于「高效学习期」,权重更新尚未进入衰减阶段,不同检查点之间的参数差异既能保证多样性,又不会因过度震荡导致合并后性能下降。
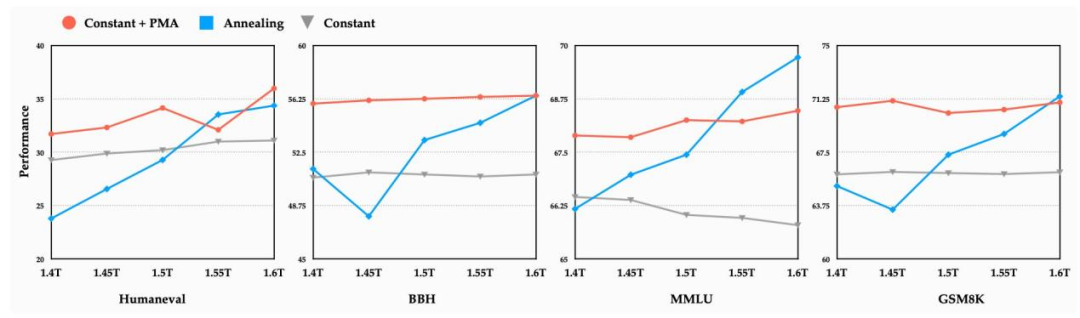
有趣的是,即使在学习率余弦衰减阶段(Cosine Decay Phase)的早期进行合并,PMA 模型的性能也能媲美甚至超越自然衰减到末期的模型。例如,Seed-MoE-15B/150B 模型在衰减初期合并后,其性能与训练至末期的模型相差无几。
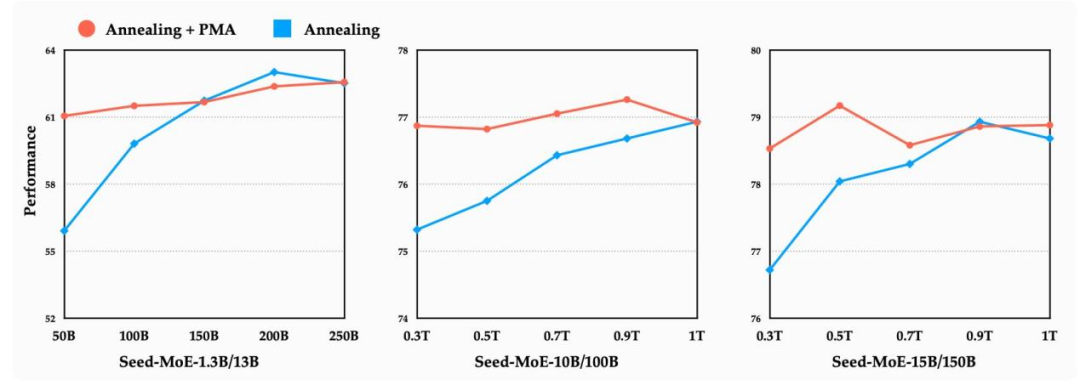
合并策略:简单平均(SMA)胜过复杂加权
在合并策略的对比实验中,研究团队测试了三种主流方法:
-
简单移动平均(SMA):所有模型权重等比例平均 -
指数移动平均(EMA):近期模型权重占比更高 -
加权移动平均(WMA):按训练步数线性加权
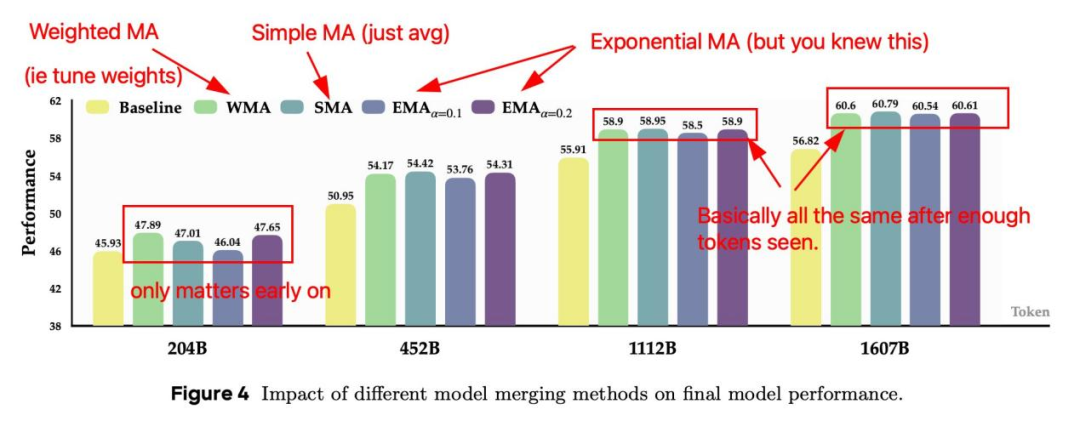
实验结果表明,在训练初期,EMA 和 WMA 因更关注近期权重而表现略好,但随着训练推进,三者性能差异逐渐消失。考虑到 SMA 的计算简单性和稳定性,团队最终选择其作为默认策略。这一发现打破了「复杂加权必然更优」的固有认知,为工程落地提供了便利。
超参数规律:模型规模决定合并间隔
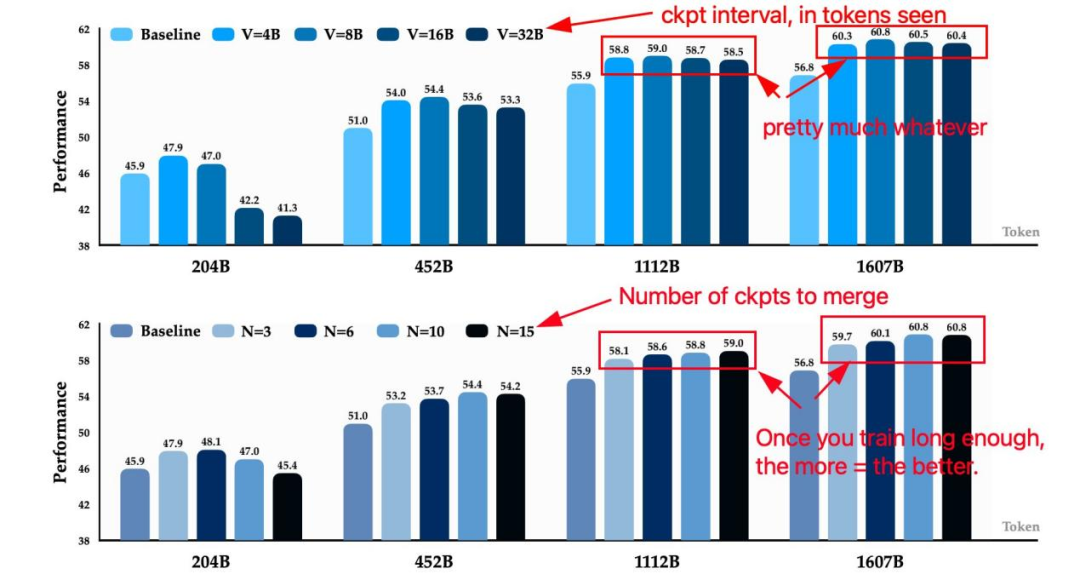
PMA 的「隐藏技能」:训练稳定性与初始化优化
PMA-init:让训练「起死回生」
在大模型训练中,「损失激增」(Loss Spike)是令人头疼的问题——硬件故障、参数震荡等因素可能导致训练崩溃,不得不从头再来。PMA 为此提供了一种「急救方案」:当损失激增发生时,合并故障前的 N 个检查点作为初始化权重(PMA-init),可使训练恢复稳定。
实验中,团队故意用过高的学习率(6e-3)训练一个 330M 参数的 MoE 模型,导致其损失剧烈震荡。此时采用 PMA-init 合并 3 个故障前检查点,训练曲线迅速恢复平滑,避免了从头训练的巨大浪费。
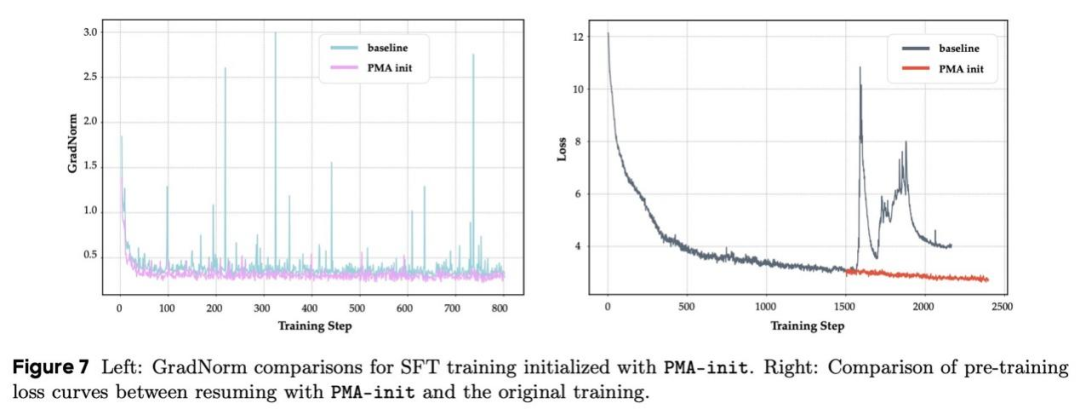
下游阶段的「热身优势」
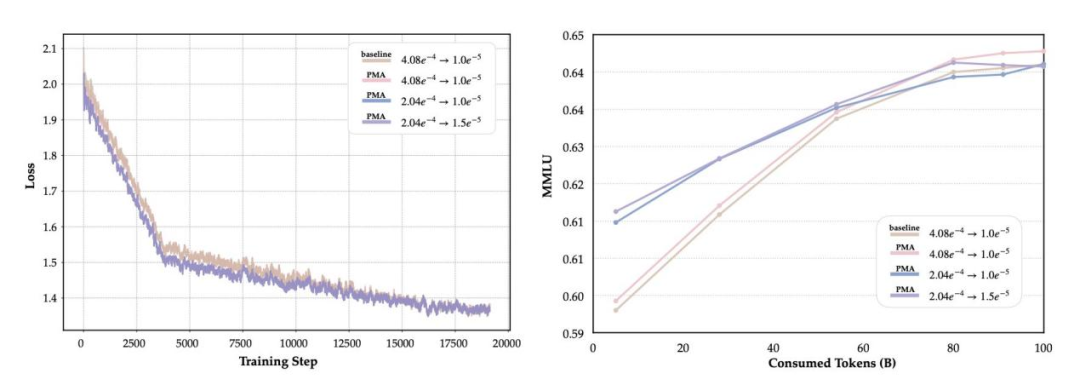
在持续训练(CT)和监督微调(SFT)阶段,使用 PMA 合并后的模型作为初始化权重(PMA-init),能显著改善训练动态。例如,在 CT 阶段,PMA-init 模型的 GradNorm 曲线更加平稳,早期训练中的 MMLU 得分比基线模型高 1-2 个百分点。尽管最终性能与基线持平,但其「热身优势」可加速下游任务的收敛,尤其适合数据敏感型场景。
数学原理:为什么合并能「化平凡为神奇」?
从理论层面看,模型合并的有效性可通过损失函数的二阶泰勒展开解释。假设最优参数为 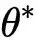 ,各检查点参数
,各检查点参数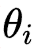 与 的偏差为
与 的偏差为 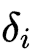 ,则合并后参数
,则合并后参数 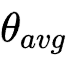 的损失可表示为:
的损失可表示为:
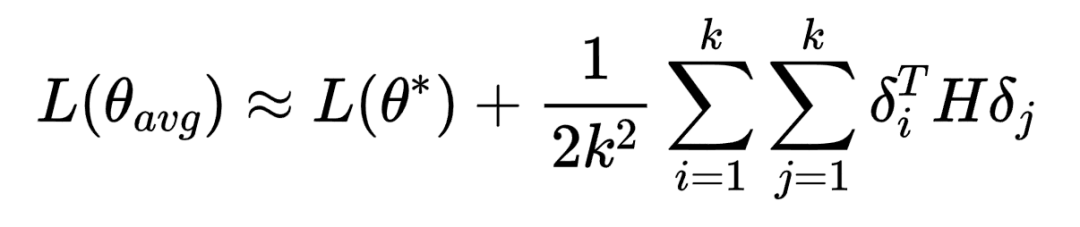
其中,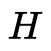 为海森矩阵(Hessian Matrix),刻画损失函数的曲率。当不同
为海森矩阵(Hessian Matrix),刻画损失函数的曲率。当不同 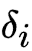 在参数空间中呈现「负相关」(即方向互补)时,交叉项
在参数空间中呈现「负相关」(即方向互补)时,交叉项 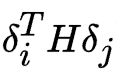 为负,使得合并后的损失低于单个模型的平均损失。这意味着,合并本质上是利用不同检查点在参数空间中的「探索多样性」,通过平均化抵消局部偏差,逼近更优解。
为负,使得合并后的损失低于单个模型的平均损失。这意味着,合并本质上是利用不同检查点在参数空间中的「探索多样性」,通过平均化抵消局部偏差,逼近更优解。
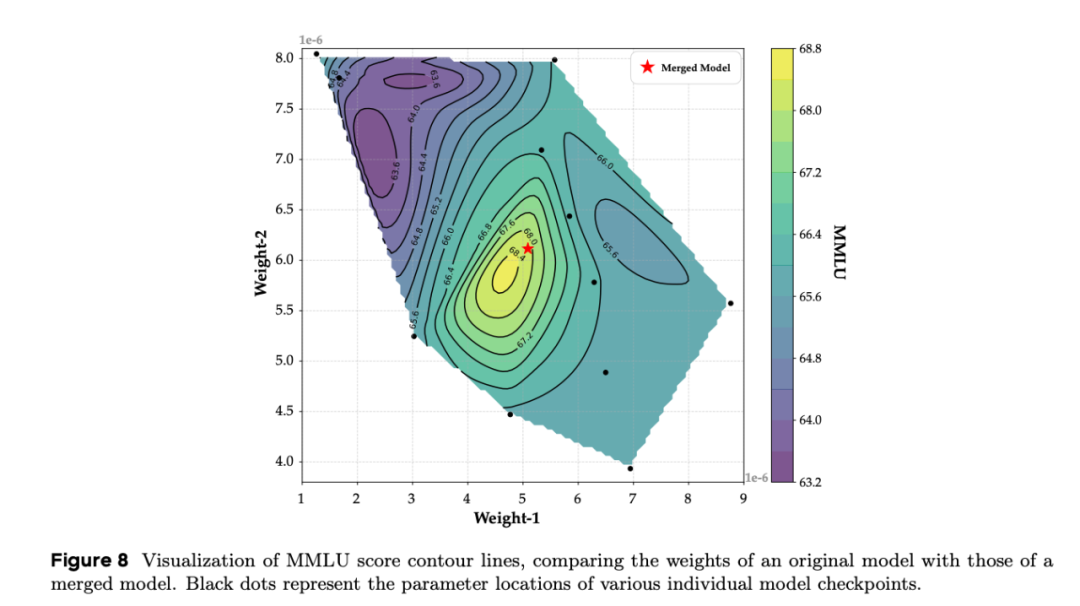
可视化实验也印证了这一点:在 Seed-MoE-1.3B/13B 模型的某层参数空间中,单个检查点的权重分布在 MMLU 得分等高线的不同位置,而合并后的权重位置往往更靠近高分区。
挑战与未来方向
未解决的问题
-
学习率的影响:当前实验默认使用缩放定律(Scaling Law)推荐的最优学习率,未深入探索高学习率下 PMA 的表现。理论上,高学习率可能增加参数探索的多样性,进一步提升合并效果,但受限于算力成本,尚未量化分析。
-
强化学习阶段的应用:论文主要聚焦预训练,而 RLHF(强化学习从人类反馈中学习)作为大模型训练的关键环节,其检查点合并的潜力尚未挖掘。这将是未来研究的重要方向。
行业启示
对于大模型开发者而言,PMA 带来的不仅是成本节省,更是一种「模拟退火」的思维革命——通过合并稳定期的检查点,可快速预测衰减阶段的性能,避免盲目延长训练周期。对于中小型企业,这意味着用更少的资源实现 comparable 性能,甚至可能颠覆「大公司垄断算力」的格局。
结语:开启高效训练的新时代
从「暴力堆算力」到「智能优化训练流程」,大模型的发展正从粗放式增长转向精细化运营。字节跳动的这项研究,以模型合并为切入点,揭示了预训练过程中被忽视的「检查点价值」,为学术界和工业界提供了一条低成本、高效能的新路径。
正如论文结语所言:「PMA 不仅是一种技术,更是一个监视器——它让预训练过程变得可预测、可优化。」随着更多类似研究的涌现,我们有理由相信,大模型训练将逐步摆脱「烧钱游戏」的标签,走向更可持续、更普惠的未来。

©
(文:机器之心)